判定程序员等级,HashMap就够了
Posted zj-blog
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了判定程序员等级,HashMap就够了相关的知识,希望对你有一定的参考价值。
JDK1.8 HashMap源码分析
用到的符号:
^异运算:两个操作数相同,结果是;两个操作数不同,结果是1。
&按位与:两个操作数都是1,结果才是1。
一、HashMap概述
在JDK1.8之前,HashMap采用数组+链表实现,即使用链表处理冲突,同一hash值的链表都存储在一个链表里。但是当位于一个桶中的元素较多,即hash值相等的元素较多时,通过key值依次查找的效率较低。而JDK1.8中,HashMap采用数组+链表+红黑树(二叉树的优化实现是一种平衡二叉树,可以降低数的深度)实现,当链表长度超过阈值(8)时,将链表转换为红黑树,这样大大减少了查找时间。
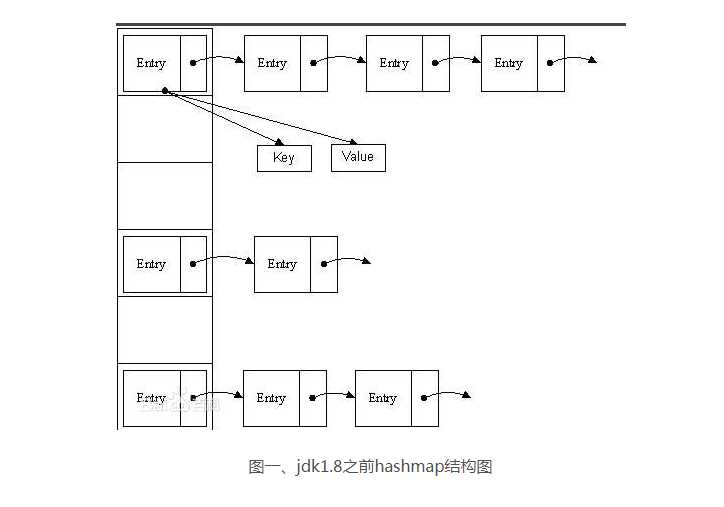
jdk1.8之前的hashmap都采用上图的结构,都是基于一个数组和多个单链表,hash值冲突的时候,就将对应节点以链表的形式存储。如果在一个链表中查找其中一个节点时,将会花费O(n)的查找时间,会有很大的性能损失。到了jdk1.8,当同一个hash值的节点数不小于8时,不再采用单链表形式存储,而是采用红黑树。
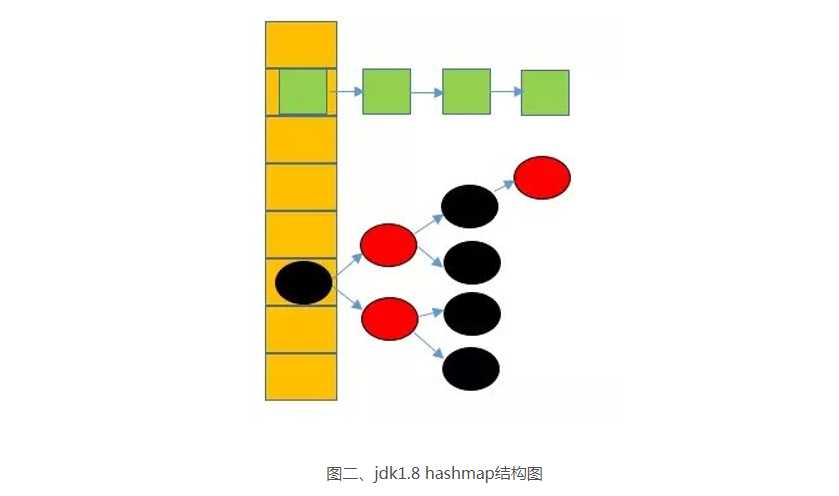
二、了解Hash函数
我们先了解一下Hash的源码:

代码执行过程:如果key为空,返回0;如果key不为空,返回原hash值和原hash值无符号右移16位的值按位异或的结果。(把低16位和高16位进行异或运算)。因为低位重复概率计算大,低位和高位异或运算可以提交数组的利用率,使数组分布均匀。
按位异或就是把两个数按二进制,相同就取0,不同就取1。
比如:0101 ^ 1110 的结果为 1011,异或的速度是非常快的。
把一个数右移16位即丢弃低16为,就是任何小于216的数,右移16后结果都为0(2的16次方再右移刚好就是1)。
任何一个数,与0按位异或的结果都是这个数本身。
所以这个hash()函数对于非null的hash值,仅在其大于等于216的时候才会重新调整其值。
但是调整后又什么好处呢?
我们先看下put的时候,这个hash值是怎么处理(部分源码)的:
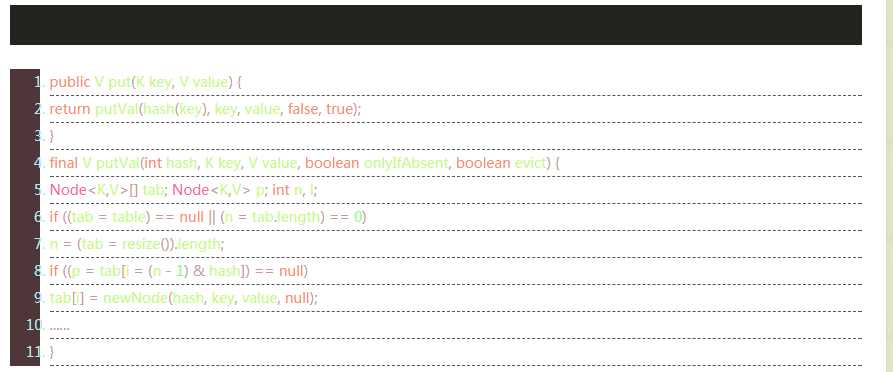
在寻找桶位的时候,这个hash值为与上table的zise-1,初始为16,我们就拿16来举例.
以为算法是hashValue & size - 1 ,此时size-1=15的二进制为 1 1 1 1 ,也就是任意类似16进制0x?0(二进制最后四位为0000)的hash值,都会被存储到位置为0的桶位上,一个桶中的元素太多,就一定会降低其性能。我们知道HashMap是一个数组+链表,就是在下标相同的位置下面挂一个单项的链表,那数组的下标需要计算出来,必须保证在一定的范围内,是通过【(n-1)&hash】计算机计算的是二进制,比如数组大小必须是2的N次幂,权重是0.75,数组初始值是16,权重等于12(16*0.75),当等于12数组会扩容。扩容之后对数组进行重新分配。当链表的大小大于8的时候会转化为红黑树。数组下标计算方式:(0101010101010101010101010101&00000000000000000001111)以16来说,十六进制的二进制表示后面的0,N-1的二进制结尾是1111,两者进行与操作最大值是1111,1111的16十六进制是15,然后把Node节点放入这个位置,这样来计算下标。
总结如下:

以上是关于判定程序员等级,HashMap就够了的主要内容,如果未能解决你的问题,请参考以下文章