《新浪微博自动评论软件·设计与实现之关键字搜索篇》
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了《新浪微博自动评论软件·设计与实现之关键字搜索篇》相关的知识,希望对你有一定的参考价值。
任务:进行关键字搜索,对结果批量评论
-
通过GET请求来获取搜索页面,其url:http://s.weibo.com/weibo/keyword&Refer=STopic_box。其中keyword为搜索关键字。
-
利用Python的RegEx解析网页,获取每条微博的mid。
- 手动对一条微博发送评论,抓取其数据包,分析其中各个参数及其作用以便在程序中对其进行更改模拟,其中包括但不限于Cookie字段以及POST参数mid、content。
-
利用Python编写程序模拟3中的情况重新提交POST请求,以达到对搜索结果中的微博的评论目的。
1、抓包分析
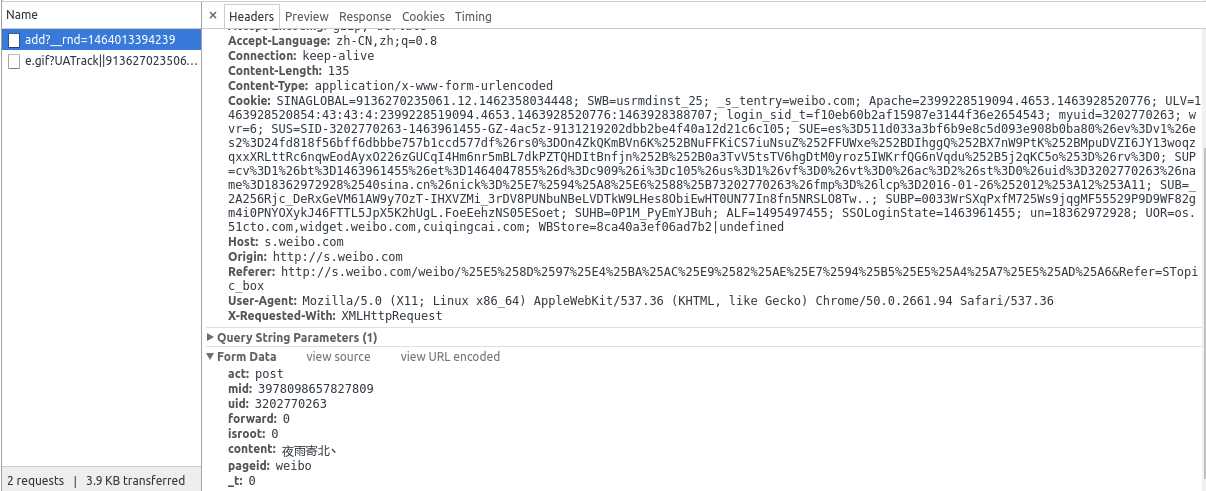
我们可能需要的数据如下:
General
Request URL:http://s.weibo.com/ajax/comment/add?__rnd=1464013394239
Request Headers Host:s.weibo.com Origin:http://s.weibo.com Referer:http://s.weibo.com/weibo/%25E5%258D%2597%25E4%25BA%25AC%25E9%2582%25AE%25E7%2594%25B5%25E5%25A4%25A7%25E5%25AD%25A6&Refer=STopic_box User-Agent:Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (Khtml, like Gecko) Chrome/50.0.2661.94 Safari/537.36
Form Data act:post mid:3978098657827809 uid:3202770263 forward:0 isroot:0 content:夜雨寄北丶 pageid:weibo _t:0
其中,黑体字表示该数据为固定数据,即可以在代码中写死,红体字表示该数据每次请求都不相同,需要更新,mid表示微博的id号,是微博的唯一标识。那么,怎么获得mid呢?
2、获取mid
我们来到热门微博的页面,使用chrome的开发者工具,看到:
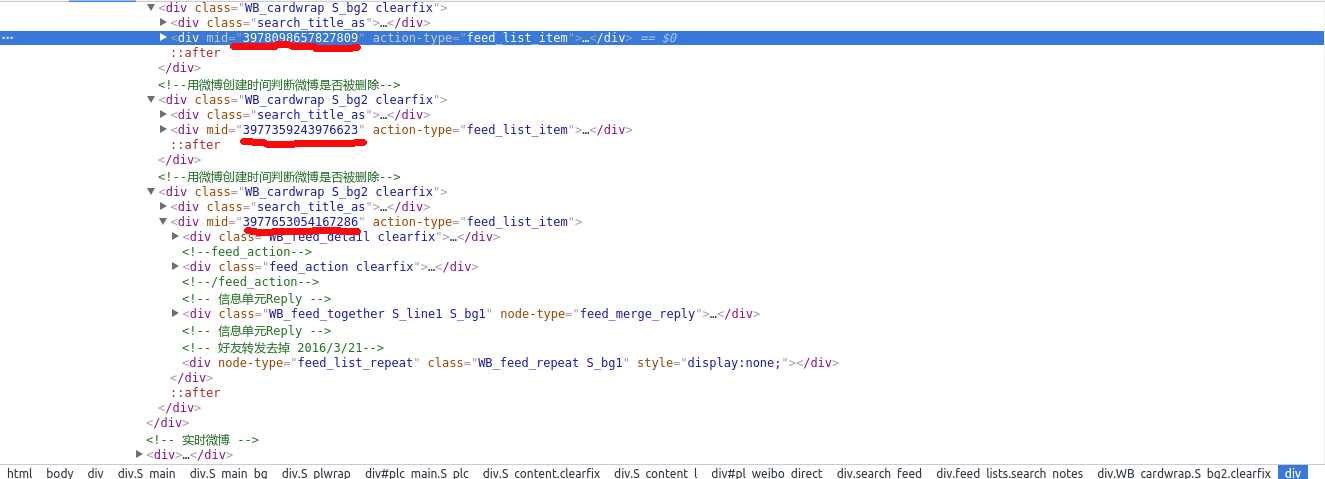
其中,划红线的地方就是mid了,每个<div class="WB_cardwrap S_bg2 clearfix">标签代表一条微博,可以看到,每个div对应的mid是唯一的。下面,我们就要用正则来提取mid,查看网页源代码:

我们发现,源代码里mid重复了多次,用正则去提取出最容易匹配的(即上图第2个划红线的):
pa = re.compile(‘mid=\\\\\\\\"(.*?)\\\\\\\\"‘, re.S) kw_mid = re.findall(pa, kw_html)
正则pa是不是很奇怪?!要注意:假如你需要匹配文本中的字符”\\”,那么使用编程语言表示的正则表达式里将需要4个反斜杠”\\\\\\\\”:前两个和后两个分别用于在编程语言里转义成反斜杠,转换成两个反斜杠后再在正则表达式里转义成一个反斜杠。
到此,我们获得了mid。
3、模拟评论
批量评论,顾名思义,就是对当前页面的关键字搜索到的微博成批地发送评论。因实验环境,取热门微博的前5条:
kw_mid_top5 = kw_mid[0:5]
post表单:
session.post(request_url,data=kw_form_data,headers=kw_headers) time.sleep(3) #避免请求频繁被限制
4、小结
很重要的一条,每次请求一定要带上headers,不然有可能骗不了服务器!!
好啦!
到目前为止,我们已经成功模拟批量评论关键字微博啦!
完整代码如下,欢迎参考!!
(●‘?‘●)?♥~~~
1 #!/usr/bin/env python 2 # -*- coding:utf-8 -*- 3 __author__ = ‘ziv·chan‘ 4 __blog__ = ‘http://www.cnblogs.com/ziv-chan/‘ 5 6 7 import time 8 import base64 9 import rsa 10 import binascii 11 import requests 12 import re 13 import urllib 14 15 time1 = time.time() 16 17 # 构造 Request headers 18 agent = ‘Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/50.0.2661.94 Safari/537.36‘ 19 headers = { 20 ‘User-Agent‘: agent 21 } 22 23 session = requests.session() 24 25 def get_su(user_name): 26 username_ = urllib.quote(user_name) # html字符转义 27 username = base64.encodestring(username_)[:-1] 28 return username 29 30 # 预登陆获得 servertime, nonce, pubkey, rsakv 31 def get_sso_data(user_name): 32 prelogin_url = ‘http://login.sina.com.cn/sso/prelogin.php?entry=sso&callback=sinaSSOController.preloginCallBack&su=%s&rsakt=mod&client=ssologin.js(v1.4.18)‘ % user_name 33 sso_data = eval(session.get(prelogin_url).text.replace(‘sinaSSOController.preloginCallBack‘,‘‘)) 34 return sso_data 35 36 def get_sp(password, servertime, nonce, pubkey): 37 weibo_rsa_n = int(pubkey, 16) 38 key = rsa.PublicKey(weibo_rsa_n, 65537) #创建公钥 39 message = str(servertime) + ‘\\t‘ + str(nonce) + ‘\\n‘ + str(password) #拼接明文js加密文件中得到 40 passwd = rsa.encrypt(message, key) #加密 41 return binascii.b2a_hex(passwd) #将加密信息转换为16进制。 42 43 def login(username, password): 44 su = get_su(username) 45 sso_data = get_sso_data(su) 46 servertime = sso_data["servertime"] 47 nonce = sso_data[‘nonce‘] 48 rsakv = sso_data["rsakv"] 49 pubkey = sso_data["pubkey"] 50 sp = get_sp(password, servertime, nonce, pubkey) 51 52 form_data = { 53 ‘entry‘: ‘weibo‘, 54 ‘gateway‘: ‘1‘, 55 ‘from‘: ‘‘, 56 ‘savestate‘: ‘7‘, 57 ‘useticket‘: ‘1‘, 58 ‘pagerefer‘: ‘‘, 59 ‘vsnf‘: ‘1‘, 60 ‘su‘: su, 61 ‘service‘: ‘miniblog‘, 62 ‘servertime‘: servertime, 63 ‘nonce‘: nonce, 64 ‘pwencode‘: ‘rsa2‘, 65 ‘rsakv‘: rsakv, 66 ‘sp‘: sp, 67 ‘sr‘: ‘1366*768‘, 68 ‘encoding‘: ‘UTF-8‘, 69 ‘prelt‘: ‘‘, 70 ‘url‘: ‘http://weibo.com/ajaxlogin.php?framelogin=1&callback=parent.sinaSSOController.feedBackUrlCallBack‘, 71 ‘returntype‘: ‘META‘ 72 } 73 74 request_url = ‘http://login.sina.com.cn/sso/login.php?client=ssologin.js(v1.4.18)‘ 75 login_page = session.post(request_url, data=form_data, headers=headers) 76 # login_page.encoding = ‘gbk‘ 77 load_page = login_page.text 78 79 pattern = re.compile(‘location\\.replace\\([\\‘"](.*?)[\\‘"]\\)‘, re.S) 80 load_url = re.findall(pattern, load_page)[0] 81 82 login_index = session.get(load_url, headers=headers) 83 uid_pattern = re.compile(‘"uniqueid":"(.*?)"‘,re.S) 84 uid = re.findall(uid_pattern, login_index.text)[0] #获得用户uid 85 86 home_page_url = "http://weibo.com/%s/profile?topnav=1&wvr=6&is_all=1" % uid 87 home_page = session.get(home_page_url, headers=headers) 88 home_page_pattern = re.compile(‘<title>(.*?)</title>‘,re.S) 89 user_id = re.findall(home_page_pattern, home_page.text)[0] 90 print u"欢迎%s,登录成功!" % user_id 91 92 def edit_hot_comment(content): 93 request_url = ‘http://d.weibo.com/aj/v6/comment/add?ajwvr=6&__rnd=‘ + str(int(time.time()*1000)) 94 hot_url = ‘http://d.weibo.com/102803#‘ 95 hot_html = session.get(hot_url, headers=headers).text 96 pa = re.compile(‘mid=\\\\\\\\"(.*?)\\\\\\\\"‘, re.S) 97 hot_mid = re.findall(pa, hot_html) 98 hot_mid_top5 = hot_mid[0:5] 99 hot_headers = { 100 ‘Host‘ : ‘d.weibo.com‘, 101 ‘Origin‘ : ‘http://d.weibo.com‘, 102 ‘Referer‘ : ‘http://d.weibo.com/102803‘, 103 ‘User-Agent‘ : agent 104 } 105 for i in range(0,5): 106 hot_form_data = { 107 ‘act‘ : ‘post‘, 108 ‘mid‘ : hot_mid_top5[i], 109 ‘uid‘ : ‘3202770263‘, 110 ‘forward‘ : ‘0‘, 111 ‘isroot‘ : ‘0‘, 112 ‘content‘ : content, 113 ‘location‘ : ‘page_102803_home‘, 114 ‘module‘ : ‘scommlist‘, 115 ‘group_source‘ : ‘‘, 116 ‘tranandcomm‘ : ‘1‘, 117 ‘filter_actionlog‘ : ‘102803_ctg1_99991_-_ctg1_99991‘, 118 ‘pdetail‘ : ‘102803‘, 119 ‘_t‘ : ‘0‘ 120 } 121 # print hot_mid_top5[i] 122 session.post(request_url,data=hot_form_data,headers=hot_headers) 123 time.sleep(3) #避免请求频繁被限制 124 print u‘热门批量评论成功!‘ 125 126 def edit_kw_comment(key_word,content): 127 request_url = ‘http://s.weibo.com/ajax/comment/add?__rnd=‘ + str(int(time.time()*1000)) 128 keyword = urllib.quote(key_word) 129 kw_url = ‘http://s.weibo.com/weibo/%s&Refer=STopic_box‘ % keyword 130 kw_html = session.get(kw_url,headers=headers).text 131 pa = re.compile(‘mid=\\\\\\\\"(.*?)\\\\\\\\"‘, re.S) 132 kw_mid = re.findall(pa, kw_html) 133 kw_mid_top5 = kw_mid[0:5] 134 kw_headers = { 135 ‘Host‘ : ‘s.weibo.com‘, 136 ‘Origin‘ : ‘http://s.weibo.com‘, 137 ‘Referer‘ : kw_url, 138 ‘User-Agent‘ : agent 139 } 140 for i in range(0,5): 141 kw_form_data = { 142 ‘act‘ : ‘post‘, 143 ‘mid‘ : kw_mid_top5[i], 144 ‘uid‘ : ‘3202770263‘, 145 ‘forward‘ : ‘0‘, 146 ‘isroot‘ : ‘0‘, 147 ‘content‘ : content, 148 ‘pageid‘ : ‘weibo‘, 149 ‘_t‘ : ‘0‘ 150 } 151 # print kw_mid_top5[i] 152 session.post(request_url,data=kw_form_data,headers=kw_headers) 153 time.sleep(3) #避免请求频繁被限制 154 155 print u‘关键词批量评论成功!‘ 156 157 158 if __name__ == "__main__": 159 username = ‘18362972928‘ 160 password = ‘ChelseaFC.1‘ 161 login(username, password) 162 # edit_hot_comment(raw_input(u‘输入评论:‘)) 163 edit_kw_comment(‘南京邮电大学‘,‘夜雨寄北~‘) 164 165 time2 = time.time() 166 167 print ‘程序耗时:‘ + str(time2 - time1) + ‘秒‘
转载请注明:夜雨寄北丶 » 《新浪微博自动评论软件·设计与实现之热门评论篇》
以上是关于《新浪微博自动评论软件·设计与实现之关键字搜索篇》的主要内容,如果未能解决你的问题,请参考以下文章