Scrapy 框架理解
Posted JasonLiu
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Scrapy 框架理解相关的知识,希望对你有一定的参考价值。
scrapy的架构图:
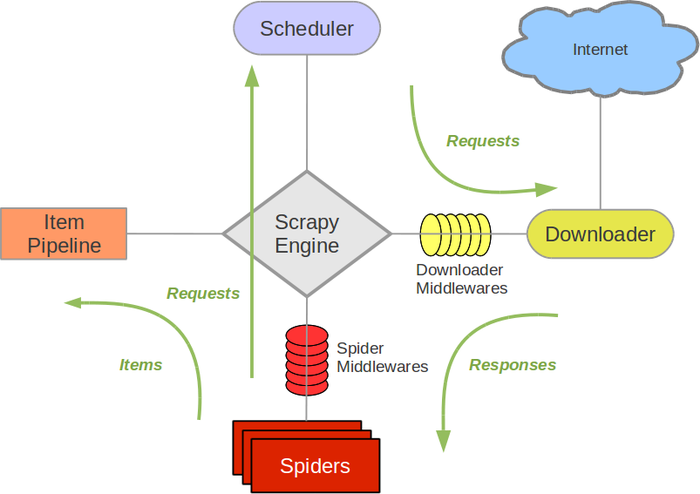
组件
Scrapy Engine
引擎负责控制数据流在系统中所有组件中流动,并在相应动作发生时触发事件。
调度器(Scheduler)
调度器从引擎接受request并将他们入队,以便之后引擎请求他们时提供给引擎。
下载器(Downloader)
下载器负责获取页面数据并提供给引擎,而后提供给spider。
Spiders
Spider是Scrapy用户编写用于分析response并提取item(即获取到的item)或额外跟进的URL的类。 每个spider负责处理一个特定(或一些)网站。 更多内容请看 Spiders 。
Item Pipeline
Item Pipeline负责处理被spider提取出来的item。典型的处理有清理、 验证及持久化(例如存取到数据库中)。 更多内容查看 Item Pipeline 。
下载器中间件(Downloader middlewares)
下载器中间件是在引擎及下载器之间的特定钩子(specific hook),处理Downloader传递给引擎的response(也包括引擎传递给下载器的Request)。 其提供了一个简便的机制,通过插入自定义代码来扩展Scrapy功能。更多内容请看 下载器中间件(Downloader Middleware) 。
一句话总结就是:处理下载请求部分
Spider中间件(Spider middlewares)
Spider中间件是在引擎及Spider之间的特定钩子(specific hook),处理spider的输入(response)和输出(items及requests)。 其提供了一个简便的机制,通过插入自定义代码来扩展Scrapy功能。更多内容请看 Spider中间件(Middleware) 。
一句话总结就是:处理解析部分
数据流(Data flow)
Scrapy中的数据流由执行引擎控制,其过程如下:
- 引擎打开一个网站(open a domain),找到处理该网站的Spider并向该spider请求第一个要爬取的URL(s)。
- 引擎从Spider中获取到第一个要爬取的URL并在调度器(Scheduler)以Request调度。
- 引擎向调度器请求下一个要爬取的URL。
- 调度器返回下一个要爬取的URL给引擎,引擎将URL通过下载中间件(请求(request)方向)转发给下载器(Downloader)。
- 一旦页面下载完毕,下载器生成一个该页面的Response,并将其通过下载中间件(返回(response)方向)发送给引擎。
- 引擎从下载器中接收到Response并通过Spider中间件(输入方向)发送给Spider处理。
- Spider处理Response并返回爬取到的Item及(跟进的)新的Request给引擎。
- 引擎将(Spider返回的)爬取到的Item给Item Pipeline,将(Spider返回的)Request给调度器。
- (从第二步)重复直到调度器中没有更多地request,引擎关闭该网站。
DownloaderMiddleware主要处理请求Request发出去和结果Response返回的一些回调,
比如说你要加UserAgent,使用代理,修改refferer,添加cookie,或者请求异常超时处理啥的
主要有几个方法:
process_request(request, spider)
当每个request通过下载中间件时,该方法被调用,这里可以修改UA,代理,Refferer
process_response(request, response, spider) 这里可以看返回是否是200加入重试机制
process_exception(request, exception, spider) 这里可以处理超时
SpiderMiddleware主要处理解析Item的相关逻辑修正,比如数据不完整要添加默认,增加其他额外信息等
process_spider_input(response, spider)当response通过spider中间件时,该方法被调用,处理该response。
rocess_spider_output(response, result, spider)
当Spider处理response返回result时,该方法被调用。
process_spider_exception(response, exception, spider)
当spider或(其他spider中间件的) process_spider_input() 跑出异常时, 该方法被调用。
#转载于https://blog.csdn.net/xnby/article/details/52297047 侵删
以上是关于Scrapy 框架理解的主要内容,如果未能解决你的问题,请参考以下文章
python网络爬虫实战-Scrapy,深入理解scrapy框架,解决数据抓取过程