论文笔记之:Dynamic Label Propagation for Semi-supervised Multi-class Multi-label Classification ICCV 201
Posted The Blog of Xiao Wang
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了论文笔记之:Dynamic Label Propagation for Semi-supervised Multi-class Multi-label Classification ICCV 201相关的知识,希望对你有一定的参考价值。
Dynamic Label Propagation for Semi-supervised Multi-class Multi-label Classification
ICCV 2013
在基于Graph的半监督学习方法中,分类的精度高度依赖于可用的有标签数据 和 相似性度量的精度。此处,本文提出一种半监督的 multi-class and multi-label 分类机制,Dynamic Label Propagation(DLP),是在一个动态的过程中传递,执行 transductive learning。现有的半监督方法一般都很难处理多标签/多分类问题,因为缺乏考虑标签的关系;本文所提出的方法重点强调动态度量和标签信息的融合。
监督的度量学习方法经常学习马氏距离(Mahalanobis distance),努力缩小相同标签之间的距离,与此同时,尽可能保持或者拉大不同标签图像的距离。基于Graph的监督学习框架利用少量的有标签信息去挖掘大量的无标签数据的信息。Label Propagation 具体的认为在一个Graph中通过信息传递,有较大相似性的由边链接的点趋于拥有相同的标签。另外一种类型的办监督学习方法, 协同训练(Co-training),利用多视角特征来相互帮助,拉进无标签数据来重新训练并且增强分类器(by pulling out unlabeled data to re-train and enhance the classifiers)。
上述方法一般都是用来处理二分类问题,对于多分类/多标签问题,标签传递算法就有问题了,需要一些额外的操作。一种通用的处理多分类和多标签学习的方法是利用 one vs all 的策略。但是,不足之处是,不同类别之间的关系无法完全处理。有了类别之间的关系,分类的效果会明显提升。
本文中,我们提出了一种新的,DLP 来同时处理多标签/多分类问题。将标签关系 和 示例相似性 (label correlations and instance similarities)结合成一种新的执行标签传递的方式。The intuition in DLP 是通过融合多标签/多分类信息从而动态的更新相似性度量,可以在一个概率框架中进行理解。KNN矩阵 用来存贮输入数据的内在结构。
Review: Label Propagation
给定一个有限的加权图 G = (V, E, W), 该图的顶点为每一个样本,构成结合 X = {xi, i = 1...n},边E的集合为:V*V,非负的对称权重函数 W:E->[0, 1]。若样本 xi xj 之间有边相连,则认为 W(i,j)>0。我们将权重函数W(i, j)作为样本xi xj的相似性度量。如果定义在图上的度量矩阵为:
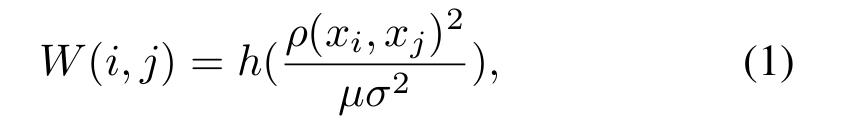
其中,h(x) = exp(-x),分母中的两个参数为超参数,/delta is learned by the mean distance to K-nearest neighborhoods(到K*邻的*均距离???此处不太理解)。
一个很自然的关于顶点V的转移矩阵可以定义为归一化权重矩阵:
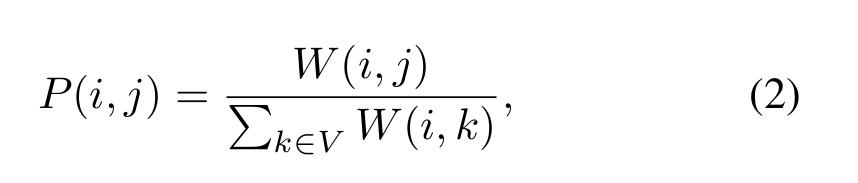
所以 Σj∈V P(i, j)=1。Note: P在归一化之后变为对称。
将数据集表为 X = {Xl U Xu}, Xl 表示有标签数据 Xu表示无标签数据。在标签传递的过程中,很重要的一环是:clamping,即:每次迭代后,都要将有标签数据的label重置,这是要排除干扰,因为这些有标签的数据并不需要propagation,所以只要有变动,就要重置回来。对于二分类的LP,作者建议读相关参考文献,对于多分类问题,1-of-C,所以标签矩阵是:Y = [Y(l), Y(u)];n 是数据点的个数,C是类别数。Y(l)是有标签数据的标签矩阵,Y(u)是无标签数据的标签矩阵。设置 Y(l)(i, k) = 1, 如果xi被标注为类别k,否则就是0.在迭代的过程中,迭代的执行两列两个步骤:
1. Labels are propagated Yt = P * Yt-1.
2. Labels of labeled data Xl are reset.
算法主要流程如下:

Dynamic Label Propagation
1. Local Similarity
给定 数据集 X 及其对应的Graph G = (V, E, W),我们构建 KNN graph g = (V,e,w):顶点V与G中一样,加权边只是*邻的一些。换句话说,非相邻点的相似性置为0. 我们假设:局部相似性 比远处的更可靠;对应的,局部相似性可以传递给非局部点 through a diffusion process(扩散处理) on the graph。这个假设被广泛的应用于其他的流型学习的算法。
用KNN来衡量局部密切关系(local affinity),我们构建和相似矩阵相联系的g:
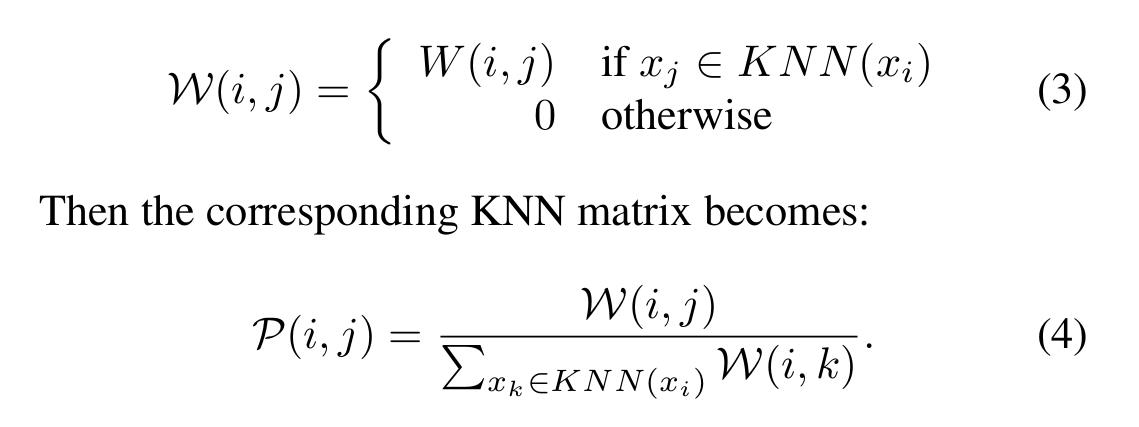
注意到,P 携带着全部的pair-wise 相似性信息,与此同时,p\' 仅仅编码了与*邻数据的相似性。但是 p\' 结合了输入数据空间鲁棒的结构信息。我们称呼 P 为状态矩阵,p\' 为对应的KNN矩阵。
2. Label Fusion on Diffusion Space
Label propagation的一个不足在于:因为没能考虑不同标签之间的相互作用,未能在多类和多标签分类问题。为了改善多类/多标签分类的效果,本文中提出了一种动态的标签传递方法(dynamic version of label propagation)。主要的idea 来自于通过融合每次迭代中的数据特征和数据标签的信息来改善transition matrix。
给定Kernel $P_t$,此处 $t$代表迭代的数目,第$t$次迭代的diffusion distance(扩散距离):
$D_t(i, j) = ||P_t(i, :) - P_t(j, :)||.$
扩散的过程将data映射到n维的空间,每一个数据点根据其转移概率转到其他的数据点之上。可以做出一个合理的假设,即:每一个数据点$x_t$,我们有:$p(x_t) = \\mathcal{N}(x_t|\\mu_t, P_t)$, 其中,$\\mu_t$ 是未知的。注意到,标签矩阵$Y_t$ 包含类别标签的信息,标签之间的关系 $K_Y = Y_tY_t^T$ 可以看做是标签空间中的数据点之间的相似性,标签空间中的数据点有概率 $p(y_t) = \\mathcal{N}(y_t|0, K_t)$。
我们的方法可以分成两个步骤:
1. Kernel Fusion。
2. Kernel Diffusion。
1. Kernel Fusion。
Dynamic label propagation 的第一部分是状态矩阵 $P_t$ 和 标签核(the label kernel) $K_Y = Y_tY_t^T$的融合。一个权重 $\\alpha$ 赋给label kernel $K_Y$,融合后的kernel是:
$F_t = (P_t + $\\alpha$ Y_tY_t^T).$
该操作对应于diffusion spaces的一个加法算子:
$p(z_t) = \\mathcal{N}(z_t|\\mu_t, P_t + $\\alpha$ Y_tY_t^T) = \\mathcal{N}(z_t|\\mu_t, F_t).$
这个简单的融合技术考虑了示例标签向量的关系。潜在的假设是:拥有高相关标签向量的instance,趋于在输入数据空间高度的相似性。标签向量之间的关系可以表示instance之间的标签依赖,特别对于多标签和多类问题。融合转移kernel和标签相关性的优势有如下两点:
一方面,拥有高度相关的标签向量的两个示例,在输入数据空间有更高的相似性,融合的过程从而就使得kernel matrix 更加适合输入流型。
另一方面,得到的kernel matrix 通过下一个回合的标签传递,可以得到更好的标签信息。
用这种方法,我们可以在特征空间和标签空间之间,建立起动态的相互联系的过程。然而,由于标签信息是随着传递过程动态更新的,经过初始的几个回合之后的结果标签信息就不在改善转移矩阵了,有时候甚至使之变坏了。为了解决这个问题,我们设计了一个新颖的基于局部*邻的融合操作。
2. Kernel Diffusion。
假设 $P_0$ 是利用公式(1)(2)得到的输入数据的初始状态矩阵,由公式(3)(4)得到 $\\mathcal{P} = KNN(P_0)$;我们利用线性操作符$\\mathcal{P}$ 来进行映射:
$x_{t+1} = \\mathcal{P} z_t + \\lambda_t \\varepsilon$
其中,$\\varepsilon$ 是白噪声(white noise),i.e. $p(\\varepsilon) = \\mathcal{N}(\\varepsilon|0, 1)$。注意到,$\\mathcal{P}$ 是 $P_0$ 的稀疏版本(sparse version),在$\\matchcal{P}$中,仅仅包含空间中的局部*邻信息:
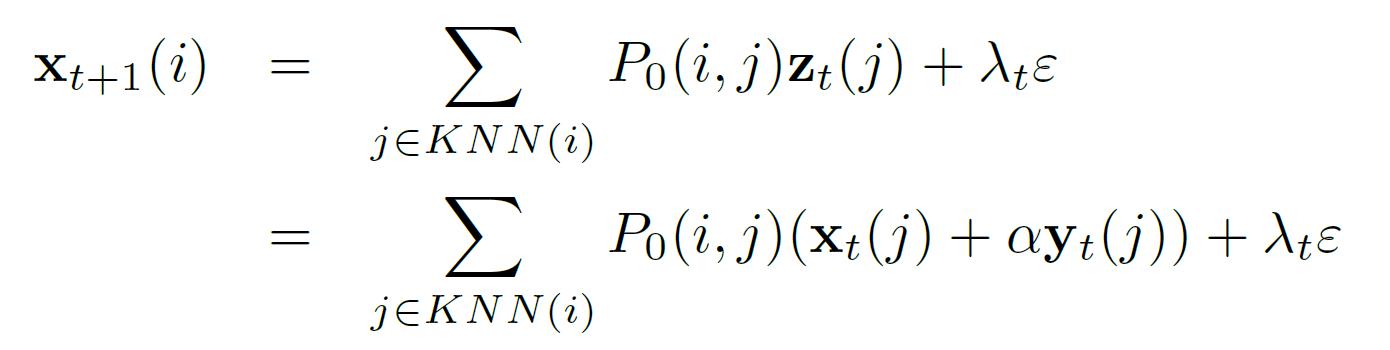
有此线性操作,我们可以得到:
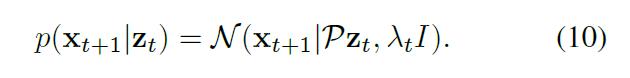
$x_{t+1}$ 的边缘分布是:
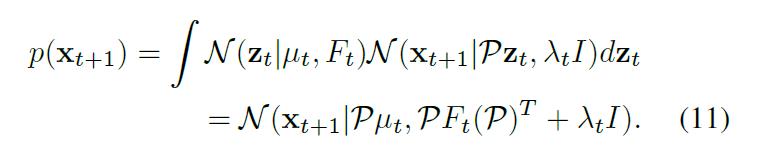
以上公式表明,dynamic label propagation 的精髓或者说是本质是:在扩散空间迭代的进行线性操作(do linear operations on diffusion space iteratively)。注意到,$x_{t+1}$ 是 diffusion space 中的一个点,我们将其映射到 diffusion space, 而不是原始的数据空间。该转换有两个优点:
1. 避免了输入空间计算代价昂贵的采样过程;
2. 得到的 variance matrix 是一个很好的 diffusion kernel,更好的进行 label propagation。
这种映射背后的直觉是:公式(6)中标签关系的简单融合,当学习到的无标签数据的标签信息精确度不足以区分输入空间的相似性的时候,就会导致第一个回合的性能降低。所以,我们需要通过 KNN matrix 再次强调输入数据之间的内部结果。通过这种方式,我们可以调整融合的 kernel matrix 来保留初始结构的部分信息。
在每次迭代,该映射的直接反应到 diffusion space 的是:我们构建下一次迭代的 transition matrix:
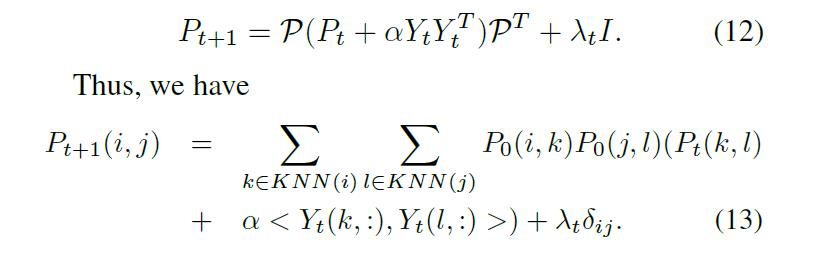
其中,内积 $<X_1, X_2>$ 代表两个向量的内积,并且 当 $i = j$ 时,$\\delta_{ij} = 1$,否则就为0。从公式(13)可以看出,仅仅主要的*邻才传播信息给下一个迭代的转移矩阵。一个很重要的现象是:当 data i, j 在各自的相似性矩阵中 拥有相同的 dominant neighbors,那么他们有很大的可能性是属于同一类的。
下面给出了 dynamic label propagation 的主要算法流程:

以上是关于论文笔记之:Dynamic Label Propagation for Semi-supervised Multi-class Multi-label Classification ICCV 201的主要内容,如果未能解决你的问题,请参考以下文章
论文阅读之Dynamic Routing Between Capsules(2017)
论文笔记:D-NeRF:Neural Radiance Fields for Dynamic Scenes
《WSVD:Web Stereo Video Supervision for Depth Prediction from Dynamic Scenes》论文笔记
论文笔记:Spatial-Temporal Map Vehicle Trajectory Detection Using Dynamic Mode Decomposition and Res-UNe
SC-DepthV3:Robust Self-supervised Monocular Depth Estimation for Dynamic Scenes——论文笔记
论文笔记:SEMI-SUPERVISED CLASSIFICATION WITH GRAPH CONVOLUTIONAL NETWORKS