HBase 高可用性
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了HBase 高可用性相关的知识,希望对你有一定的参考价值。
1、Replication 之 Master <--> Master 互备
Master1 (所用zookeeper所处节点NM-304-SA5212M4-BIGDATA-1[01-05] ):
-- add_peer ‘1‘,"NM-304-SA5212M4-BIGDATA-106,NM-304-SA5212M4-BIGDATA-107,NM-304-SA5212M4-BIGDATA-108,NM-304-SA5212M4-BIGDATA-109,NM-304-SA5212M4-BIGDATA-110:2181:/hbase"
-- create ‘test1‘,{NAME => ‘cf1‘,REPLICATION_SCOPE => ‘1‘}
-- put ‘test1‘,‘rowkey001‘,‘cf1:col1‘,‘value01‘
Master2 (所用zookeeper所处节点NM-304-SA5212M4-BIGDATA-1[06-10] ):
-- add_peer ‘1‘,"NM-304-SA5212M4-BIGDATA-101,NM-304-SA5212M4-BIGDATA-102,NM-304-SA5212M4-BIGDATA-103,NM-304-SA5212M4-BIGDATA-104,NM-304-SA5212M4-BIGDATA-105:2181:/hbase"
-- create ‘test1‘,{NAME => ‘cf1‘,REPLICATION_SCOPE => ‘1‘}
-- put ‘test1‘,‘rowkey002‘,‘cf1:col1‘,‘value02‘
[注]:如果使用同一zookeeper集群,那么hbase在zookeeper中应使用不同的znode
2、Replication 之 Master --> Slave
Master集群1(NM-304-SA5212M4-BIGDATA-101):
-- add_peer ‘1‘,"NM-304-SA5212M4-BIGDATA-106,NM-304-SA5212M4-BIGDATA-107,NM-304-SA5212M4-BIGDATA-108,NM-304-SA5212M4-BIGDATA-109,NM-304-SA5212M4-BIGDATA-110:2181:/hbase"
-- create ‘test1‘,{NAME => ‘cf1‘,REPLICATION_SCOPE => ‘1‘}
-- put ‘test1‘,‘rowkey001‘,‘cf1:col1‘,‘value01‘
Slave集群2(NM-304-SA5212M4-BIGDATA-106):
-- create ‘test1‘,{NAME => ‘cf1‘}
hbase org.apache.hadoop.hbase.mapreduce.replication.VerifyReplication --families=cf1 1 test_xbk
如果有多个families,以逗号分隔
3、CopyTable
执行命令前,需先创建表。
支持时间区间、row 区间,改变表名称,改变列簇名称,指定是否copy删除数据等功能。
A、同一个集群不同表名称
-- hbase org.apache.hadoop.hbase.mapreduce.CopyTable --new.name=tableCopy srcTable
B、跨集群 copy 表
-- hbase org.apache.hadoop.hbase.mapreduce.CopyTable --starttime=1453445763941 --endtime=1453445797041 --peer.adr=NM-304-SA5212M4-BIGDATA-106,NM-304-SA5212M4-BIGDATA-107,NM-304-SA5212M4-BIGDATA-108,NM-304-SA5212M4-BIGDATA-109,NM-304-SA5212M4-BIGDATA-110:2181:/hbase --peerId=1 --families=ct:ct --new.name=copytable copytable
MR 的 map 数量与表的 region 数相同,与 HFile 文件个数无关。
CopyTable 工具采用 scan 查询,写入新表时采用 put 和 delete API,全是基于 hbase 的 client api 进行读写,无法使用 Import 工具的 bulk 导入。
4、HBase Snapshots
对于 hbase 数据备份及数据复制来说,以往会采用 CopyTable 或 ExportTable 或在禁用 hbase 表后在HDFS中复制所用 hfiles 。
但 CopyTable 和 ExportTable 会降低 region server 的性能,禁用表代表着不能写也不能读。
HBase Snapshots 允许你克隆一个表没有创建数据副本,并且最小限度的影响 Region Servers 。导出表到另一个集群不应该对 Region Servers 产生影响。
在创建snapshot后,可以通过ExportSnapshot工具把快照导出到另外一个集群,实现数据备份或者数据迁移。
操作步骤:
A、创建快照: hbase snapshot -n xbk_snapshot -t xbk
或 hbase shell> snapshot ‘test1‘, ‘xj_snapshot‘
B、把快照导出到另外一个集群: hbase org.apache.hadoop.hbase.snapshot.ExportSnapshot -snapshot xj_snapshot -copy-to hdfs://NM-304-SA5212M4-BIGDATA-111:8020/hbase (-chuser MyUser -chgroup MyGroup -chmod 700 -mappers 16)
C、把快照copy成一个新的表: clone_snapshot ‘test_snapshot‘,‘testsnapshot‘
5、Export/Import
通过Export导出数据到目标集群的hdfs,再在目标集群执行import导入数据,Export支持指定开始时间和结束时间,因此可以做增量备份。
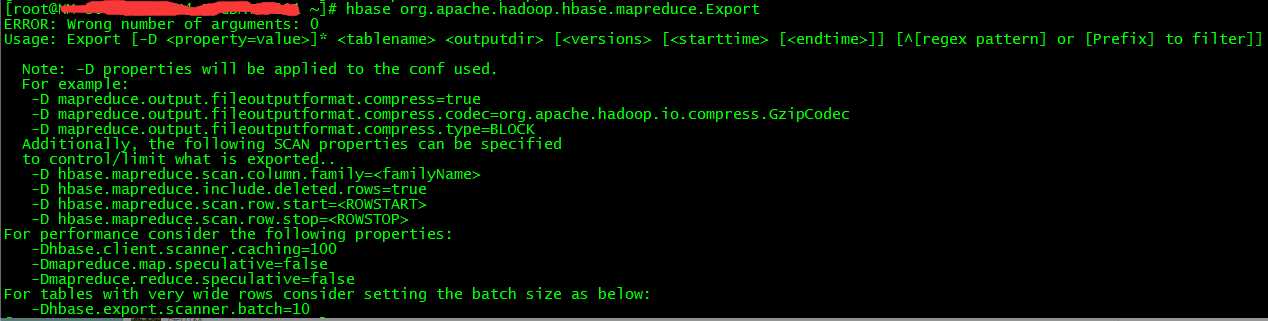
hbase org.apache.hadoop.hbase.mapreduce.Export
Export工具参数如下:

参考资料:
以上是关于HBase 高可用性的主要内容,如果未能解决你的问题,请参考以下文章
Linux企业运维——Hadoop大数据平台(下)hdfs高可用Yarn高可用hbase高可用