如何基于 k8s 开发高可靠服务?容器云牛人有话说
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如何基于 k8s 开发高可靠服务?容器云牛人有话说相关的知识,希望对你有一定的参考价值。

?
?
k8s 是当前主流的容器编排服务,它主要解决「集群环境」下「容器化应用」的「管理问题」,主要包括如下几方面:
?
? 容器集群管理
- 编排?
- 调度?
- 访问?
? 基础设施管理
- 计算资源?
- 网络资源?
- 存储资源?
?
k8s 的强大依赖于它良好的设计理念和抽象,吸引了越来越多的开发者投入到 k8s 社区,把 k8s 作为基础设施运行服务的公司也逐步增多。
?
在设计理念方面,k8s 只有 APIServer 与 etcd (存储) 通信,其他组件在内存中维护状态,通过 APIServer 持久化数据。管理组件动作的触发是 level-based 而非 edge-based,并根据资源「当前状态」和「期望状态」进行相应动作。k8s 采用分层设计,基于各类抽象接口、由不同的插件满足不同的需求。
?
在抽象方面,不同的 workload 服务于不同的应用,如针对无状态应用的 Deployment、针对有状态应用的 StatefulSet 等。在访问管理方面,Service 解耦了集群内部服务访问方和提供者,Ingress 提供了集群外部到集群内部的访问管理。
?
k8s 虽然有良好的设计理念和抽象,但陡峭的学习曲线和不完善的开发资料极大增加了应用开发的难度。
?
本次分享将基于笔者的开发实践,以 mysql on k8s 为例,描述如何基于 k8s 开发高可靠应用,尽可能抽象出最佳实践,降低基于 k8s 开发高可靠应用的成本。
?
MySQL on k8s
?
应用的设计和开发不能脱离业务需求,对 MySQL 应用的需求如下:
- 数据高可靠?
- 服务高可用?
- 易使用?
- 易运维?
?
为了实现上述需求,需要依靠 k8s 和应用两方面协同工作,即开发基于 k8s 高可靠应用,既需要 k8s 相关的知识,也需要应用领域内的知识。
?
下述将根据上述需求来分析相应的解决方案。
1.数据高可靠
数据的高可靠一般依赖于这几方面:
- 冗余?
- 备份/恢复?
?
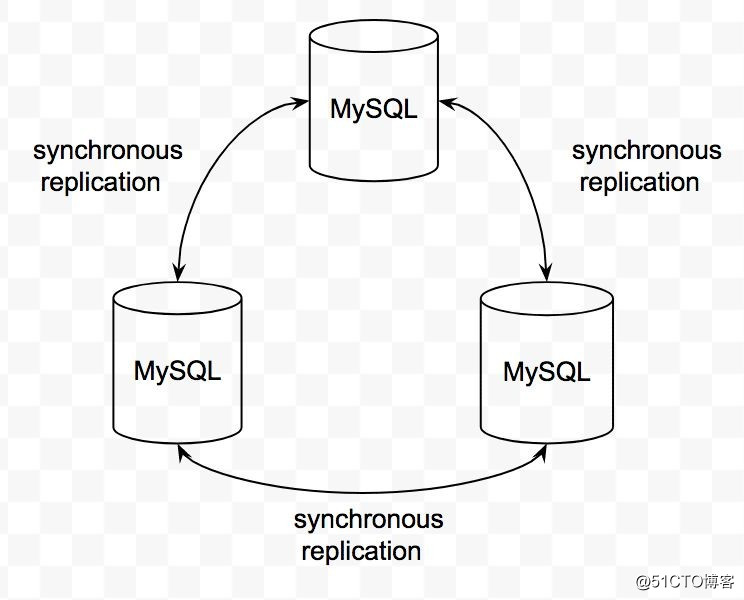
我们使用 Percona XtraDB Cluster 作为 MySQL 集群方案,它是 multi-master 的 MySQL 架构,实例间基于 Galera Replication 技术实现数据的实时同步。这种集群方案可以避免 master-slave 架构的集群在主从切换时可能出现的数据丢失现象,进一步提升数据的可靠性。
?
?
?
??备份方面,我们使用 xtrabackup 作为备份/恢复方案,实现数据的热备份,在备份期间不影响用户对集群的正常访问。
?
提供「定时备份」的同时,我们也提供「手动备份」,以满足业务对备份数据的需求。
?
2.服务高可用
?
这里从「数据链路」和「控制链路」两个角度来分析。
?
「数据链路」是用户访问 MySQL 服务的链路,我们使用 3 主节点的 MySQL 集群方案,通过 TLB (七牛自研的四层负载均衡服务) 对用户提供访问入口。TLB 既实现了访问层面对 MySQL 实例的负载均衡,又实现了对服务的健康检测,自动摘除异常的节点,同时在节点恢复时自动加入该节点。如下图:
?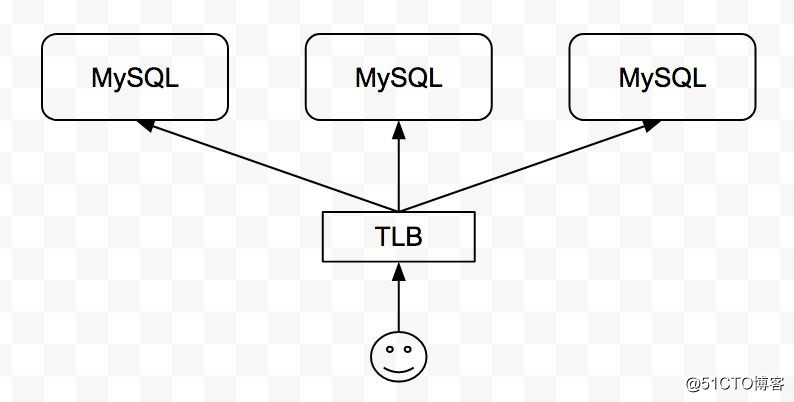
??基于上述 MySQL 集群方案和 TLB,一个或两个节点的异常不会影响用户对 MySQL 集群的正常访问,确保 MySQL 服务的高可用。
?
「控制链路」是 MySQL 集群的管理链路,分为两个层面: - 全局控制管理?
- 每个 MySQL 集群的控制管理
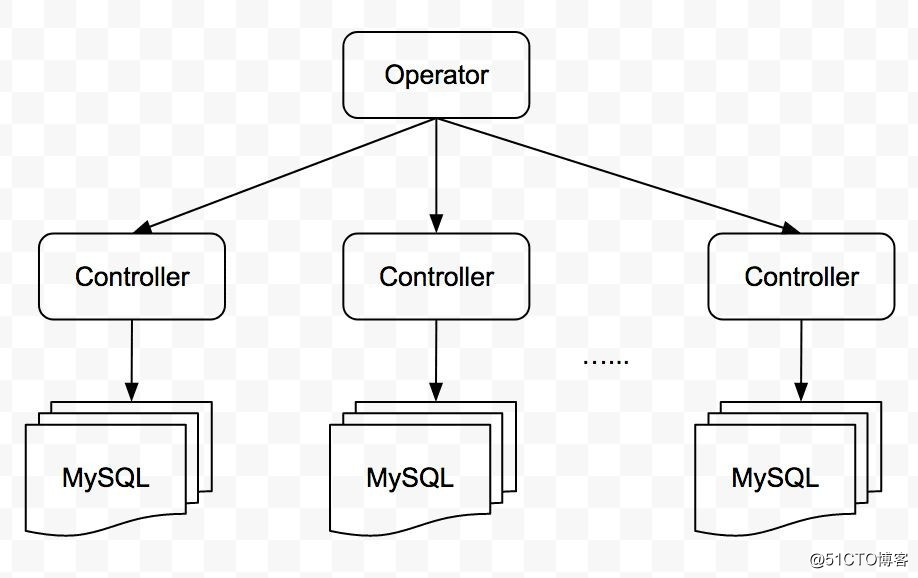
全局控制管理主要负责「创建/删除集群」「管理所有 MySQL 集群状态」等,基于 Operator 的理念来实现。每个 MySQL 集群有一个控制器,负责该集群的「任务调度」「健康检测」「故障自动处理」等。
?
这种拆解将每个集群的管理工作下放到每个集群中,降低了集群间控制链路的相互干扰,同时又减轻了全局控制器的压力。
如下图:
?
??这里简单介绍下 Operator 的理念和实现。
?
Operator 是 CoreOS 公司提出的一个概念,用来创建、配置、管理复杂应用,由两部分构成:
?
Resource
- 自定义资源?
- 为用户提供一种简单的方式描述对服务的期望?
?Controller- 创建 Resource?
- 监听 Resource 的变更,用来实现用户对服务的期望?
?
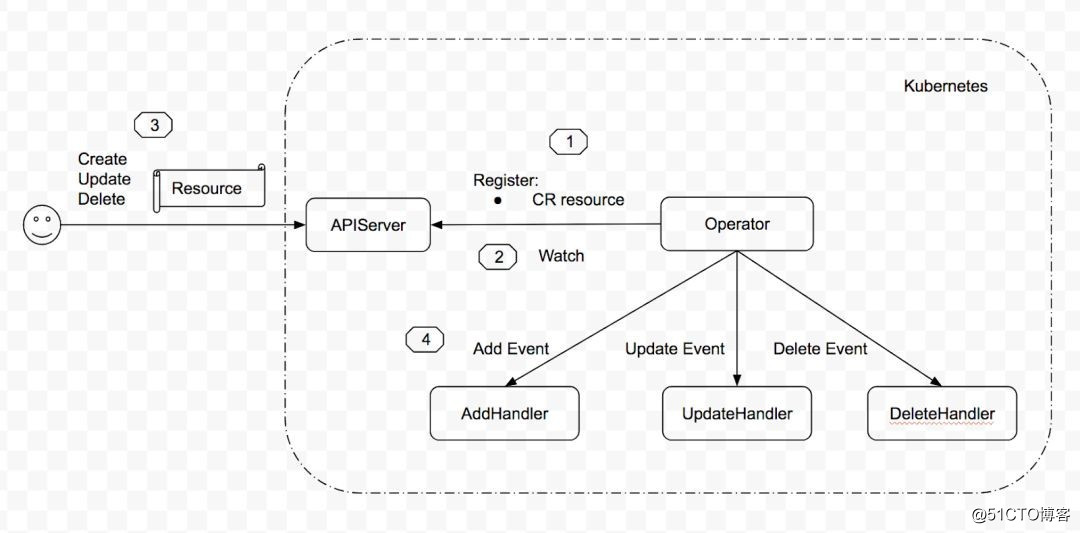
工作流程如下图所示:?
?
?
??即:
- 注册 CR (CustomResource) 资源?
- 监听 CR objects 的变更?
- 用户对该 CR 资源进行 CREATE/UPDATE/DELETE 操作?
- 触发相应的 handler 进行处理?
?
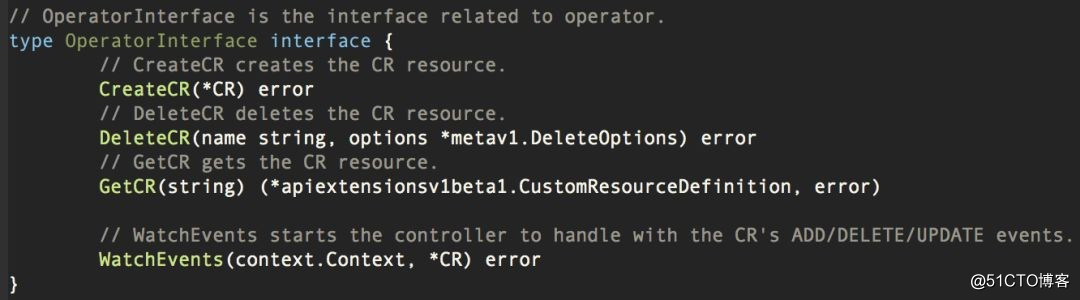
我们根据实践,对开发 Operator 做了如下抽象:
??
?
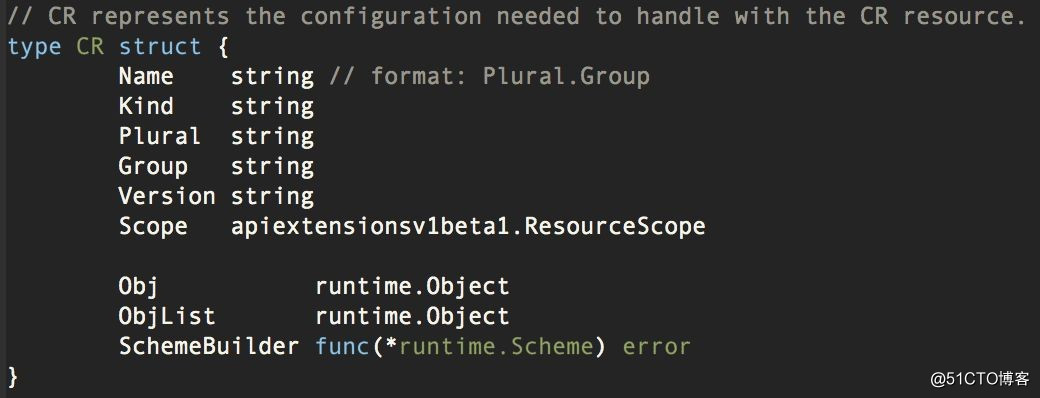
CR 抽象为这样的结构体:
??
?
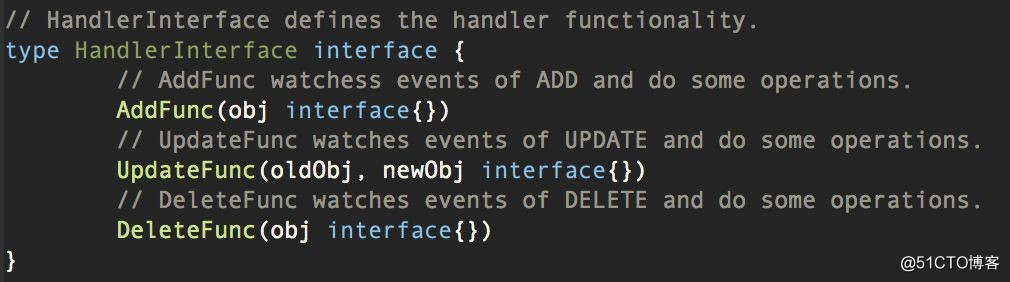
对 CR ADD/UPDATE/DELETE events 的操作,抽象为如下接口:
??
?
?
在上述抽象的基础上,七牛提供了一个简单的 Operator 框架,透明化了创建 CR、监听 CR events 等的操作,将开发 Operator 的工作变的更为简单。?
?
我们开发了 MySQL Operator 和 MySQL Data Operator,分别用来负责「创建/删除集群」和「手动备份/恢复」工作。
?
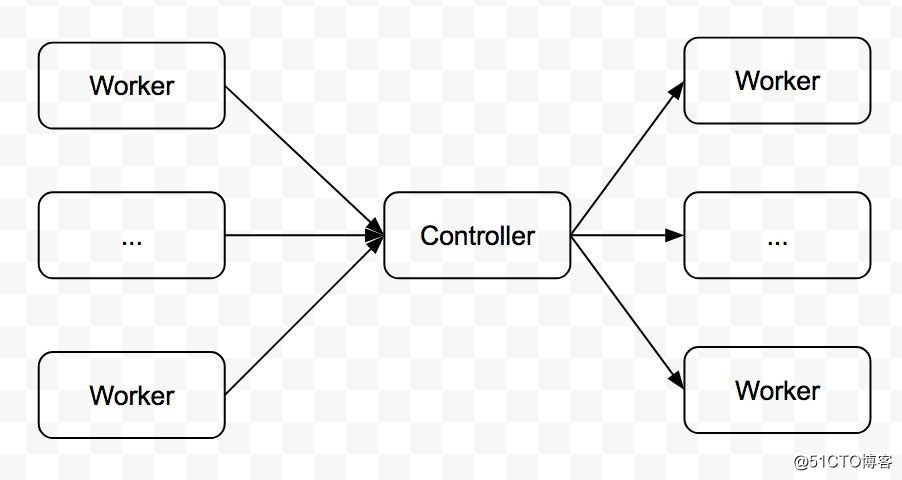
由于每个 MySQL 集群会有多种类型的任务逻辑,如「数据备份」「数据恢复」「健康检测」「故障自动处理」等,这些逻辑的并发执行可能会引发异常,故需要任务调度器来协调任务的执行,Controller 起到的就是这方面的作用:
?
??
通过 Controller 和各类 Worker,每个 MySQL 集群实现了自运维。
?
在「健康检测」方面,我们实现了两种机制:
? 被动检测?
? 主动检测???
「被动检测」是每个 MySQL 实例向 Controller 汇报健康状态,「主动检测」是由 Controller 请求每个 MySQL 实例的健康状态。这两种机制相互补充,提升健康检测的可靠度和及时性。
?
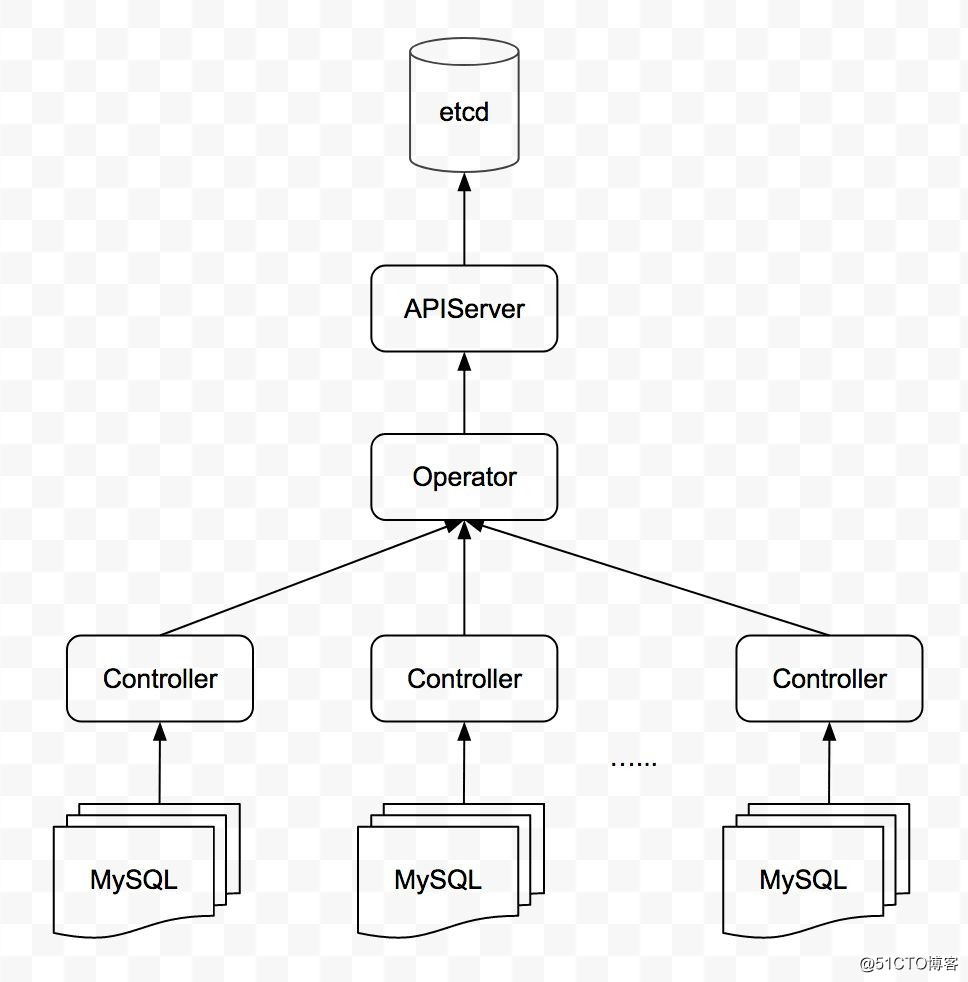
对于健康检测的数据,Controller 和 Operator 均会使用,如下图所示:
??
?
Controller 使用健康检测数据是为了及时发现 MySQL 集群的异常,并做相应的故障处理,故需要准确、及时的健康状态信息。它在内存中维护所有 MySQL 实例的状态,根据「主动检测」和「被动检测」的结果更新实例状态并做相应的处理。
?
Operator 使用健康检测数据是为了向外界反映 MySQL 集群的运行情况,并在 Controller 异常时介入到 MySQL 集群的故障处理中。
?
在实践中,由于健康检测的频率相对较高,会产生大量的健康状态,若每个健康状态都被持久化,那么 Operator 和 APIServer 均会承受巨大的访问压力。由于这些健康状态仅最新的数据有意义,故在 Controller 层面将待向 Operator 汇报的健康状态插入到一个有限容量的 Queue 中,当 Queue 满时,旧的健康状态将被丢弃。
?
当 Controller 检测到 MySQL 集群异常时,将会进行故障自动处理。
?
先定义故障处理原则:
? 不丢数据?
? 尽可能不影响可用性?
? 对于已知的、能够处理的故障进行自动处理?
? 对于未知的、不能够处理的故障不自动处理,人工介入???
在故障处理中,有这些关键问题:?
? 故障类型有哪些?
? 如何及时检测和感知故障?
? 当前是否出现了故障?
? 出现的故障是哪种故障类型?
? 如何进行处理???
针对上述关键问题,我们定义了 3 种级别的集群状态:
?Green
? 可以对外服务?
?运行节点数量符合预期?
Yellow
?可以对外服务?
?运行节点数量不符合预期?
Red
?不能对外服务?
?
同时针对每个 mysqld 节点,定义了如下状态:
?
Green
? 节点在运行?
? 节点在 MySQL 集群中?
Yellow?
? 节点在运行?
? 节点不在 MySQL 集群中?
Red-clean?
? 节点优雅退出?
Red-unclean?
? 节点非优雅退出?
Unknown?
? 节点状态不可知?
?
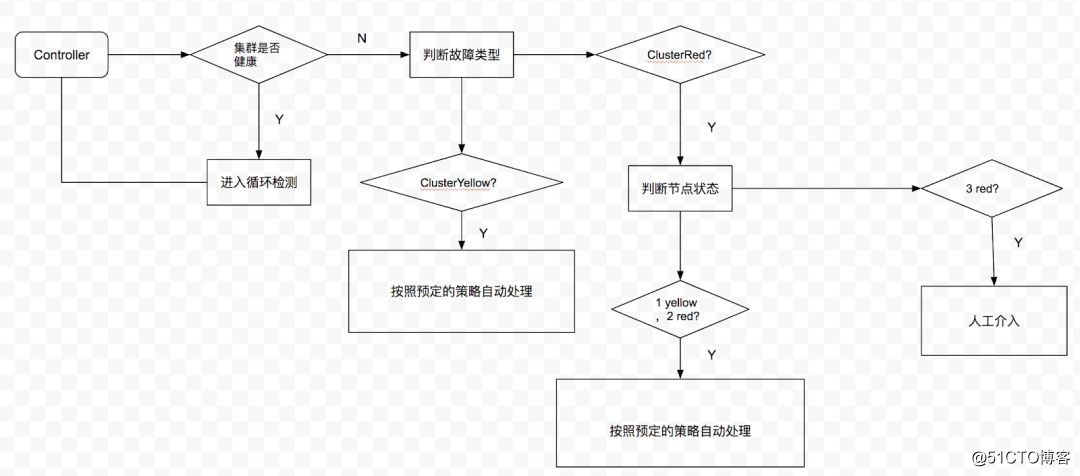
Controller 收集到所有 MySQL 节点状态后,会根据这些节点的状态推算 MySQL 集群的状态。当检测到 MySQL 集群状态不是 Green 时,会触发「故障处理」逻辑,该逻辑会根据已知的故障处理方案进行处理。若该故障类型未知,人工介入处理。整个流程如下图:
?
?
??由于每种应用的故障场景和处理方案不同,这里不再叙述具体的处理方法。
?
3.易使用
?
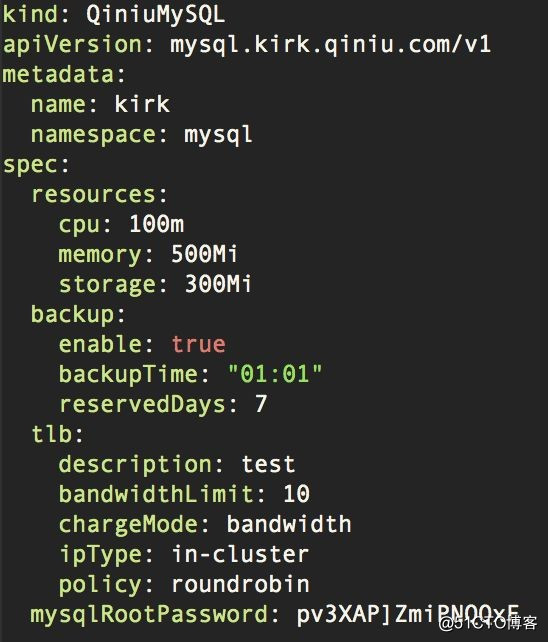
我们基于 Operator 的理念实现了高可靠的 MySQL 服务,为用户定义了两类资源,即 QiniuMySQL 和 QiniuMySQLData。前者描述用户对 MySQL 集群的配置,后者描述手动备份/恢复数据的任务,这里以 QiniuMySQL 为例。
?
用户可通过如下简单的 yaml 文件触发创建 MySQL 集群的操作:
??
?
?
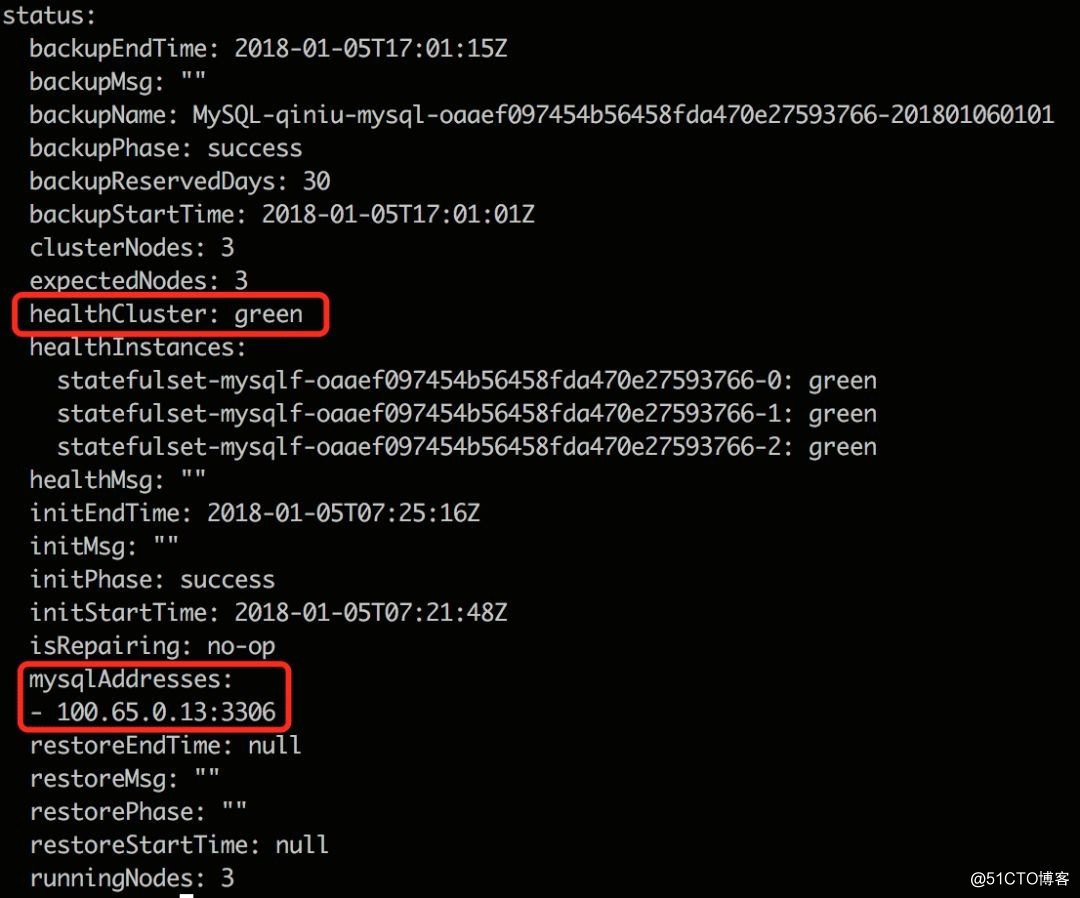
在集群创建好后,用户可通过该 CR object 的 status 字段获取集群状态:
??
?
这里再引入一个概念:Helm。?
?
Helm 是为 k8s 提供的包管理工具,通过将应用打包为 Chart,标准化了 k8s 应用的交付、部署和使用流程。
?
Chart 本质上是 k8s yaml 文件和参数文件的集合,这样可以通过一个 Chart 文件进行应用的交付。Helm 通过操作 Chart,可一键部署、升级应用。
?
由于篇幅原因及 Helm 操作的通用性,这里不再描述具体的使用过程。
?
4.易运维
?
除了上述实现的「健康检测」「故障自动处理」以及通过 Helm 管理应用的交付、部署,在运维过程中还有如下问题需要考虑:
? 监控/告警?
? 日志管理?
?
我们通过 prometheus + grafana 做监控/告警服务,服务将 metric 数据以 HTTP API 暴露给 prometheus,由 prometheus server 定时拉取。开发人员在 grafana 上将 prometheus 中的监控数据可视化,根据对监控图表和应用的把握,在监控图中设置告警线,由 grafana 实现告警。
?
这种先可视化监控后告警的方式,极大程度上增强了我们对应用运行特征的把握,明确需要关注的指标和告警线,降低无效告警的产生量。
?
在开发中,我们通过 gRPC 实现服务间的通信。在 gRPC 生态系统中,有个名为 go-grpc-prometheus 的开源项目,通过在服务中插入几行简单的代码,就可以实现对 gRPC server 所有 rpc 请求的监控打点。
?
对于容器化服务,日志管理包括「日志收集」和「日志滚动」两方面维度。
?
我们将服务日志打到 syslog 中,再通过某种手段将 syslog 日志转入到容器的 stdout/stderr 中,方便外部采用常规的方式进行日志收集。同时,在 syslog 中配置了 logrotate 功能,自动进行日志的滚动操作,避免日志占满容器磁盘空间引发服务异常。
?
为了提升开发效率,我们使用?https://github.com/phusion/baseimage-docker?作为基础镜像,其中内置了 syslog 和 lograte 服务,应用只关心把日志打入 syslog 即可,不用关心日志的收集和日志滚动问题。
?
小结
?
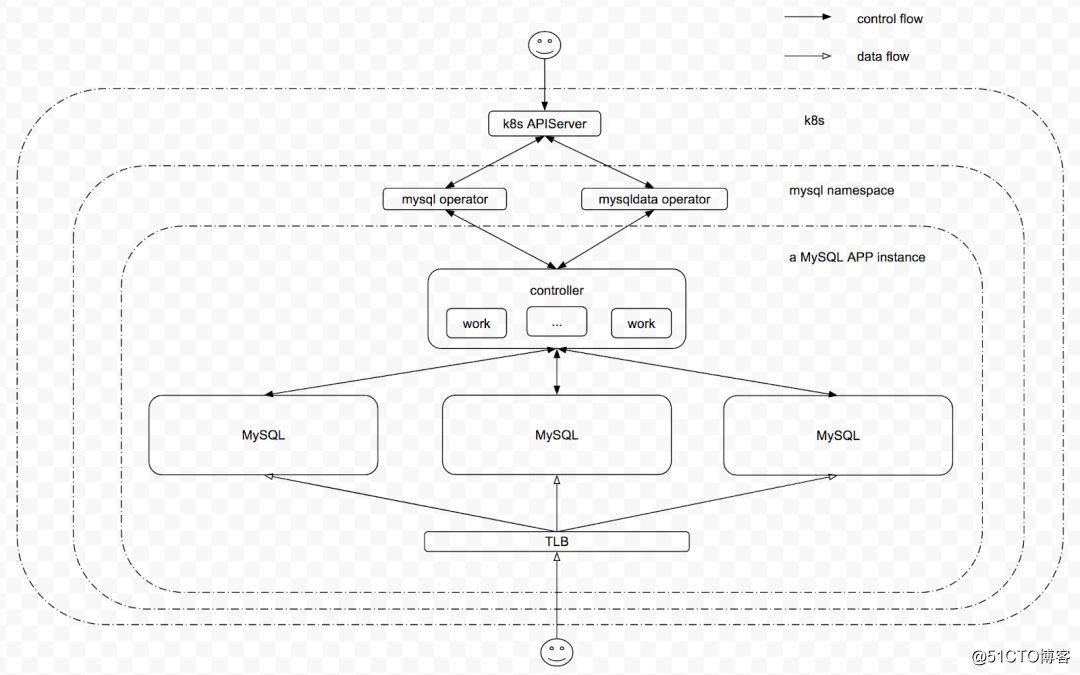
通过上述描述,完整的 MySQL 应用架构如下:
?
?
??在开发基于 k8s 的高可靠 MySQL 应用过程中,随着对 k8s 和 MySQL 理解的深入,我们不断进行抽象,逐步将如下通用的逻辑和最佳实践以模块的方式实现:
- Operator 开发框架?
- 健康检测服务?
- 故障自动处理服务?
- 任务调度服务?
- 配置管理服务?
- 监控服务?
- 日志服务?
- etc.???
随着这些通用逻辑和最佳实践的模块化,在开发新的基于 k8s 的高可靠应用时,开发者可像「搭积木」一样将与 k8s 相关的交互快速搭建起来,这样的应用由于已经运用了最佳实践,从一开始就具备高可靠的特性。同时,开发者可将注意力从 k8s 陡峭的学习曲线转移到应用自身领域,从应用自身加强服务的可靠性。
?
牛人说
?
牛人说专栏致力于技术人思想的发现,其中包括技术实践、技术干货、技术见解、成长心得,还有一切值得被发现的技术内容。我们希望集合最优秀的技术人,挖掘独到、犀利、具有时代感的声音。
?
?
以上是关于如何基于 k8s 开发高可靠服务?容器云牛人有话说的主要内容,如果未能解决你的问题,请参考以下文章