《WSVD:Web Stereo Video Supervision for Depth Prediction from Dynamic Scenes》论文笔记
Posted m_buddy
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了《WSVD:Web Stereo Video Supervision for Depth Prediction from Dynamic Scenes》论文笔记相关的知识,希望对你有一定的参考价值。
参考代码:wsvd_test
1. 概述
导读:在这篇文章中提出了一种基于光流估计的深度估计网络。该方法首先使用左右双目图像作为输入,并从中估计出光流信息,之后按照估计的光流对图像进行warp,这样就得到深度估计网络需要的3个(warp之后的图像1、光流、图像2)输入。接下来经过编解码网络之后实现对深度的估计。同时为了获得大量且场景多样化的双目3D(左右)图像,文章通过在YouTube中筛选的方式确定了文章使用的WSVD数据集。由于这些数据来源是未知的(其中的焦距、基线等)所以文章提出了一种以归一化梯度为主的损失函数。
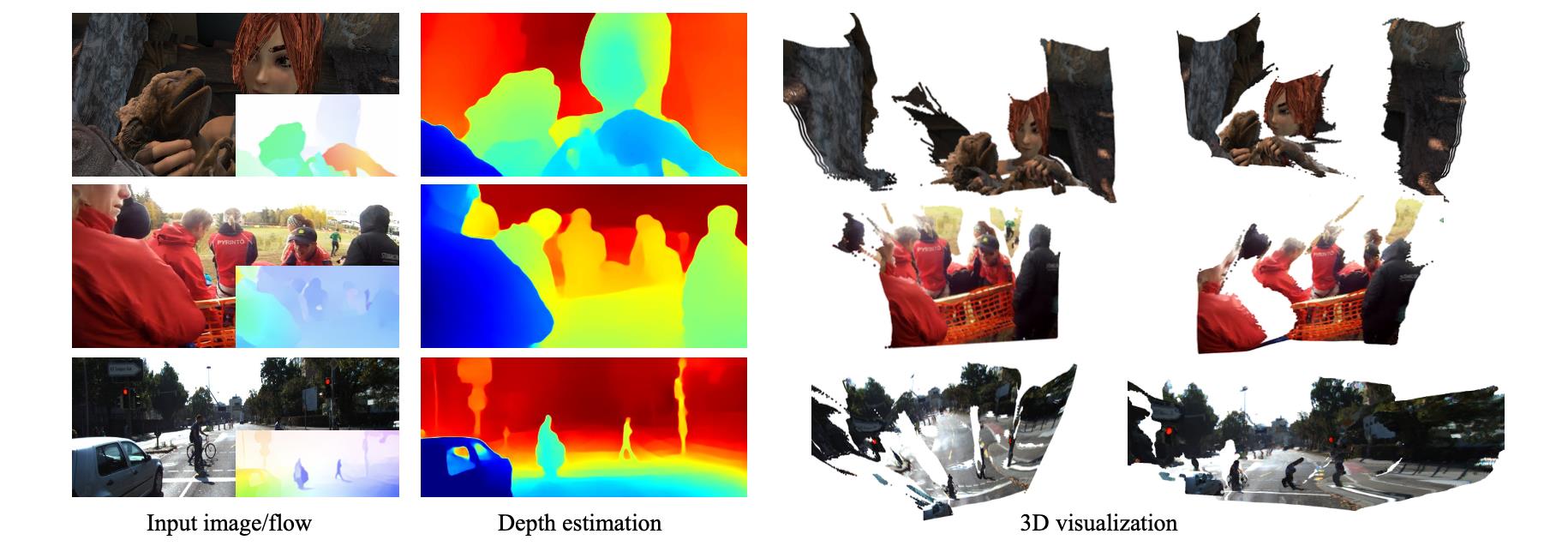
文章深度估计方法是属于回归类型的,通过使用场景多样的WSVD数据集以及对相机参数不敏感的梯度损失函数实现监督,从而得到相对鲁棒的深度估计结果。文章的效果可参见下图:
同时对WSVD数据集中的场景分布进行统计,可以得到下面的统计结果(字越大代表的占有的比例越大),参考下图:

2. 方法设计
2.1 方法pipline
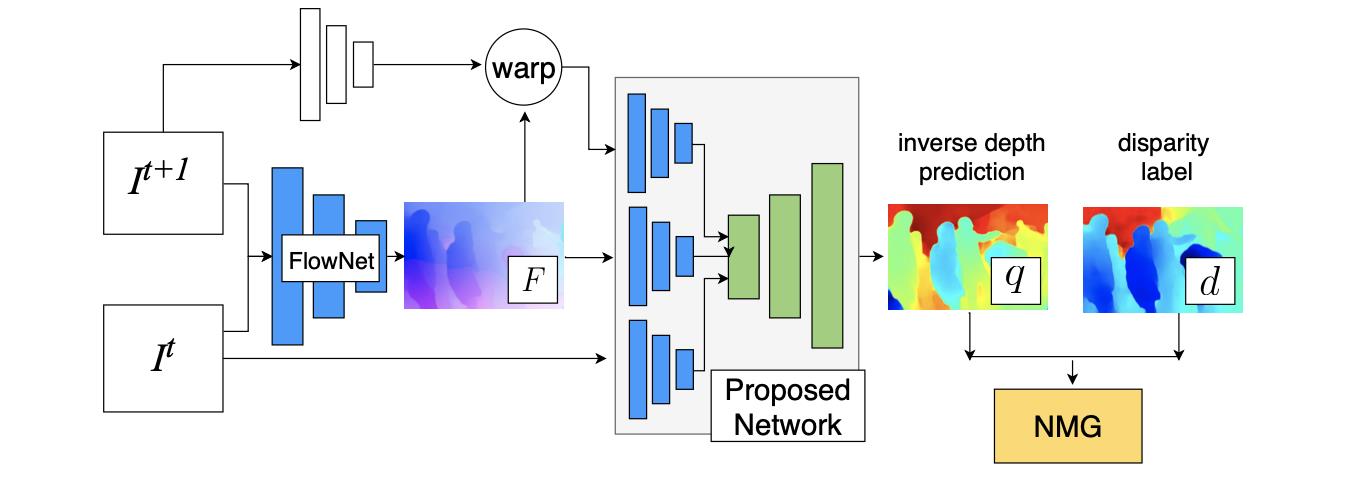
文章提出的pipeline结构如上图,通过FlowNet2生成编解码网络所需的3个输入,之后通过梯度损失函数进行监督。
2.2 损失函数
在双目系统下深度可以通过几个变量描述:
q
=
d
−
(
c
x
R
−
c
x
L
)
f
b
q=\\frac{d-(c_x^R-c_x^L)}{fb}
q=fbd−(cxR−cxL)
其中,
f
b
fb
fb代表的是焦距和基线,
d
m
i
n
=
c
x
R
−
c
x
L
d_{min}=c_x^R-c_x^L
dmin=cxR−cxL是图像对中的最小视差。但是上述关系中涉及到的3个变量是未知的,对此文章提出从梯度角度出发提出一种基于梯度的深度监督损失(NMG,normalized multiscale gradient)。这里监督是使用网络估计出的深度和视差图在梯度上进行回归,其损失函数描述为:
L
=
∑
k
∑
i
∣
s
∇
x
k
q
i
−
∇
x
k
d
i
∣
+
∣
s
∇
y
k
q
i
−
∇
y
k
d
i
∣
L=\\sum_k\\sum_i|s\\nabla_x^kq_i-\\nabla_x^kd_i|+|s\\nabla_y^kq_i-\\nabla_y^kd_i|
L=k∑i∑∣s∇xkqi−∇xkdi∣+∣s∇ykqi−∇ykdi∣
其中,
∇
x
k
,
∇
y
k
\\nabla_x^k,\\nabla_y^k
∇xk,∇yk代表的是在不空的尺度
k
=
{
2
,
8
,
32
,
64
}
k=\\{2,8,32,64\\}
k={2,8,32,64}下的图像梯度。其中的尺度因子计算描述为:
s
=
∑
k
∑
i
∣
∇
x
k
d
i
∣
+
∑
k
∑
i
∣
∇
y
k
d
i
∣
∑
k
∑
i
∣
∇
x
k
q
i
∣
+
∑
k
∑
i
∣
∇
y
k
q
i
∣
s=\\frac{\\sum_k\\sum_i|\\nabla_x^kd_i|+\\sum_k\\sum_i|\\nabla_y^kd_i|}{\\sum_k\\sum_i|\\nabla_x^kq_i|+\\sum_k\\sum_i|\\nabla_y^kq_i|}
s=∑k∑i∣∇xkqi∣+∑k∑i∣∇ykqi∣∑k∑i∣∇xkdi∣+∑k∑i∣∇ykdi∣
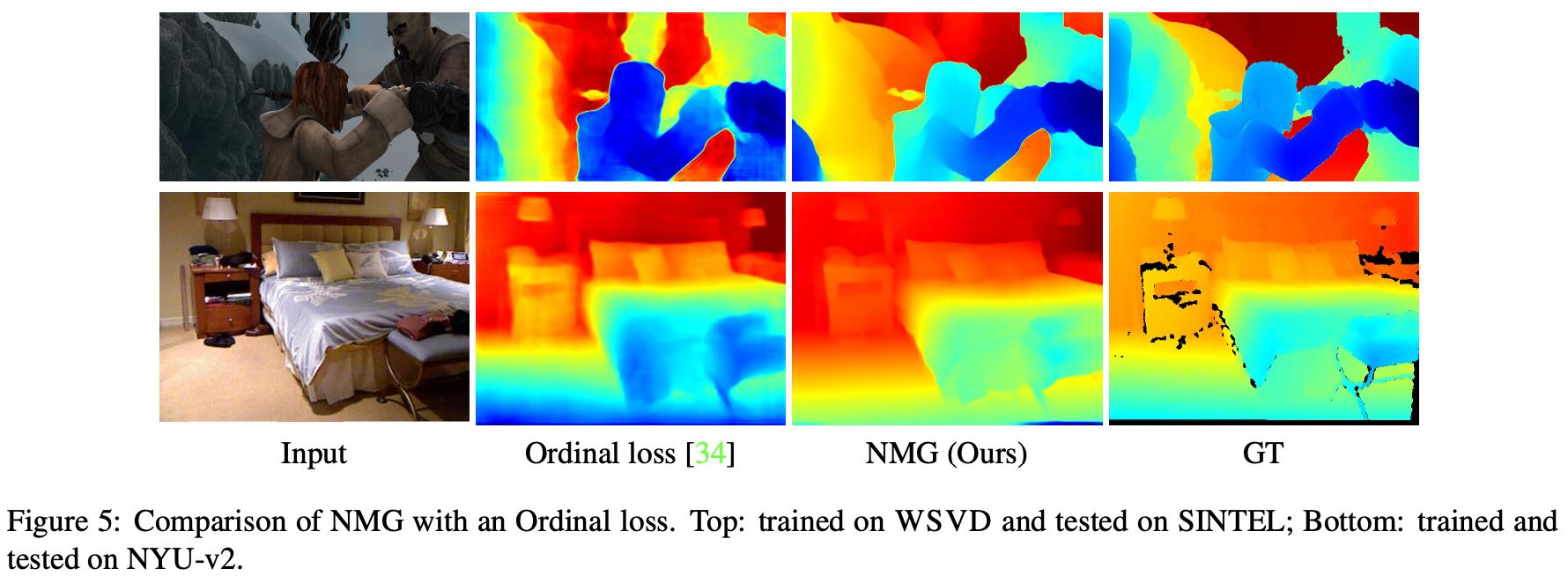
文章损失函数与ranking loss的比较:
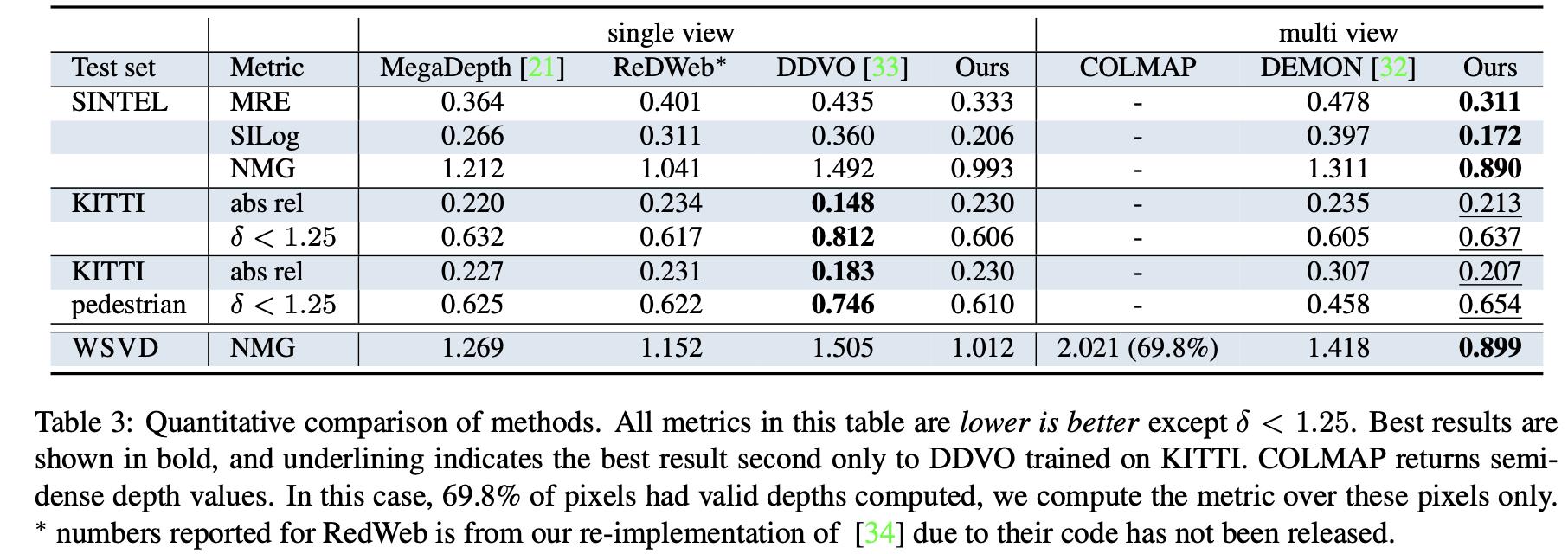
3. 实验结果
以上是关于《WSVD:Web Stereo Video Supervision for Depth Prediction from Dynamic Scenes》论文笔记的主要内容,如果未能解决你的问题,请参考以下文章
OpenAL 中的 ALC_STEREO_SOURCES 是啥?
photometric_stereo halcon光度立体法三维表面重建
《RAFT-Stereo:Multilevel Recurrent Field Transforms for Stereo Matching》论文笔记