校园云盘硬件搭建,及建设之超融合技术
Posted yuwangyunpan
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了校园云盘硬件搭建,及建设之超融合技术相关的知识,希望对你有一定的参考价值。
目前,在私有云建设(很多可能并不是真正的私有云,也包括一些虚拟化平台的建设)中,超融合出现的身影越来越多,本文
我们探讨下超融合技术。
一 什么是超融合
既然在说超融合架构,那就肯定有一般的融合架构,这其实也是目前行业内对于超融合定义争论的焦点,也就是说哪些定义为
融合架构,哪些定义为超融合架构。
个人来说比较倾向于以下定义:天然地(Natively)将两个或多个组件组合到一个独立的单元中,这句话的关键词是天然地
(Natively)。这种定义有个好处就是留了很多自由解释的空间,没有把这个边界框得太死。
至于其他的解释,个人觉得太具体化了,太具体的东西就容易引发争议。其实和很多IT领域里面的技术名称一样,我们不一定
要追求一个所谓的标准定义,可能起名称的人本来就没考虑这么多。
二 超融合的出现
2.1 性能需求
传统架构的业务系统在运行一段时间后,经常会遇到业务系统变慢,特别是在业务高峰期表现非常明显,比如月底月初的财务
系统。
那在大多数的案例中,问题往往出现在存储阵列上面,特别是虚拟化普及后,这种情况表现得更加明显。这主要是在阵列使用
一段时间后,随着磁盘等部件的老化,磁盘阵列的性能会存在一定的性能下降;同时,业务系统的运行也存在着使用范围越来越广,
用户越来越多,特别是虚拟化平台上虚拟机越开越多的情况。
那传统的解决方案,往往是更换性能更高的存储设备,特别是SSD盘的价格下调在一定程度上解决了阵列磁盘的读写问题,但
是,这时网络和阵列控制器往往成为了新的瓶颈。
在网络方面,以Intel S3700系列固态硬盘为例,其读写速度分别可达500MB/s和460MB/s,那不同的网络带宽能满足对应的SSD
盘理论读写速度如下:
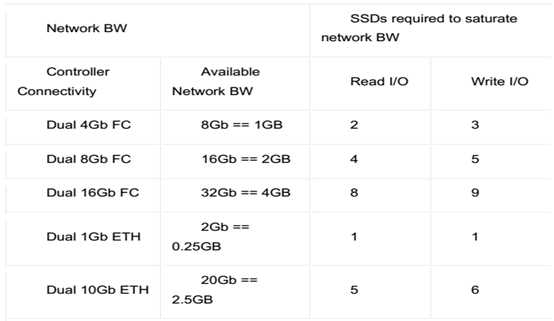
就算是理论上支持40Gb的交换速度的IB交换机的出现,依然不能满足大规模固态盘使用的速度要求。
在存储控制器方面:SSD对存储架构的影响是巨大的,传统机械硬盘的4K随机性能只有300左右,而类似intel 3700这样的
SSD则可以达到超过7.5万IOPS。双控制器架构在闪存架构中会成为瓶颈,比如EMC的Unity 650 可以支持一千块硬盘或SSD,
但31块SSD的时候就到达瓶颈。
2.2 技术的成熟
(1)分布式存储架构
分布式存储在亚马逊、谷歌等大型公有云得到了很好的应用,它基于X86服务器构建一个易扩展、高可靠的存储资源池,这是
超融合的基础。
(2)SSD盘的广泛使用
SSD的出现,解决了超融合架构中冷热数据分层的问题,也使得数据的访问速度相对比阵列访问有了质的提高,下面是特定
I/O类型的不同延迟特性:
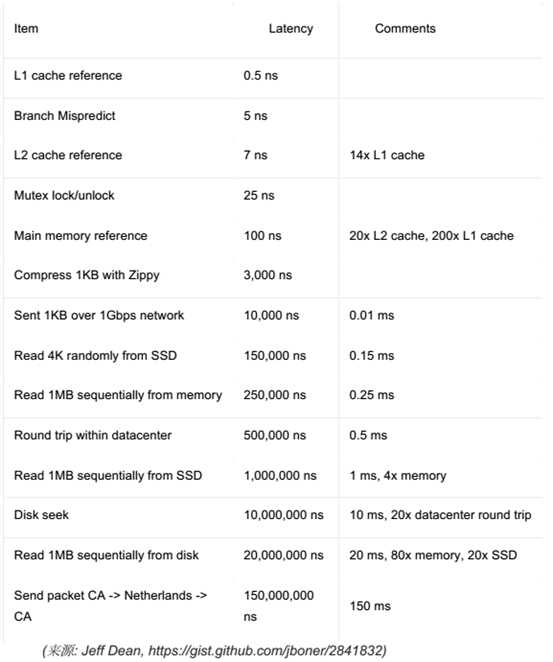
(3)CPU、网络
CPU长期以来基本遵循了摩尔定律的发展,更加强大廉价的CPU能在同时满足计算和存储需求。同时,万兆网络的普及解决了
不同服务器之间的数据横向快速流动的要求。
2.3 超融合的技术路线
超融合这个概念太热,以至于除了我们所熟知Nutanix、VMware等厂商外,大部分的传统硬件厂商都推出了自己超融合产品,
比如HP、DELL、华为、华三……,也有一些新晋玩家像深信服、SmartX等。
但这些厂商所走的超融合路线也有很大不同。
按照融合的程度,大致分为两大类:
以Nutanix、VMware为代表的厂商,强调尽量利用服务器本地资源来满足虚拟机的计算、存储需求,计算资源、存储资源没有
在硬件层做硬性的划分,他强调的是计算资源池、存储资源池的概念,在超融合的底层让虚拟化优先使用本地的存储资源。
另外一个技术路线的厂商大多借鉴Oracle数据库一体机的实现方式,将X86服务器划分为计算节点和存储节点,服务器之间采
用IB交换机相连,这和传统的集中式存储在逻辑架构上是一致的,区别只是用分布式存储取代了磁盘阵列。
在小型规模的应用上,以上两种路线的区别不大,但在规模应用之后,第二种实现方式的网络瓶颈就可能会显现。本文介绍的
超融合技术,将以第一种为参照。
三 超融合的架构
由于Nutanix在超融合领域的地位,其他超融合厂商在技术实现或多或少的借鉴了Natanix,该部分主要借鉴Nutanix超融合技术
方案让大家了解下具体的超融合技术实现,以避免相关内容流于概念和表面。
在Nutanix的架构中,大致可分为两大块,Prism和Acropolis。简单的说就是一个是管理模块(给管理人员用的),一个资源管
理模块(如何去调度底层资源)。
3.1 Prism
Prism是一个分布式的资源管理平台,允许用户跨集群环境管理和监控对象及服务。
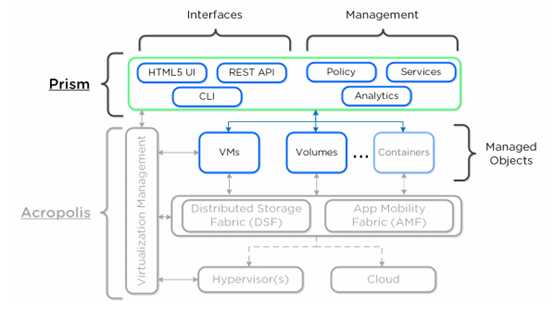
这部分内容不难理解,这里不做太多介绍,感兴趣的朋友可以自己去查阅相关文档。
3.2 Acropolis
Acropolis 是一个分布式的多资源管理器,集协同管理和数据平台功能于一身。它可以被细分为如下三个主要组件:
? 分布式存储架构 (DSF)
o 这是Nutanix 核心的赖以生存的组件,其基于分布式文件系统(HDFS)扩展而来。
? 应用移动性架构 (AMF)
o 类似于 Hypervisor 把操作系统从硬件剥离而来,AMF 把工作负载(虚机、存储和容器等)从 Hypervisor 抽象剥离开。这使
能在不同的Hypervisor 之间切换和移动工作负载。
? 虚拟化管理器(AHV)
o 一个基于 CentOS KVM hypervisor 的多用途虚拟化管理器组件。
下图以概要的方式展示了 Acropolis 不同层次的结构和关系:
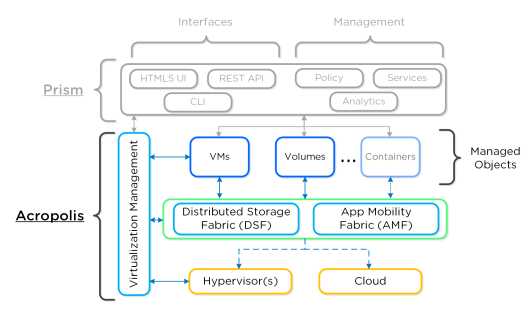
3.2.1 融合平台
Nutanix 解决方案是一个融合了存储和计算资源于一体的解决方案。它利用本地资源/组件来为虚拟化构建一个分布式的平台,
亦称作虚拟计算平台。
每个节点运行业界标准的 hypervisor(ESXi, KVM, Hyper-V)和 Nutanix 控制器虚机(CVM)。Nutanix CVM 中运行着
Nutanix 核心软件,服务于所有虚机和虚机对应的 I/O 操作。得益于Intel VT-d(VM直接通路)技术,对于运行着VMware vSphere
的 Nutanix 单元,SCSI 控制(管理 SSD 和 HDD 设备)被直接传递到CVM。 下图解释了典型的节点逻辑架构:
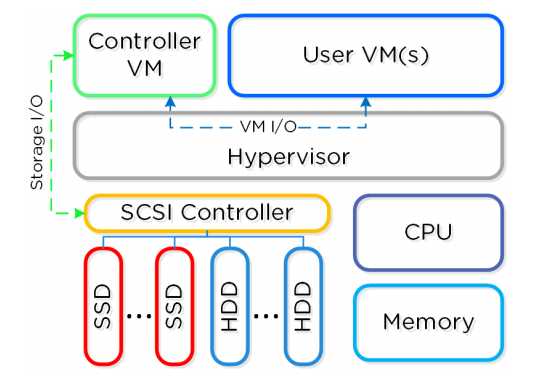
3.2.2 集群组件
Nutanix 平台由下列宏观组件构成:
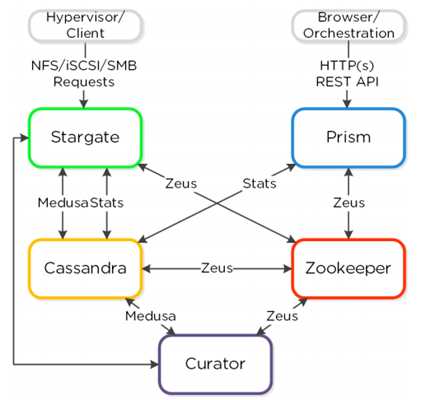
Cassandra
? 关键角色: 分布式元数据存储
?描述:Cassandra 基于重度修改过的 Apache Cassandra,以分布式环的方式存放 和管理所有的集群元数据。Paxos 算法被
用来保证严密的一致性。在集群中所有 节点上都运 行着这个服务。Cassandra 通过一个叫做 Medusa 的协议来访问。
Zookeeper
? 关键角色: 集群配置管理
? 描述:基于 Apache Zookeeper 实现,Zookeeper 存放了所有的集群配置信息,包 括主机、IP 地址和状态等。集群中有三
个节点会运行此服务,其中的一个被选举 成 leader。Leader 接收所有请求并转发到它的组员。一旦 leader 失去了反应,新
的leader 会被自动选举出来。Zookeeper 通过称作 Zeus 的接口来访问。
Stargate
? 关键角色: 数据 I/O 管理
? 描述:Stargate负责所有的数据管理和 I/O 操作,是 hypervisor 主要的接口(通过 NFS、iSCSI 或 SMB)。为了供本地 I/O
操作的能力,集群中所有节点都运行此服务。
Curator
? 关键角色:以 Mapreduce 方式管理和清理集群
?描述:Curator 负责在整个集群间分配和调度任务,诸如磁盘容量平衡、预清理等 。
Prism
? 关键角色:用户界面和 API
?描述:Prism 是一个组件管理网关,它让管理员能配置和监控 Nutanix 集群。它提供多种管理手段,如 Ncli、html5 UI 和
REST API。Prism运行在集群中的每个节点,如同集群中其他组件一样也采用 leader 选举制。
Genesis
? 关键角色:集群组件和服务管理
?描述:Genesis 是一个负责配置初始化和服务交互的进程,运行在每个节点上。 Genesis 不依赖于集群,即不管集群是否配
置或运行与否,它都运行着。它唯一的前提是 Zookeeper 必须起来并运行着。
Chronos
? 关键角色:任务调度
? 描述:Chronos 负责把由 Curator 扫?产生的任务在节点间调度执行并合理分配。 Chronos 运行在每个节点上,受控于主
Chronos(负责任务委托且和主 Curator 运行在同一节点)。
Cerebro
? 关键角色:数据复制和容灾管理
? 描述:Cerebro 负责 DSF 中的数据复制和容灾管理部分,包含快照的调度、远程 站点的数据同步及站点的迁移和故障切换。
Cerebro 运行在 Nutanix 集群的每个节 点上,并且每个节点都参与远程站点/集群的数据同步。
Pithos
? 关键角色:vDisk 配置管理
? 描述:Pithos 负责 vDisk(DSF 文件)的配置数据。Pithos 构建于 Cassandra 之 上,并运行在每个节点。
四 分布式关键技术和概念
4.1 节点架构
在ESXi的部署中,控制器虚拟机(CVM)硬盘使用的 VMDirectPath I/O 方 式。这使得完整的PCI控制器(和附加设备)通过
直通方式连接 CVM并绕过虚拟化层。 这种设计让其超融合技术和虚拟化软件实现了解耦。
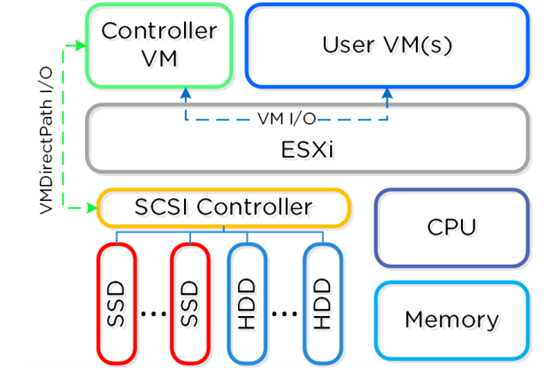
4.2 存储池
一个存储池是一组物理存储设备,大部分情况下,单个集群配置一个存储池。
4.3 容器
容器(container)从逻辑上划分存储池,并包含一组虚拟机或者文件(即虚拟磁盘)。很多人可能不理解为什么Nutanix要提
出容器的概念,其实它是为了数据存储的灵活性,比如,在一个集群内,不同的虚拟化对应的应用数据可能重要性不同,需要的副
本数也不同,这时,就需要采用不同的容器,进行不同的设定。所以在实际使用了,我们经常将对存储需求类似的虚拟机(含数据)
划分到同一个容器内,这不仅要考虑当前状态,还有今后可能的变动。
4.4 KVM架构
KVM 中包含以下主要组成:
KVM-kmod : KVM 内核
Libvirtd: API 接口,针对 KVM 和 QEMU 的监控、管理工具。 Acropolis 通过 libvirtd 与 KVM/QEMU 进行通讯。
Qemu-kvm : 一个“模拟器”(machine emulator),使得各个虚拟机能够独立运行。 Acropolis 通过它来实现硬件的虚拟化,
并使得 VM 以 HVM 的形式运行。
以下是各个组成的逻辑示意图:
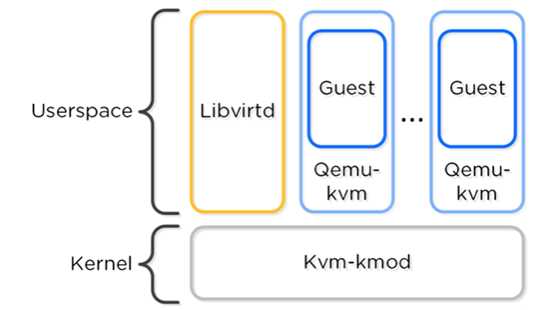
处理器兼容性
类似于 Vmware 的 Enhanced vMotion Capability(EVC),它允许 VM 在不 同代次的处理器间进行迁移。Acropolis 将检测
群集中代次最老的处理器,并把 所有的 QEMU 限定在此级别上。这样就可以允许不同代次的处理器进行混 用,并确保主机之间可
以实现 VM 的在线迁移。
4.5 Nutanix的复制因子和冗余因子
Nutanix的冗余因子在集群创建的时候就需要设置,并且后期不能改变,它确定了集群能同时坏掉多少台物理服务器而不影响集
群的正常运行,而复制因子是针对容器的(一个集群一般包含多个容器),它表示了数据在容器的副本份数。应该来说,冗余因子从
物理上保证了复制因子的实现,所以,复制因子不能大于冗余因子,只能小于等于。
4.6 VM High Availability (HA)
Acropolis 的 VM HA 可以确保当主机或 Block 掉电时,VM 的持续运行。当某个主机宕机时,VM 将在集群中某个健康节点中重
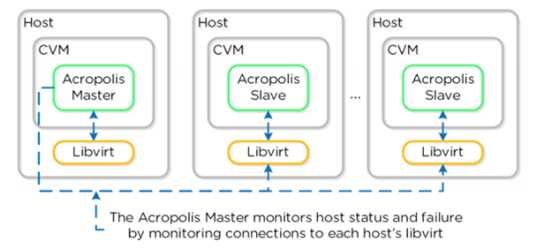
新启动。其中,Acropolis Master 负责该 VM 的重启操作。
Acropolis Master 通过 Libvirt 监测节点的健康状况:
五 超融合适用用户
超融合适合所有用户吗,这个回答见仁见智?不过个人认为,以下情况的客户可以优先考虑超融合:
1、如果在今后一段时间内,业务可能有较大增长;
2、对系统对IO性能有较高要求;
3、技术实力较强,想要对自身信息化架构充分掌控;
但如果没有自己的技术力量,又非常看重硬件平台的稳定性,对任何硬件故障有一定程度“恐惧”的客户建议可以再等等。
六 结论
在未来几年,可以确信“超融合”架构,以其强大的性能、部署灵活性、使用方便性等多方面优势,将成为主流的IT架构之一
以上是关于校园云盘硬件搭建,及建设之超融合技术的主要内容,如果未能解决你的问题,请参考以下文章
UGeek大咖说 | 直播回顾:可观测之超融合存储系统的应用与设计