kaggle入门项目:Titanic存亡预测数据处理
Posted fancyutech
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了kaggle入门项目:Titanic存亡预测数据处理相关的知识,希望对你有一定的参考价值。
原kaggle比赛地址:https://www.kaggle.com/c/titanic
原kernel地址:A Data Science Framework: To Achieve 99% Accuracy
问题处理之前要知道的事:
数据科学框架(A Data Science Framework)
1.定义问题(Define the Problem):
问题→需求→方法→设计→技术,这是刚开始拿到问题的解决流程,所以在我们用一些fancy的技巧和算法解决问题之前,必须要明确我们需要解决的问题到底是什么
2.获取数据:
从dirty data转换到clean data 的方法。
3.数据处理准备(Prepare Data for Consumption):
不太清楚如何准确的翻译Prepare Data for Consumption,但是根据此kernel的解释。就是数据整理,简单的说就是把“野生”数据转换成“被驯服”的数据,将数据整理成适合存储和处理的数据架构,输的提取、数据清理、处理异常、缺失、离群的数据点。
4:探索性数据分析(Perform Exploratory Analysi):
GIGO,减少无意义的输入才能提升输出的质量,所以使用图表、数据显示等可视化方法才能发现潜在的问题与feature、feature 之前的关联度。同样,数据分类也利于理解选择合适的数据模型。
5:数据建模(Model Data):
知道如何针对该问题选取合适的工具(tool),差的模型导致差的结论,毋庸置疑。
6:验证与实现数据模型(Validate and Implement Data Model):
这一步确保没有过拟合(overfit)——训练集上性能出众,测试集上抓瞎。
7:优化与策略(Optimize and Strategize):
通过迭代提升性能。
接下来就通过这七步来逐一分析Titanic号问题。
Step 1:Define the Problem
Titanic号的悲剧发生于1912年4月15日,2224名乘客中死亡1502人,举世震惊。我们的这次的问题就是通过Titanic的乘客信息来预测该乘客的生还可能。
知识点:二元分类问题,Pyhton或R语言(该kernel使用Pyhton)
Step 2:Gather the Data
https://www.kaggle.com/c/titanic/data (Titanic数据集下载)
Step 3:Prepare Data for Consumption
3.11 Load Data Modelling Libraies
数据清理,所需Python包已包含在kernel中
需要注意的是作者使用的是python3,在之前的学习中我使用的Pyhton2.7,因此我卸载了所有的python环境与老版本的各种包,直接下载了anaconda3.6版本一步到位。在这里还是推荐大家使用python3进行数据分析,他比python2更规范,更先进。
3.2 Meet and Great Data
通过数据集feature的名字与解释来了解具体属性,通过info()和sample()函数获取feature信息,需要注意的有以下几点:
1.Survived列是需要输出的,二元变量,1代表存活,0代表死亡。其他features是为了学习与预测提供的。注意:features多并不一定是好事,选择合适的features才重要。
2.PassengerID与Ticket列是随机的唯一标识符,对预测没有贡献,直接除去。
3.Pclass是仓位等级,贡献较大我们将其以1,2,3代替。
4.Name列看上去没什么用处,其实我们可以通过名字的title确定性别、家庭规模、及其社会地位。
5.Sex和Embarked可以转换为dummy variables——虚拟变量,便于模型构造
6.Age和Fare,连续变量。
7.SibSp代指兄弟姐妹同船人数,Parch代指父母同船人数,这两个属性可以巧妙的合成家庭大小,对预测很有帮助。
8.Cabin列的缺失实在是太多了,这种情况我们直接删除之。
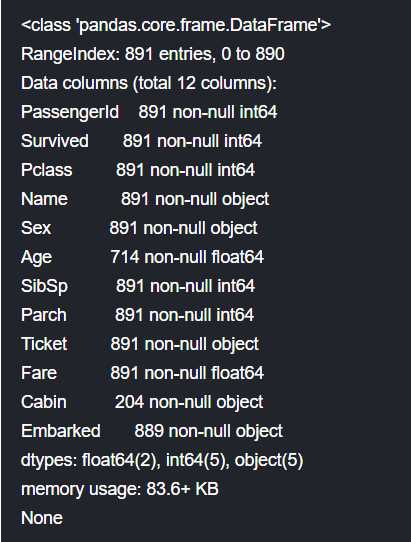
我们发现数据的缺失并不算多,但是为了模型训练,我们必须进行缺失数据处理,随后讨论。
3.21 The 4 C‘s of Data Cleaning: Correcting, Completing, Creating, and Converting
数据清理的4C要义:
1.Correcting 准确性:简单的例子,如果Age里本应该是80却错标成800,这就出现了incorrect。
2.Completing完整性:有些算法没法处理丢失信息,所以当然要进行丢失数据处理啦。
两种常用方法:要么删除要么填充,不建议删除,因为很多feature含有大量信息,简单删除后肯定会产生bias。填充的话一边使用均值、中位数或者均值+随机化标准偏差。
3.Creating创造性:用现有数据产生新数据集,用我一个师兄的话就是靠脑洞!当然这是比较调侃的说法,有很多creat feature的方法可以参考,作为初学者我也并未深入学习,待到以后有所心得了再来分享。
4.Converting数据转换:用此kernel 的话说是数据格式化,因为分类的数据并不适合算法计算,因此我们引入dummy variables,于此相关的还有One-hot编码。
3.22 Clean Data
作者使用了pandas 的fillna()方法对数据集中的空值进行填充:
对于连续变量,例如Age、Fare使用中位数进行填充median(),至于为什么不使用平均数进行填充是因为有很多离群点会对数据造成干扰,中位数更能代表大多数数据的中指,这会在后来的数据可视化分析上体现。
对于分类型变量例如Embarked,使用众数进行填充mode()[0],毕竟当我们不知道某一row属于何种类别的时候将其归类为概率较高的类别是合理的。
接着使用
dataset[‘FamilySize‘] = dataset [‘SibSp‘] + dataset[‘Parch‘] + 1
构造了家庭大小数属性。
添加IsAlone属性标识是否一人登船。
从Name属性中提取Title,因为我们发现所有的名字几乎都含有title,就是Mr、Miss等称呼
因此我们提取(,)与(.)之间的元素,构成Title属性,该属性隐藏着性别与社会地位等信息。
我们构建FareBin和AgeBin将船票价格和年龄分成几个不同的等级,使得连续数据集更好的适应算法。这里用到了pandas的qcut()和cut()函数。
3.23 Convert Formats
将分类的变量转换为dummy variables,所谓dummy变量就是用0或1来表示该属性是否出现,我们可以发现处理后的data1_dummy出现了Embarked_C、Embarked_Q、Embarked_S等等dummy变量,应该很好理解了。
3.24 Da-Double Check Cleaned Data
再次确认数据处理结果,cleaning Done!
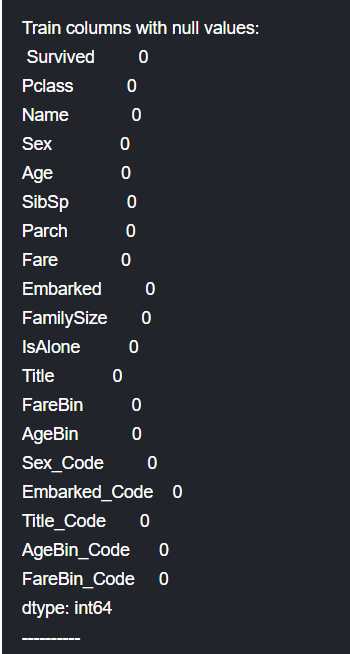
未完待续~
以上是关于kaggle入门项目:Titanic存亡预测数据处理的主要内容,如果未能解决你的问题,请参考以下文章