hive 的功能和架构
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了hive 的功能和架构相关的知识,希望对你有一定的参考价值。
- Hive 能做什么,与mapreduce 相比优势在哪里(相对于开发)
- 为什么说Hive 是Hadoop 的数据仓库,从【数据存储和分析】 方面理解
- Hive 架构,分为三个部门来理解,画图理解
1.Hive 能做什么,与mapreduce 相比优势在哪里(相对于开发)
1.1.hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供简单的sql查询功能,可以将sql语句转换为MapReduce任务进行运行。 相对于mapreduce 离线计算需要写很多java代码去实现数据提取,hive可以通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用开发程序,更适合数据仓库的统计分析。2. 为什么说Hive 是Hadoop 的数据仓库,从【数据存储和分析】 方面理解
2.1. Hive是建立在 Hadoop 上的数据仓库基础构架。它提供了一系列的工具,可以用来进行数据提取转化加载(ETL),这是一种可以存储、查询和分析存储在 Hadoop 中的大规模数据的机制。Hive 定义了简单的类 SQL 查询语言,称为 HQL,它允许熟悉 SQL 的用户查询数据。同时,这个语言也允许熟悉 MapReduce 开发者的开发自定义的 mapper 和 reducer 来处理内建的 mapper 和 reducer 无法完成的复杂的分析工作。**可以将SQL 查询转换为MapReduce 的job 在Hadoop集群上执行。**
2.2 Hive 没有专门的数据存储格式,也没有为数据建立索引,用户可以非常自由的组织 Hive 中的表,只需要在创建表的时候告诉 Hive 数据中的列分隔符和行分隔符,Hive 就可以解析数据.Hive 中所有的数据都存储在 HDFS 中,Hive 中包含以下数据模型:**表(Table),外部表(External Table),分区(Partition),桶(Bucket)。**
2.3 Hive 中的 Table 和数据库中的 Table 在概念上是类似的,每一个 Table 在 Hive 中都有一个相应的目录存储数据。例如,一个表 pvs,它在 HDFS 中的路径为:/wh/pvs,其中,wh 是**在 hive-site.xml 中由 ${hive.metastore.warehouse.dir} 指定的数据仓库的目录**,所有的 Table 数据(不包括 External Table)都保存在这个目录中。
Partition 对应于数据库中的 Partition 列的密集索引,但是 Hive 中 Partition 的组织方式和数据库中的很不相同。在 Hive 中,表中的一个 Partition 对应于表下的一个目录,**所有的 Partition 的数据都存储在对应的目录中**。例如:pvs 表中包含 ds 和 city 两个 Partition,则对应于 ds = 20090801, ctry = US 的 HDFS 子目录为:/wh/pvs/ds=20090801/ctry=US;对应于 ds = 20090801, ctry = CA 的 HDFS 子目录为;/wh/pvs/ds=20090801/ctry=CA
**Buckets 对指定列计算 hash,根据 hash 值切分数据,目的是为了并行,每一个 Bucket 对应一个文件。**将 user 列分散至 32 个 bucket,首先对 user 列的值计算 hash,对应 hash 值为 0 的 HDFS 目录为:/wh/pvs/ds=20090801/ctry=US/part-00000;hash 值为 20 的 HDFS 目录为:/wh/pvs/ds=20090801/ctry=US/part-000203.Hive 架构,分为三个部门来理解,画图理解
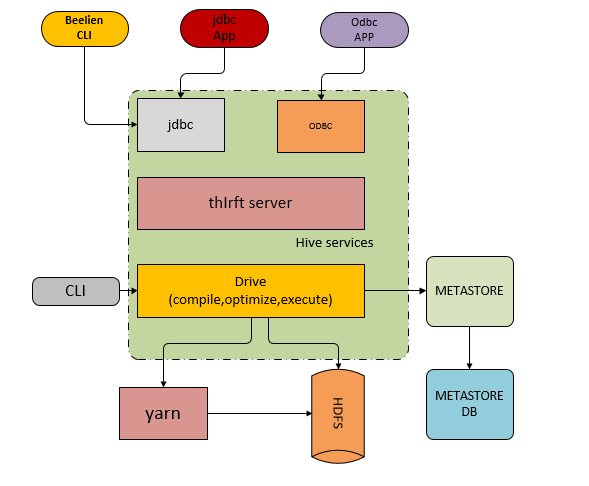
3.1 用户接口
用户接口主要有三个:CLI,Client 和 WUI。其中最常用的是 CLI,Cli 启动的时候,会同时启动一个 Hive 副本。Client 是 Hive 的客户端,用户连接至 Hive Server。在启动 Client 模式的时候,需要指出 Hive Server 所在节点,并且在该节点启动 Hive Server。 WUI 是通过浏览器访问 Hive。
3.2 元数据存储
Hive 将元数据存储在数据库中,如 mysql、derby。Hive 中的元数据包括表的名字,表的列和分区及其属性,表的属性(是否为外部表等),表的数据所在目录等。
3.3 解释器、编译器、优化器、执行器
解释器、编译器、优化器完成 HQL 查询语句从词法分析、语法分析、编译、优化以及查询计划的生成。生成的查询计划存储在 HDFS 中,并在随后由 MapReduce 调用执行。
以上是关于hive 的功能和架构的主要内容,如果未能解决你的问题,请参考以下文章