Selenium_python自动化第一个测试案例(代码基本规范)
Posted dchaoinfo
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Selenium_python自动化第一个测试案例(代码基本规范)相关的知识,希望对你有一定的参考价值。
发生背景:
最近开始整理Selenium+python自动化测试项目中相关问题,偶然间翻起自己当时学习自动化时候写的脚本,发现我已经快认不出来写的什么鬼流水账了,所以今天特别整理下自动化开发Selenium+python脚本的基本示例;
示例脚本:
1、在这里拿最简单的示例代码分别讲解写脚本时候需要注意的地方,和各模块的作用;
# -*- coding:utf-8 -*- __author__=\'dong.c\' from selenium import webdriver import unittest import htmlTestRunner import sys from time import sleep reload(sys) sys.setdefaultencoding(\'utf-8\') class BaiduTest(unittest.TestCase): """百度首页搜索测试用例""" def setUp(self): self.driver = webdriver.Firefox() self.driver.implicitly_wait(30) self.base_url = u"http://www.baidu.com" def test_baidu_search(self): driver = self.driver print u"开始[case_001]百度搜索" driver.get(self.base_url) #验证标题 self.assertEqual(driver.title,u"百度一下,你就知道") driver.find_element_by_id("kw").clear() driver.find_element_by_id("kw").send_keys(u"博客园") driver.find_element_by_id("su").click() sleep(3) #验证搜索结果标题 self.assertEqual(driver.title,u"博客园_百度搜索") def tearDown(self): self.driver.quit() if __name__ == \'__main__\': testunit = unittest.TestSuite() testunit.addTest(BaiduTest(\'test_baidu_search\')) #定义报告输出路径 htmlpath = u"testReport.html" fp = file(htmlpath,"wb") runner = HTMLTestRunner.HTMLTestRunner(stream=fp,title=u"百度测试",description = u"测试用例结果") runner.run(testunit) fp.close()
代码解释:
1、总体上代码分为五大块:
a、文件保存编码及作者定义
# -*- coding:utf-8 -*-
__author__=\'dong.c\'
b、导入相关基础模块
#从selenium中导入webdriver模块
from selenium import webdriver
#导入unittest模块,作为用例基类
import unittest
#导入html报告生成模块,用于html格式报告生成
import HTMLTestRunner
#导入sys模块
import sys
#导入sleep模块,用于强制等待
from time import sleep
c、设置当前pythony运行环境为utf-8
#设置当前python运行在utf-8编码下,这样你的中文就不会乱码了
reload(sys)
sys.setdefaultencoding("utf-8")
d、定义和实现测试用例
#从unittest.TestCase继承
class BaiduTest(unittest.TestCase):
"""百度首页搜索测试用例"""
#用例初始化函数,自动执行
def setUp(self):
#初始化基于firefox浏览器的实例
self.driver = webdriver.Firefox()
#给当前webdriver设置全局隐性等待时间,最大30s
self.driver.implicitly_wait(30)
#设置url首页
self.base_url = u"http://www.baidu.com"
def test_baidu_search(self):
#简单赋值,这样在本次测试后继续不用每次都写self.driver;
driver = self.driver
#在控制台打印输出
print u"开始[case_001]百度搜索"
#启动浏览器,并访问首页
driver.get(self.base_url)
#验证标题
self.assertEqual(driver.title,u"百度一下,你就知道")
#清理输入框中的数据
driver.find_element_by_id("kw").clear()
#在输入框中输入博客园
driver.find_element_by_id("kw").send_keys(u"博客园")
#单击百度搜索
driver.find_element_by_id("su").click()
#强制等待3s
sleep(3)
#验证搜索结果标题
self.assertEqual(driver.title,u"博客园_百度搜索")
#用例级清理函数、自动执行
def tearDown(self):
#退出webdriver,同时关闭当前webdriver session下所有浏览器窗口
self.driver.quit()
e、测试脚本主运行入口
#python main函数
if __name__ == \'__main__\':
#初始化一个用例套件集
testunit = unittest.TestSuite()
#往用例套件集中添加一个测试
testunit.addTest(BaiduTest(\'test_baidu_search\'))
#定义报告输出路径,这里是当前目录
htmlpath = u"testReport.html"
#打开测试报告文件
fp = file(htmlpath,"wb")
#构建一个HTMLTestReport执行器
runner = HTMLTestRunner.HTMLTestRunner(stream=fp,title=u"百度测试",description = u"测试用例结果")
#运行测试集
runner.run(testunit)
#关闭打开的测试报告文件
fp.close()
运行代码:
使用上述命令运行后发现打开了百度首页,输入博客园后单击一下百度一下按钮,显示出搜索结果后关闭了浏览器;在当前目录下生成了html格式的测试报告文件;
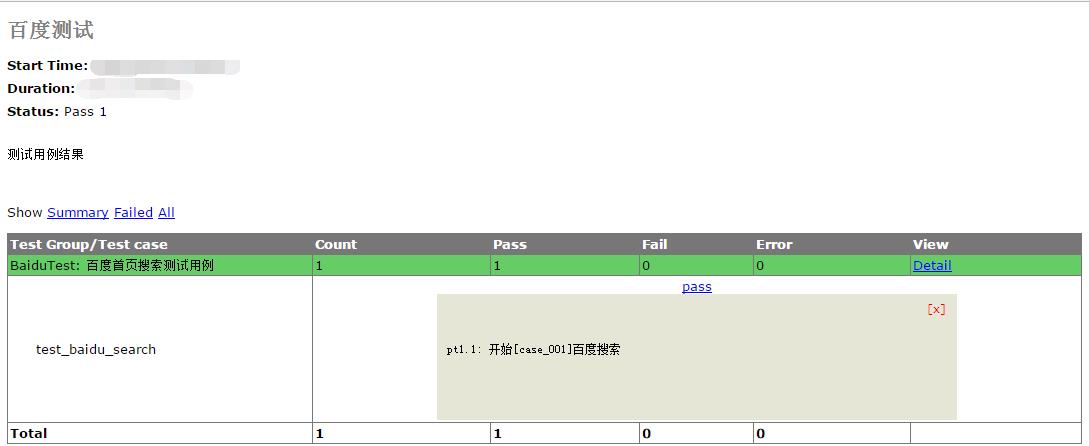
总结:
要注意的关键点,确保selenium环境已经配置好,对应浏览器驱动已经下载;
确保下载了HTMLTestRunner文件;
对应环境问题下篇博客介绍;
以上是关于Selenium_python自动化第一个测试案例(代码基本规范)的主要内容,如果未能解决你的问题,请参考以下文章