ceph总结
Posted Jason__Zhou
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ceph总结相关的知识,希望对你有一定的参考价值。
ceph系统原理 细节 benchmark 不完全说明
转载请说明出处:
http://blog.csdn.net/XingKong_678/article/details/51473988
1 流程说明
1.1 应用
1) RADOS GW是一个提供与Amazon S3和Swift兼容的RESTful API的gateway,以供相应的对象存储应用开发使用。RADOS GW提供的API抽象层次更高,但功能则不如librados强大。因此,开发者应针对自己的需求选择使用.
2) RBD则提供了一个标准的块设备接口,常用于在虚拟化的场景下为虚拟机创建volume。目前,Red Hat已经将RBD驱动集成在KVM/QEMU中,以提高虚拟机访问性能。
3) Ceph FS是一个POSIX兼容的分布式文件系统。由于还处在开发状态,因而Ceph官网并不推荐将其用于生产环境中。
1.1.1 问题说明
RADOS自身既然已经是一个对象存储系统,并且也可以提供librados API,为何还要再单独开发一个RADOS GW?
理解这个问题,事实上有助于理解RADOS的本质,因此有必要在此加以分析。粗看起来,librados和RADOS GW的区别在于,librados提供的是本地API,而RADOS GW提供的则是RESTful API,二者的编程模型和实际性能不同。而更进一步说,则和这两个不同抽象层次的目标应用场景差异有关。换言之,虽然RADOS和S3、Swift同属分 布式对象存储系统,但RADOS提供的功能更为基础、也更为丰富。这一点可以通过对比看出。由于Swift和S3支持的API功能近似,这里以Swift举例说明。Swift提供的API功能主要包括:
用户管理操作:用户认证、获取账户信息、列出容器列表等;
容器管理操作:创建/删除容器、读取容器信息、列出容器内对象列表等;
对象管理操作:对象的写入、读取、复制、更新、删除、访问许可设置、元数据读取或更新等。
由 此可见,Swift(以及S3)提供的API所操作的“对象”只有三个:用户账户、用户存储数据对象的容器、数据对象。并且,所有的操作均不涉及存储系统 的底层硬件或系统信息。不难看出,这样的API设计完全是针对对象存储应用开发者和对象存储应用用户的,并且假定其开发者和用户关心的内容更偏重于账户和 数据的管理,而对底层存储系统细节不感兴趣,更不关心效率、性能等方面的深入优化。而 librados API的设计思想则与此完全不同。一方面,librados中没有账户、容器这样的高层概念;另一方面,librados API向开发者开放了大量的RADOS状态信息与配置参数,允许开发者对RADOS系统以及其中存储的对象的状态进行观察,并强有力地对系统存储策略进行 控制。换言之,通过调用librados API,应用不仅能够实现对数据对象的操作,还能够实现对RADOS系统的管理和配置。这对于S3和Swift的RESTful API设计是不可想像的,也是没有必要的。
1.2 ceph说明:
ceph Image 一般4M分成一块.作为对象存储在OSD上.
写入8M的数据产生了两个对象(对象的大小可以自己定义.)
在存储中都是以对象4M形式存储在OSD上的。不论Image,卷还是其他的形式在OSD上只存储4M一个的对象.
块设备就像是相当于磁盘的存在.
在OSD上存储如下图所示.

1.3 系统结构读写运行过程
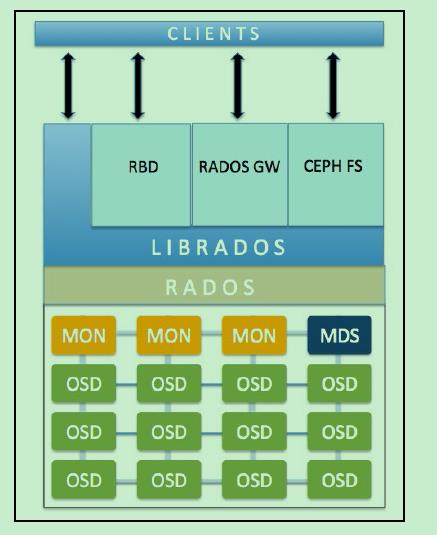
1.3.1 MON(Montior)监视器
责通过维护 Ceph Cluster map 的一个主拷贝(master copy of Cluster map)来维护整 Ceph 集群的全局状态。理论上来讲,一个 MON 就可以完成这个任务,之所以需要一个多个守护进程组成的集群的原因是保证高可靠性。每个 Ceph node 上最多只能有一个 Monitor Daemon。
1.3.2 OSD对象存储设备
OSD (Object Storage Device)集群:OSD 集群由一定数目的(从几十个到几万个) OSD Daemon 组成,负责数据存储和复制,向 Ceph client 提供存储资源。每个 OSD 守护进程监视它自己的状态,以及别的 OSD 的状态,并且报告给 Monitor;而且,OSD 进程负责在数据盘上的文件读写操作;它还负责数据拷贝和恢复。在一个服务器上,一个数据盘有一个 OSD Daemon
1.3.3 (Placement Group)PG 放置组
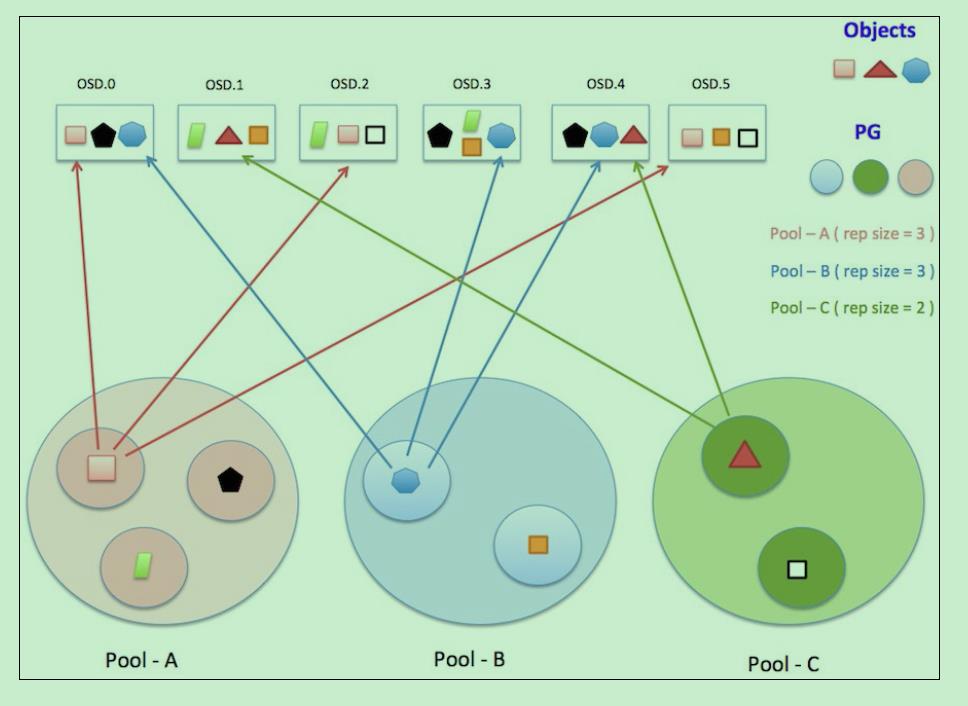
PG 也是对象的逻辑集合。同一个PG 中的所有对象在相同的 OSD 上被复制。
PG 聚合一部分对象成为一个组(group),这个组被放在某些OSD上(place),合起来就是 Placemeng Group (放置组)了。
放置组是对象存储的最小单位,对象不是每个对象自己映射到OSD,而是以放置组为单位.这样减小了集群的管理负担.
1.3.4 MDS元数据设备
MDS只有在使用cephfs时才使用,维护了集群的元数据信息.
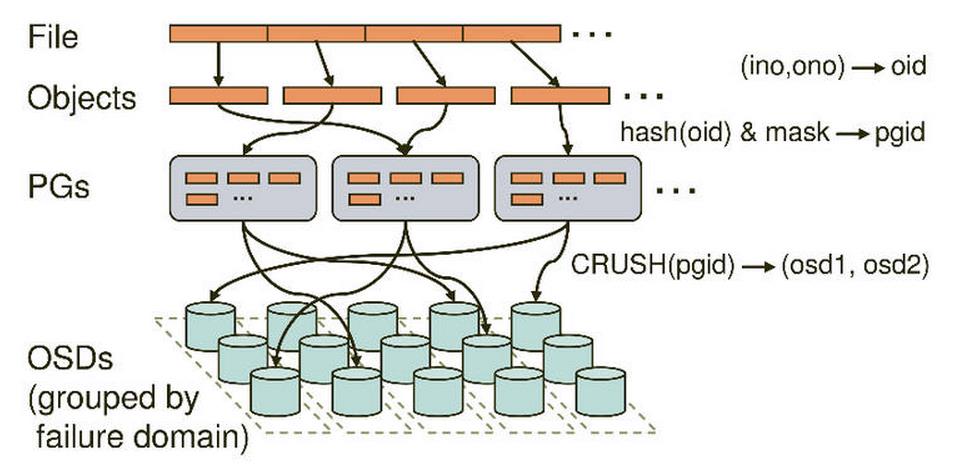
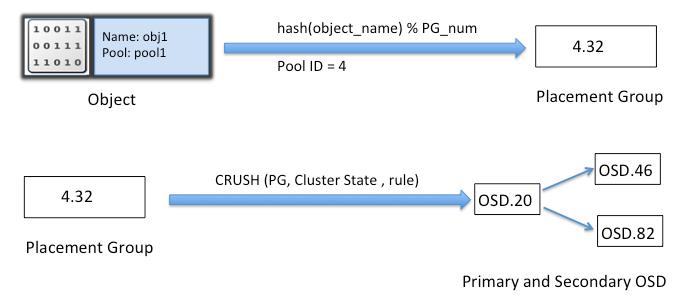
Ceph的命名空间是 (Pool, Object),每个Object都会映射到一组OSD中(由这组OSD保存这个Object):
(Pool, Object) → (Pool, PG) → OSD set → Disk
显示对象映射到放置组 pg (10.3c)在OSD 1 0 2上,共存储了3份.

一个OSD上放置组PG状态
Client从Monitors中得到CRUSH MAP、OSD MAP、CRUSH Ruleset,然后使用CRUSH算法计算出Object所在的OSD set。所以Ceph不需要Name服务器,Client直接和OSD进行通信。
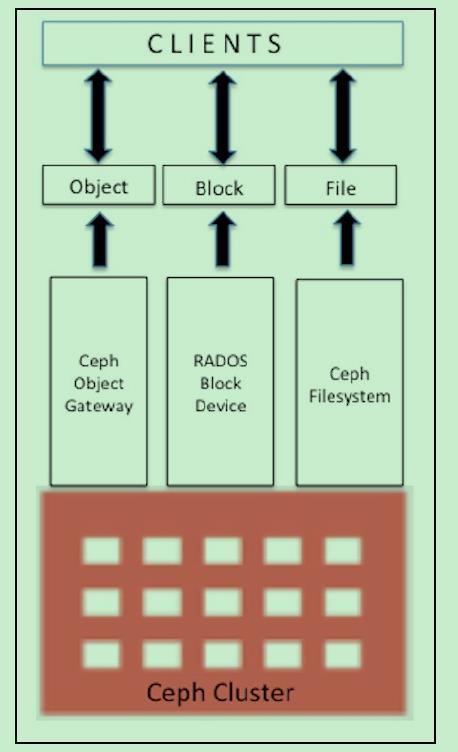
以上图说明集群从文件到OSD的过程.
从客户端来看,客户端块设备的结构.
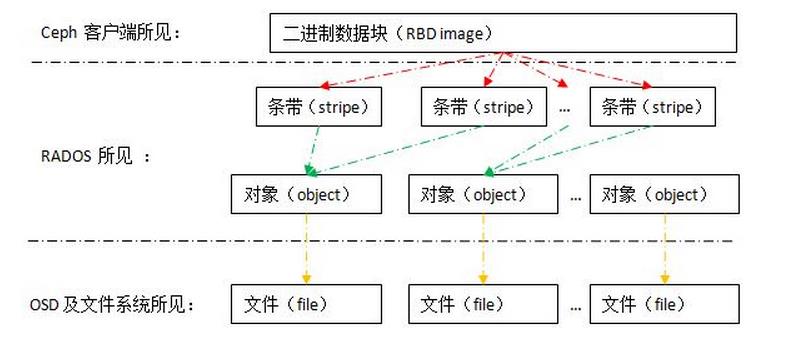
数据读写过程读写过程
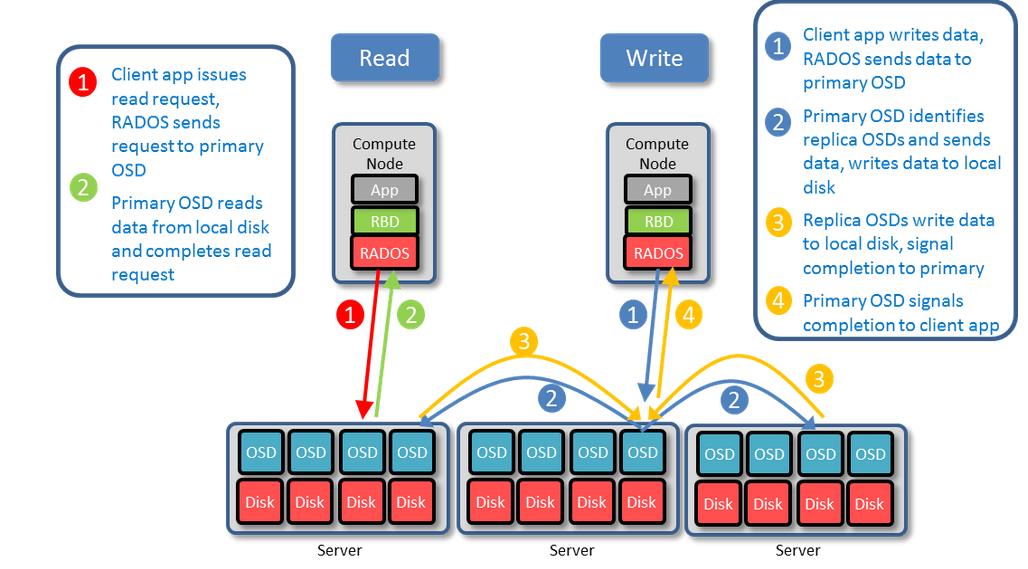
-放置组PG是集群映射对象组的单位
-给osd分层,建立SSD设备组成的快速设备pool.
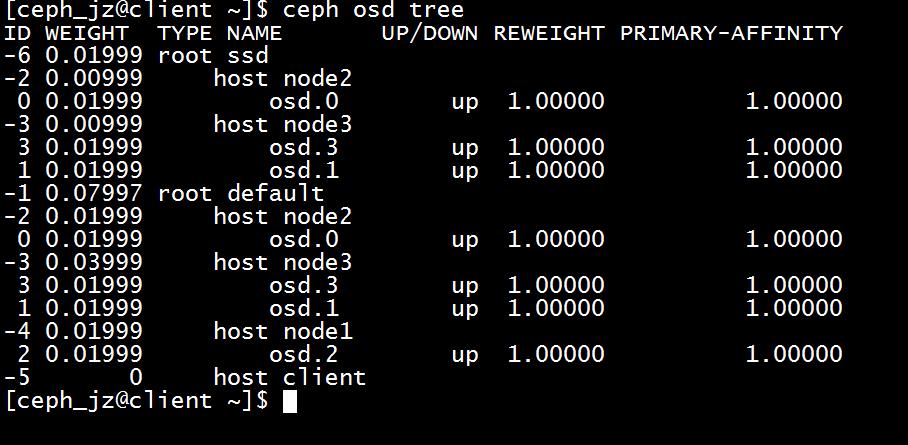
理解 OpenStack + Ceph (2):Ceph 的物理和逻辑结构 [Ceph Architecture]
http://www.cnblogs.com/sammyliu/p/4836014.html
2 ceph代码
find . -name "*.c" | xargs wc -l
| 文件类型 | 行数 |
|---|---|
| *.cc | 533135 |
| *.c | 44602 |
| *.h | 258289 |
| *.sh | 24660 |
总共 860686
2.1 源代码目录
Ceph源代码目录结构详解
http://codefine.co/2603.html
从GitHub上Clone的Ceph项目,其目录下主要文件夹和文件的内容为:
1 根目录
[src]:各功能某块的源代码
[qa]:各个模块的功能测试(测试脚本和测试代码)
[wireshark]:#wireshark的ceph插件。
[admin]:管理工具,用于架设文档服务器等
[debian]:用于制作debian(Ubuntu)安装包的相关脚本和文件
[doc]:用于生成项目文档,生成结果参考http://ceph.com/docs/master/
[man]:ceph各命令行工具的man文件
configure.ac:用于生成configure的脚本
Makefile.am:用于生成Makefile的脚本
autogen.sh:负责生成configure。
do_autogen.sh:生成configure的脚本,实际上通过调用autogen.sh实现
ceph.spec.in:RPM包制作文件
2 src目录
[include]:头文件,包含各种基本类型的定义,简单通用功能等。
[common]:共有模块,包含各类共有机制的实现,例如线程池、管理端口、节流阀等。
[log]:日志模块,主要负责记录本地log信息(默认/var/log/ceph/目录)
[global]:全局模块,主要是声明和初始化各类全局变量(全局上下文)、构建驻留进程、信号处理等。
[auth]:授权模块,实现了三方认知机制。
[crush]:Crush模块,Ceph的数据分布算法
[msg]:消息通讯模块,包括用于定义通讯功能的抽象类Messenger以及目前的实现SimpleMessager
[messages]:消息模块,定义了Ceph各节点之间消息通讯中用到的消息类型。
[os]:对象(Object Store)模块,用于实现本地的对象存储功能,
[osdc]:OSD客户端(OSD Client),封装了各类访问OSD的方法。
[mon]:mon模块
[osd]:osd部分
[mds]:mds模块
[rgw]:rgw模块的
[librados]:rados库模块的代码
[librdb]:libbd库模块的代码
[client]:client模块,实现了用户态的CephFS客户端
[mount]:mount模块
[tools]:各类工具
[test]:单元测试
[perfglue]:与性能优化相关的源代码
[json_spirit]:外部项目json_spirit
[leveldb]:外部项目leveldb from google
[gtest]:gtest单元测试框架
[doc]:关于代码的一些说明文档
[bash_completion]:部分bash脚本的实现
[pybind]:python的包装器
[script]:各种python脚本
[upstart]:各种配置文件
ceph_mds.cc:驻留程序mds
ceph_mon.cc:驻留程序mon
ceph_osd.cc:驻留程序osd
libcephfs.cc:cephfs库
librdb.cc:rdb库
ceph_authtool.cc:工具ceph_authtool
ceph_conf.cc:工具ceph_conf
ceph_fuse.cc:工具ceph_fuse
ceph_syn.cc:工具ceph_syn
cephfs.cc:工具cephfs
crushtool.cc:工具crushtool
dupstore.cc:工具dupstore
librados-config.cc:rados库配置工具
monmaptool.cc:工具monmap
osdmaptool.cc:工具osdmap
psim.cc:工具psim
rados.cc:工具rados
rdb.cc:工具rdb
rados_export.cc:rados工具相关类
rados_import.cc:rados工具相关类
rados_sync.cc:rados工具相关类
rados_sync.h:rados工具相关类
sample.ceph.conf:配置文件样例
ceph.conf.twoosds:配置文件样例
Makefile.am:makefile的源文件
valgrind.supp:内存检查工具valgrind的配置文件
init-ceph.in:启动和停止ceph的脚本
mkcephfs.in:cephfs部署脚本
3 OpenStack与ceph
通过分析发现ceph现在的状态特别像为openstack的组件.迎合openstack的需求.
openstack
-镜像image对应Openstack Glance
-Glance:管理 VM 的启动镜像,Nova 创建 VM 时将使用 Glance 提供的镜像。
-block对应于Openstack Cinder
-Cinder:为 VM 提供块存储服务。Cinder 提供的每一个 Volume 在 VM 看来就是一块虚拟硬盘,一般用作数据盘。
可以瞬间建立数千个虚拟机,使用写时复制技术的快存储.
块存储存储虚拟机的卷.克隆使复制虚拟机简单
官方文档内容:
From the roots, Ceph has been tightly integrated with cloud platforms such as OpenStack. For Cinder and Glance, which are volume and image programs for OpenStack, Ceph provides its block device backend to store virtual machine volumes and OS images. These images and volumes are thin provisioned. Only the changed objects needed to be stored; this helps in a significant amount of storage space, saving for OpenStack The copy-on-write and instant cloning features of Ceph help OpenStack to spin hundreds of virtual machine instances in less time. RBD also supports snapshots, thus quickly saving the state of virtual machine, which can be further cloned to produce the same type of virtual machines and used for point-in-time restores.Ceph acts as a common backend for virtual machines, and thus helps in virtual machine migration since all the machines can access a Ceph storage cluster. Virtualization containers such as QEMU, KVM, and XEN can be configured to boot virtual machines from volumes stored in a Ceph cluster.
3.1 OpenStack 与 Ceph 的三个结合点:
镜像:OpenStack Glance 管理虚拟机镜像。镜像是不变的。OpenStack 把镜像当作二进制对象并以此格式下载。
卷:卷是块设备。OpenStack 使用卷来启动虚拟机,或者绑定卷到运行中的虚拟机。OpenStack 使用 Cinder 服务管理卷。
客户磁盘:客户磁盘是客户操作系统磁盘。默认情况下,当启动一台虚拟机时,它的系统盘以文件的形式出现在 hypervisor 系统上(通常在/var/lib/nova/instances/)。在 OpenStack Havana 以前的版本,在 Ceph 中启动虚拟机的唯一方式是使用 Cinder 的 boot-from-volume 功能,现在能够在 Ceph 中直接启动虚拟机而不用依赖于 Cinder,这是非常有利的因为它能够让你很容易的进行虚拟机的热迁移。除此之外,如果 hypervisor 挂掉还能够方便地触发 nova evacute 然后无缝得在其他的地方继续运行虚拟机。
可以使用 OpenStack Glance 来存储镜像在 Ceph 块设备中,也可以使用 Cinder 通过镜像的写时复制来启动虚拟机。
Glance,Cinder 和 Nova,尽管它们没有必要一起使用。当虚拟机运行使用本地磁盘运行的时候,可以把镜像存储在 Ceph 块设备中,或者正相反。
Glance image 在 Ceph 中其实是个 RBD snapshot,
OpenStack Cinder 组件和 Ceph RBD 集成的目的是将 Cinder 卷(volume)保存在 Ceph RBD 中。
除了上面所描述的 Cinder、Nova 和 Glance 与 Ceph RBD 的集成外,OpenStack 和 Ceph 之间还有其它的集成点:
(1)使用 Ceph 替代 Swift 作为对象存储 (网络上有很多比较 Ceph 和 Swift 的文章,比如 1,2,3,)
(2)CephFS 作为 Manila 的后端(backend)
(3)Keystone 和 Ceph Object Gateway 的集成
结构图
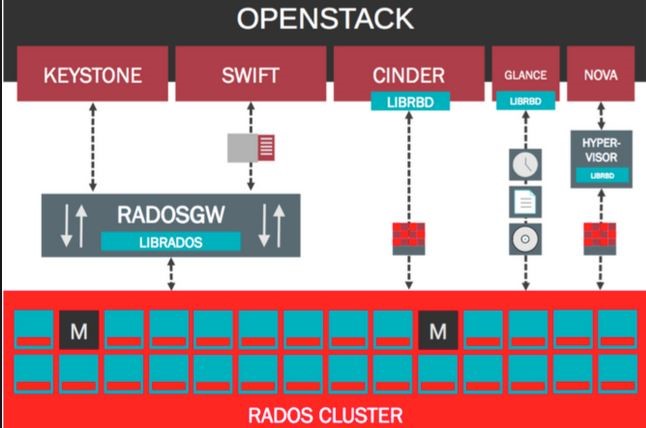
openstack
计算(Compute):Nova。一套控制器,用于为单个用户或使用群组管理虚拟机实例的整个生命周期,根据用户需求来提供虚拟服务。负责虚拟机创建、开机、关机、挂起、暂停、调整、迁移、重启、销毁等操作,配置CPU、内存等信息规格。自Austin版本集成到项目中。
对象存储(Object Storage):Swift。一套用于在大规模可扩展系统中通过内置冗余及高容错机制实现对象存储的系统,允许进行存储或者检索文件。可为Glance提供镜像存储,为Cinder提供卷备份服务。自Austin版本集成到项目中
镜像服务(Image Service):Glance。一套虚拟机镜像查找及检索系统,支持多种虚拟机镜像格式(AKI、AMI、ARI、ISO、QCOW2、Raw、VDI、VHD、VMDK),有创建上传镜像、删除镜像、编辑镜像基本信息的功能。自Bexar版本集成到项目中
块存储 (Block Storage):Cinder。为运行实例提供稳定的数据块存储服务,它的插件驱动架构有利于块设备的创建和管理,如创建卷、删除卷,在实例上挂载和卸载卷。自Folsom版本集成到项目中。
Nova
在OpenStack Nova项目中存在两种类型的存储,一类是本地易失性存储,另一类是持久块设备。两者最明显的特征就是持久块设备由Cinder项目管理,并且具备大量API进行管理,如Snapshot,Backup等等。而相对的本地易失性存储由Nova的hypervisor实现,如在libvirt中目前支持Qcow,LVM镜像类型。这类存储只具备简单的创建和删除设备能力,主要用作创建Root,Swap,Empheremal磁盘分区的后备。
Cinder项目很早就已经支持Ceph,并且一直是最完备的后端之一,而在H版的Nova易失性存储中同样迎来了Ceph的支持(只支持libvirt)Add RBD supporting to libvirt for creating local volume。在Nova中,目前可以通过指定”libvirt_images_type=rbd”来选择Ceph作为易失性后端。这就意味着如果采用Ceph作为块设备支持,那么在OpenStack的VM可以只采用Ceph的存储池。
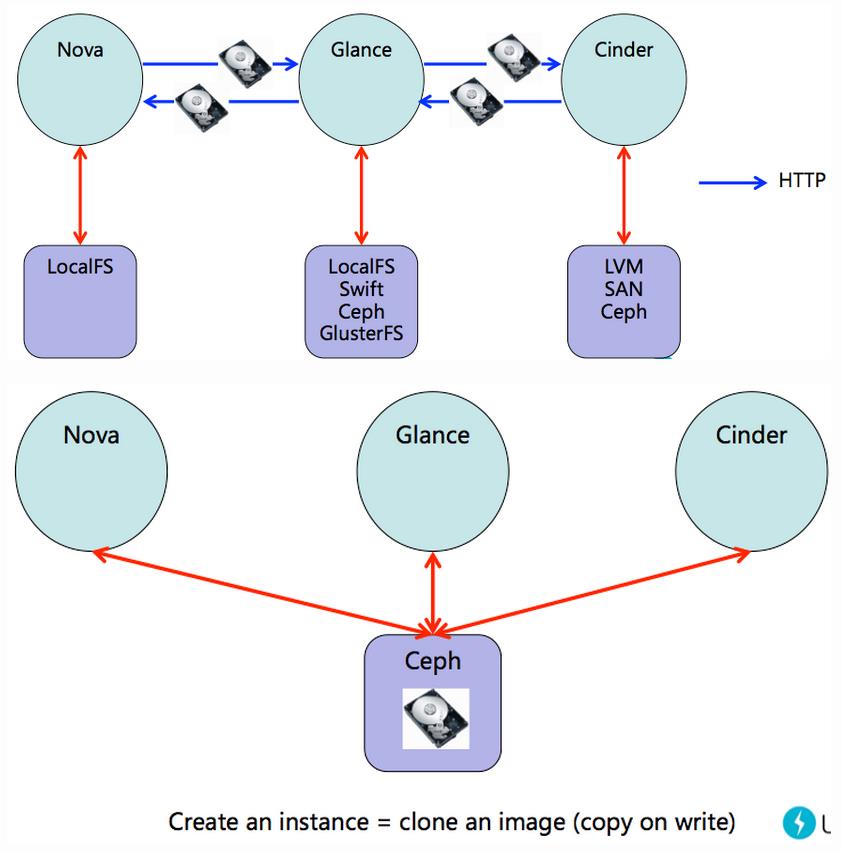
总结一下各模块的关系
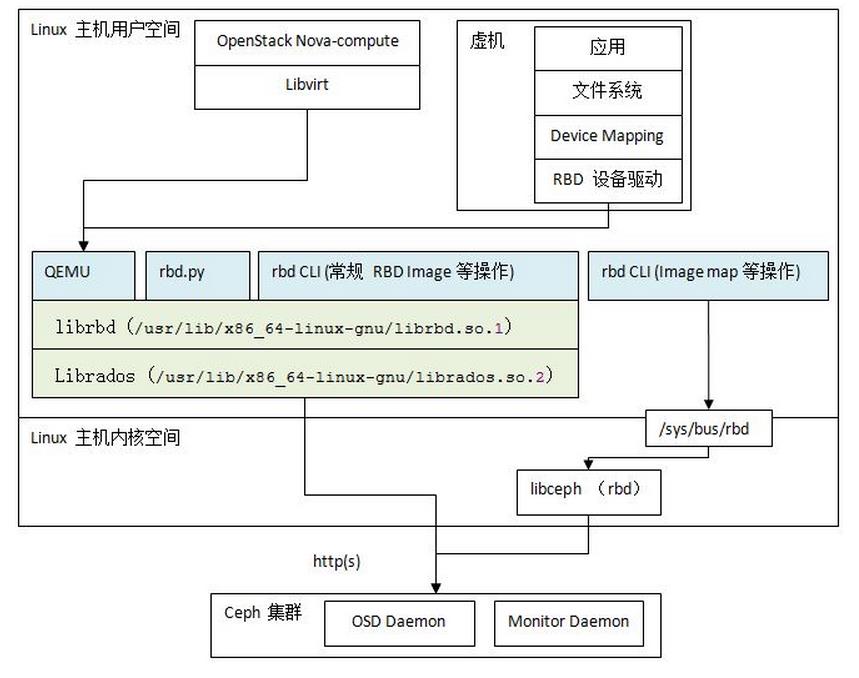
4 快照和克隆
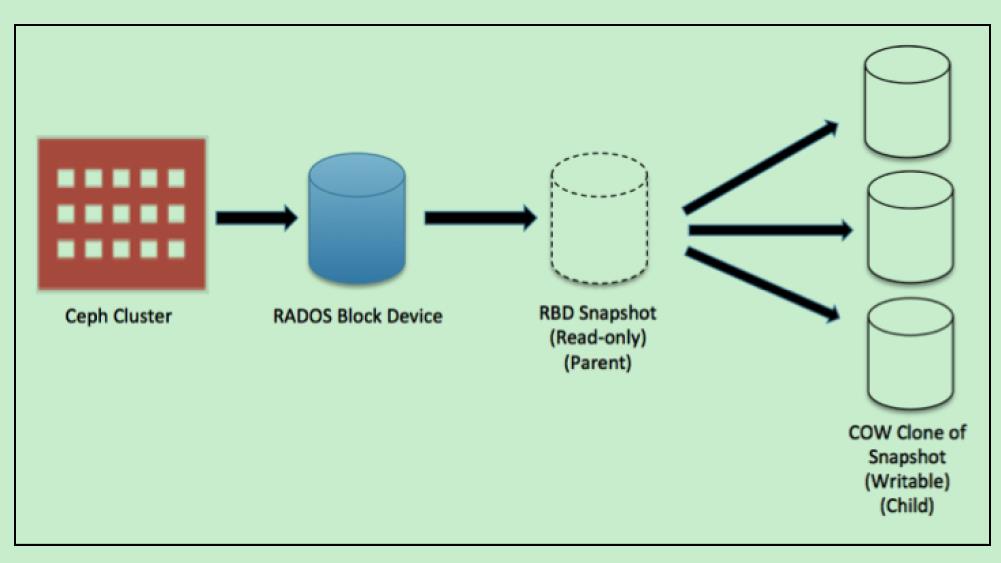
1) 快照
snapshot是特定时间镜像(这里镜像是指ceph的image)的静态拷贝
2) 克隆
clone是对snapshot的copy on write的再拷贝。通常snapshot只读,clone可以正常读写。
Ceph通过rbd命令直接支持snapshot,也通过snapshot layering技术,支持对snapshot的clone。
3) QEMU 与块设备
Ceph 块设备最常见的用法之一是作为虚拟机的块设备映像。例如,用户可创建一个安装、配置好了操作系统和相关软件的“黄金标准”映像,然后对此映像做快照,最后再克隆此快照(通常很多次)。详情参见快照。能制作快照的写时复制克隆意味着 Ceph 可以快速地为虚拟机提供块设备映像,因为客户端每次启动一个新虚拟机时不必下载整个映像。
块设备就像是相当于磁盘的存在.
5 块设备
1.块存储
Block storage is a category of data storage used in the storage area network. In this type, data is stored as volumes, which are in the form of blocks and are attached to nodes. This provides a larger storage capacity required by applications with a higher degree of reliability and performance. These blocks, as volumes, are mapped to the operating system and are controlled by its filesystem layout.
可以看出,一块分布在很多对象上
2.块分散成对象
When a client writes data to RBD, librbd libraries map data blocks into objects to store them in Ceph clusters, strip these data objects, and replicate them across the cluster, thus providing improved performance and reliability.
3.对象存储
Ceph allows direct access to its cluster; this makes it superior to other storage solutions that are rigid and have limited interfaces.
允许直接访问
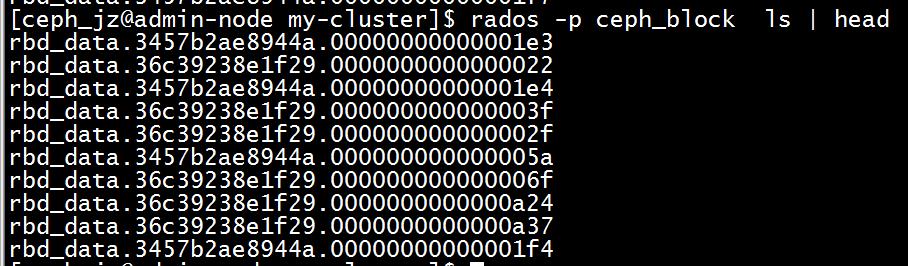
4.定位对象
rados -p ceph_block ls
ceph osd pool get ceph_block pg_num
6 image说明
非常好的文章
理解 OpenStack + Ceph (4):Ceph 的基础数据结构 [Pool, Image, Snapshot, Clone]
http://www.cnblogs.com/sammyliu/p/4843812.html
卷的含义:
[ceph_jz@client ~]$ ceph osd lspools
0 rbd,1 .rgw.root,2 .rgw.control,3 .rgw,4 .rgw.gc,5 .users.uid,6 cephfs_data,7 cephfs_metadata,8 ceph_block,9 ssd-pool,
[ceph_jz@client ~]$
[ceph_jz@client ~]$ rbd ls ceph_block
foo
myimage
bar
block
block_test
new_block_test
[ceph_jz@client ~]$
一个镜像划分成很多的对象
[ceph_jz@client ~]$ rbd info ceph_block/myimage
rbd image 'myimage':
size 102400 MB in 25600 objects
order 22 (4096 kB objects)
block_name_prefix: rb.0.58e5d.238e1f29
format: 1
[ceph_jz@client ~]$
每个块4M,100M分成25个对象
[ceph_jz@client ~]$ rbd info ceph_block/myimage
rbd image 'myimage':
size 102400 kB in 25 objects
order 22 (4096 kB objects)
block_name_prefix: rb.0.58e5d.238e1f29
format: 1
[ceph_jz@client ~]$
[ceph_jz@client ~]$ rbd showmapped
id pool image snap device
0 ceph_block myimage - /dev/rbd0
[ceph_jz@client ~]$
写入数据
[ceph_jz@client ~]$ sudo dd if=/dev/zero of=/dev/rbd0 bs=1047586 count=4
4+0 records in
4+0 records out
4190344 bytes (4.2 MB) copied, 0.0803551 s, 52.1 MB/s
[ceph_jz@client ~]$
[ceph_jz@client ~]$ rbd ls mypool
image1
[ceph_jz@client ~]$ rbd info mypool/image1
rbd image 'image1':
size 102400 MB in 25600 objects
order 22 (4096 kB objects)
block_name_prefix: rbd_data.58e7674b0dc51
format: 2
features: layering
flags:
[ceph_jz@client ~]$
创建过程pool中存在的数据
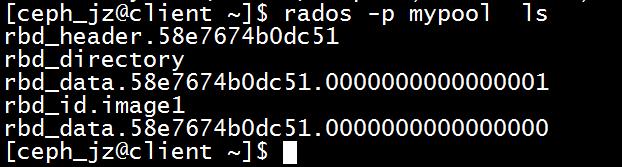
[ceph_jz@client ~]$ rados -p mypool ls
rbd_header.58e7674b0dc51
rbd_directory
rbd_id.image1
[ceph_jz@client ~]$
显示包含信息
[ceph_jz@client ~]$ rados -p mypool listomapvals rbd_directory
id_58e7674b0dc51
value: (10 bytes) :
0000 : 06 00 00 00 69 6d 61 67 65 31 : ....image1
name_image1
value: (17 bytes) :
0000 : 0d 00 00 00 35 38 65 37 36 37 34 62 30 64 63 35 : ....58e7674b0dc5
0010 : 31 : 1
[ceph_jz@client ~]$
rbd_header 保存的是一个 RBD 镜像的元数据:
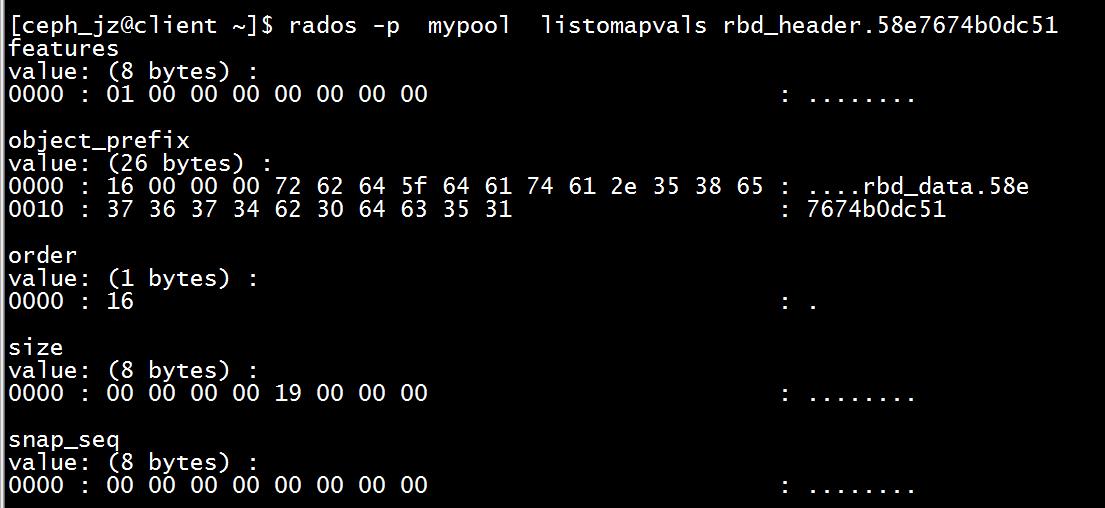
[ceph_jz@client ~]$ sudo rbd map mypool/image1
[sudo] password for ceph_jz:
/dev/rbd1
[ceph_jz@client ~]$
写入8M的数据
dd if=/dev/zero of=/dev/rbd1 bs=1048576 count=8

写入8M的数据多了两个对象
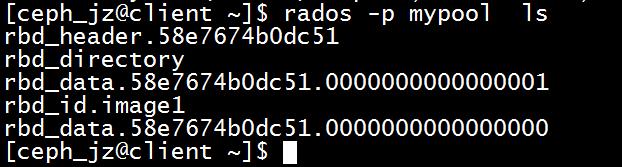
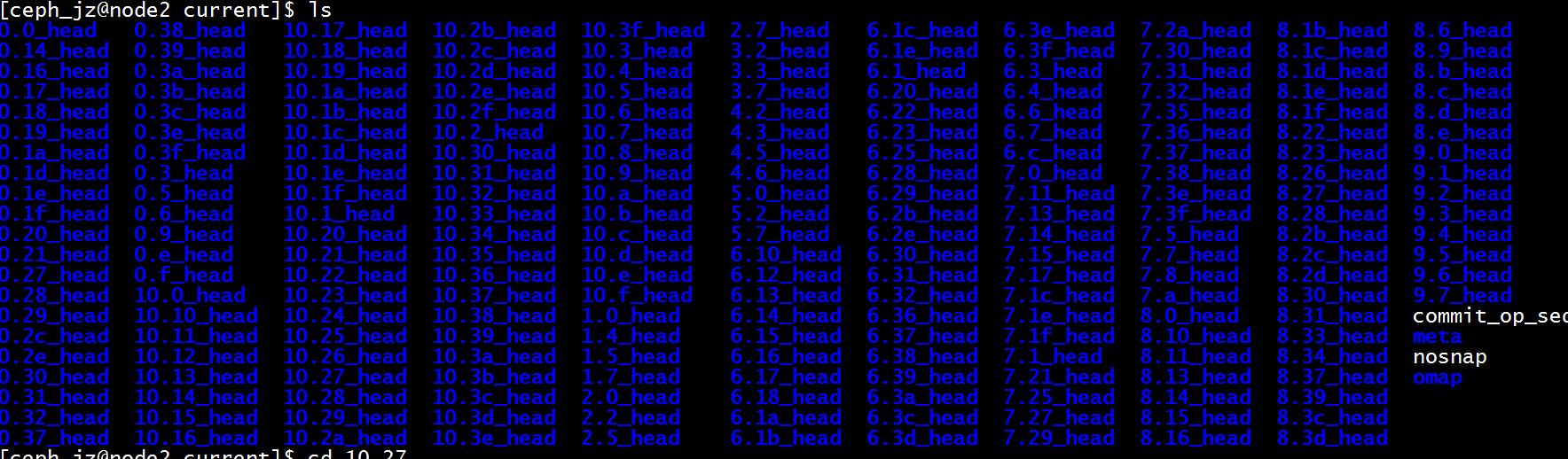
查看具体一个对象的映射.该对象映射到0 2 3 osd上

放置组为 10.27
计入osd0 查看也就是 node2
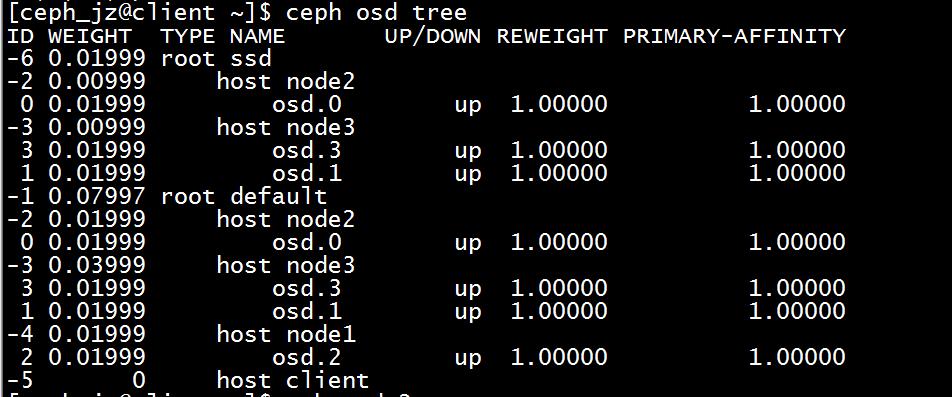
进入到node2 的状态
ceph/osd/ceph-0/current/10.27_head
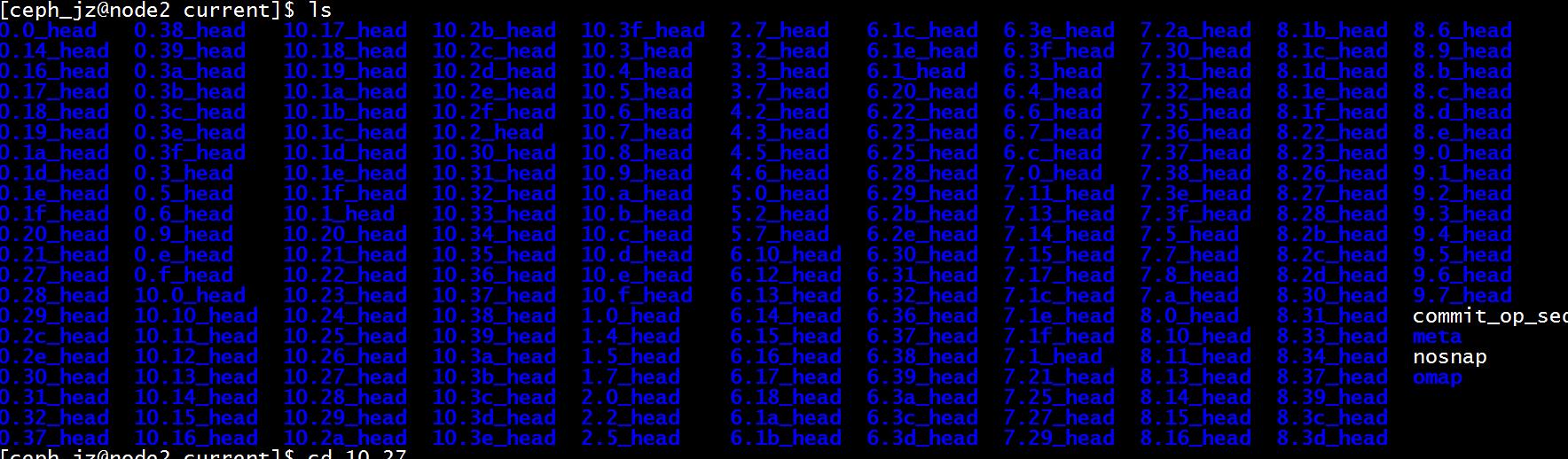
这也就是放置组


可见:
(1)RBD image 是简单的块设备,可以直接被 mount 到主机,成为一个 device,用户可以直接写入二进制数据。
(2)image 的数据被保存为若干在 RADOS 对象存储中的对象。
(3)image 的数据空间是 thin provision 的,意味着ceph 不预分配空间,而是等到实际写入数据时按照 object 分配空间。
(4)每个 data object 被保存为多份。
(5)pool 将 RBD 镜像的ID和name等基本信息保存在 rbd_directory 中,这样,rbd ls 命令就可以快速返回一个pool中所有的 RBD 镜像了。
(6)每个 RBD 镜像的元数据将保存在一个对象中,命名为 rbd_header.。
(7)RBD 镜像保存在多个对象中,这些对象的命名为 rbd_data..<顺序编号序列>。
(8)RADOS 对象以 OSD 文件系统上的文件形式被保存,其文件名为 udata.<顺序编号序列>.<其它字符串>。
7 快照说明
创建pool写入4M的数据
rados -p pool101 ls
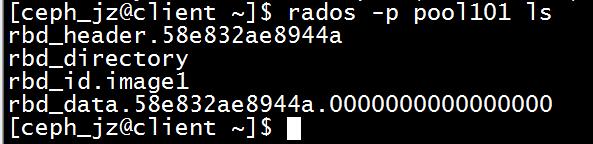
创建快照
[ceph_jz@client ~]
rbdsnapcreatepool101/image1@snap1[cephjz@client ]

创建的快照的数据再header中
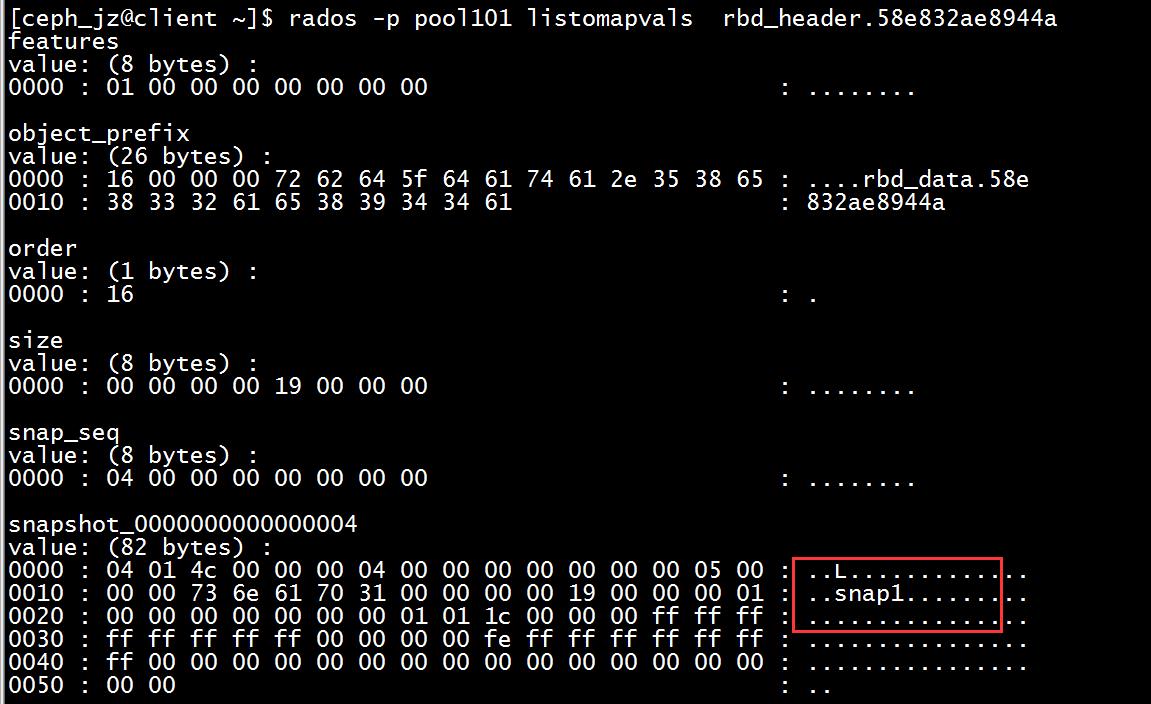
因此,
(1)snapshot 的 data objects 是和 image 的 data objects 保存在同一个目录中。
(2)snapshot 的粒度不是整个 image,而是RADOS 中的 data object。
(3)当 snapshot 创建时,只是在 image 的元数据对象中增加少量字节的元数据;当 image 的 data objects 被修改(write)时,变修改的 objects 会被拷贝(copy)出来,作为 snapshot 的 data objects。这就是 COW 的含义。
8 克隆说明
创建 Clone 是将 image 的某一个 Snapshot 的状态复制变成一个 image. 如 imageA 有一个 Snapshot-1,clone 是根据 ImageA 的 Snapshot-1 克隆得到 imageB。imageB 此时的状态与Snapshot-1完全一致,并且拥有 image 的相应能力,其区别在于 ImageB 此时可写。
保护快照然后克隆
rbd clone pool101/image1@snap1 pool101/image1snap1clone1
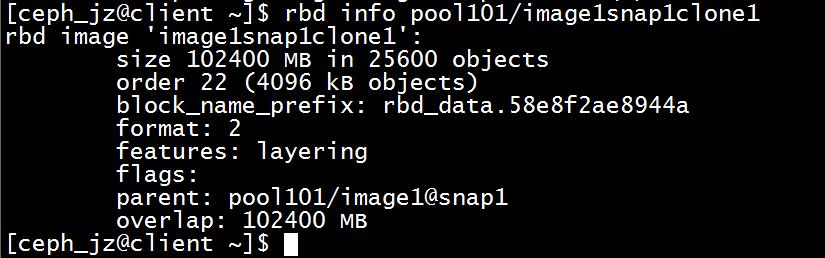
(2)从 clone 读数据
从本质上是 clone 的 RBD image 中读数据,对于不是它自己的 data objects,ceph 会从它的 parent snapshot 上读,如果它也没有,继续找它的parent image,直到一个 data object 存在。从这个过程也看得出来,该过程是缺乏效率的。
(3)向 clone 中的 object 写数据
Ceph 会首先检查该 clone image 上的 data object 是否存在。如果不存在,则从 parent snapshot 或者 image 上拷贝该 data object,然后执行数据写入操作。这时候,clone 就有自己的 data object 了。
9 RADOS API
Ceph 中文文档:http://docs.ceph.org.cn/
C++例子
LIBRADOS (C)
librados 提供了 RADOS 服务的底层访问功能, RADOS 概览参见体系结构。
提供了管理和存储相关的大量API.
例如下图

10 创建object
root@dev:/# echo "Hello Ceph, You are Awesome like MJ" > /tmp/helloceph
root@dev:/# rados -p web-services put object1 /tmp/helloceph
root@dev:/# rados -p web-services ls
object1
root@dev:/# ceph osd map web-services object1
osdmap e29 pool 'web-services' (8) object 'object1' -> pg 8.bac5debc (8.3c) -> up ([0], p0) acting ([0], p0)
11 ceph监控系统
ceph的相关项目提供了ceph监控和管理工具.
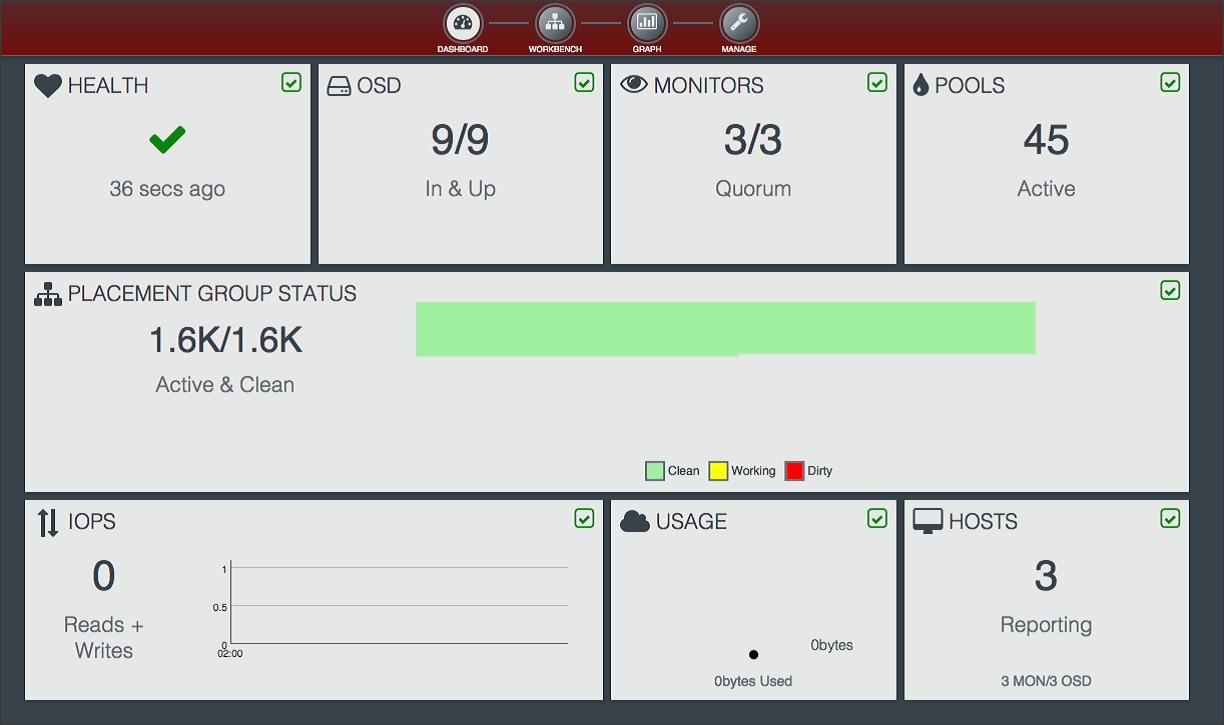
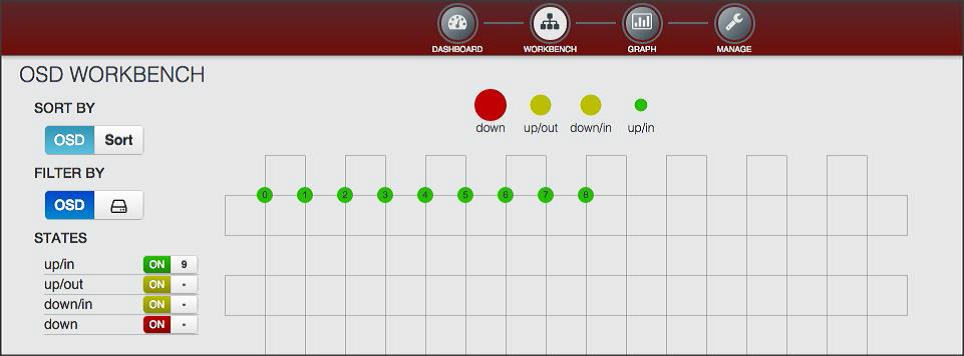
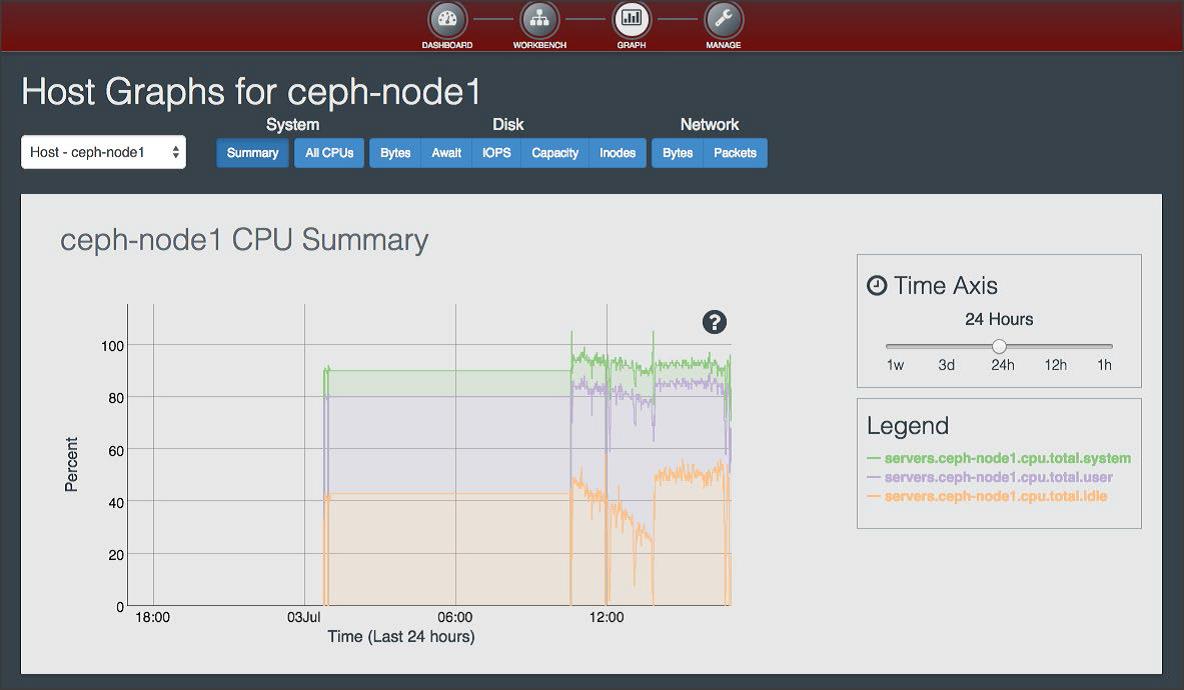
监控信息
通过本章我们可以学到Ceph官方提供的ceph-rest-api,并带领大家一步一步实现基于ceph-rest-api的Web监控管理工具。
inkscope
[inkscope]安装的ceph的监控平台inkscope 1.1
http://blog.csdn.net/nocturne1210/article/details/50559659
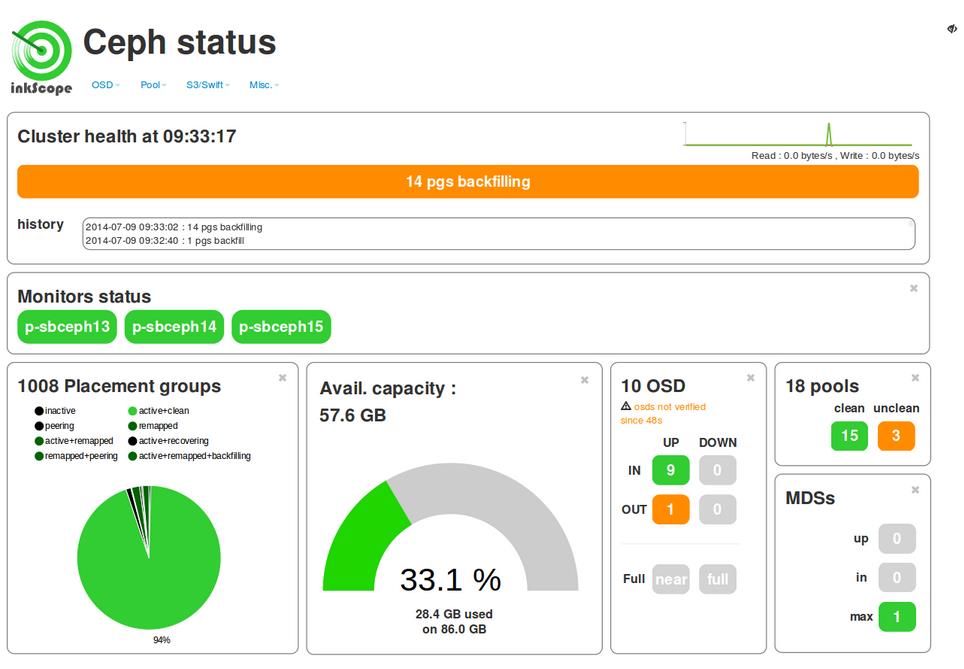
Calamari
Calamari : step-by-step
http://www.tuicool.com/articles/MZBjy22配置过程,非常好的参考文档
https://www.gitbook.com/book/zphj1987/calamaribook/details

12 ceph benchmark 测试
Ceph RADOS bench
测试
rados bench -p rbd 10 write --no-cleanup
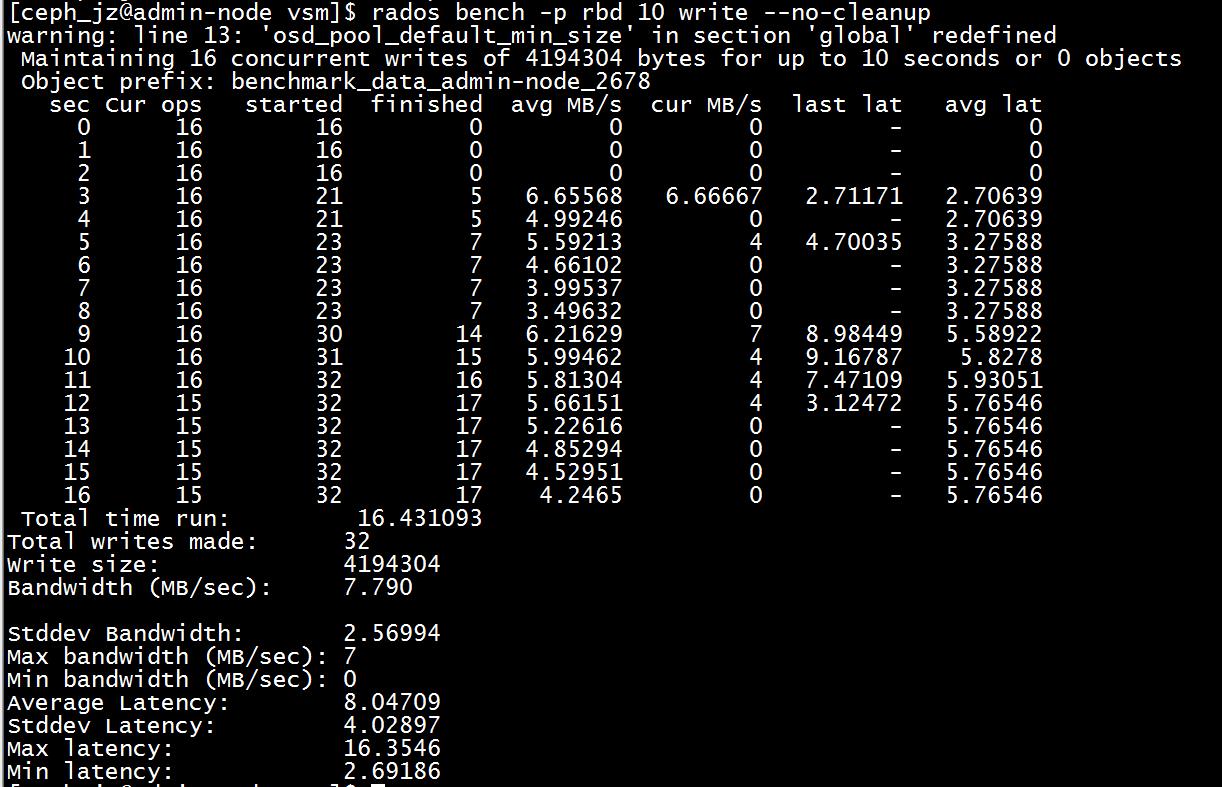
测试
rados bench -p rbd 10 write --no-cleanup
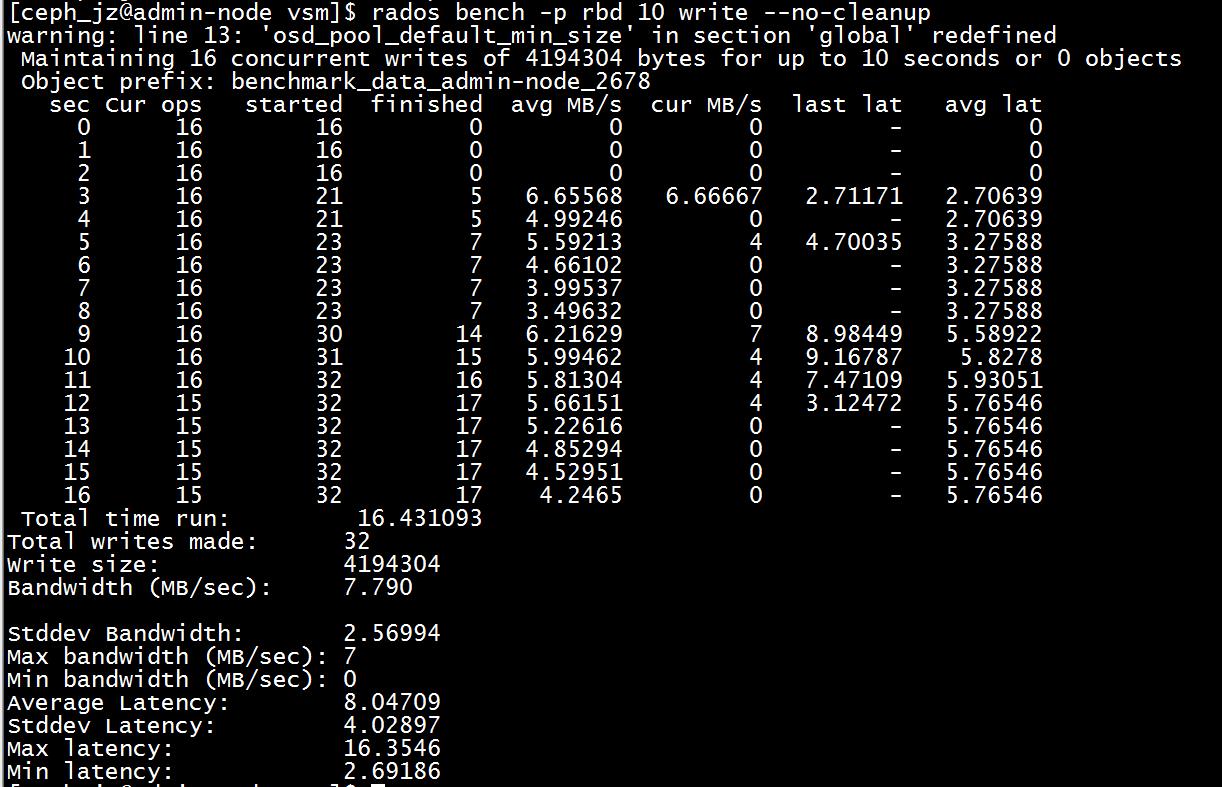
测试随机读写
rados bench -p ceph_bloc 10 rand
删除监视器 直接在主节点执行
sudo ceph mon remove node2
13 其他说明
-ceph-deploy快速部署
主要参考官网 这里记录出现的问题
RuntimeError: NoSectionError: No section: ‘ceph’
执行yum remove ceph-release,据说是版本不兼容
RuntimeError: remote connection got closed, ensure requiretty is disabled for
-进入要部署的机器,执行如下命令 sudo visudo 把Defaults requiretty 修改为 Defaults:ceph !requiretty
如果改完还么起作用,说明免密码的没有配,执行如下
echo “ceph ALL = (root) NOPASSWD:ALL” | sudo tee /etc/sudoers.d/ceph
sudo chmod 0440 /etc/sudoers.d/ceph
以上是关于ceph总结的主要内容,如果未能解决你的问题,请参考以下文章