Hive初识功能架构
Posted 正义飞
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hive初识功能架构相关的知识,希望对你有一定的参考价值。
hadoop,spark,kafka交流群:224209501
kafka源码,hbase源码,spark源码请关注浪尖公众号
本节讲述的主要内容为:
1) Hive 能做什么,与MapReduce相比优势在哪里(对于开发者)
2) 为什么说Hive是Hadoop 数据仓库,从【数据存储和分析】方面理解
3) Hive 架构,分为三个部分来理解,最好通过画图理解
1,hive PK mapreduce。
1.1 mapreduce的缺点
(1).MapReduce 格式比较固定。
【八股文】格式编程,三大部分组成
(2).No Schema(数据库中的Schema,为数据库对象的集合,一个用户一般对应一个schema。),缺少查询语言,比如SQL。
- 数据分析,针对DBA、SQL语句,如何进行数据分析。
- MapReduce编程成本高。
- 因此facebook,实现并开源了hive。
1.2 hive的优点
(1).操作接口采用类SQL语法,提供快速开发能力(简单、容易上手);
(2).避免去写mapreduce,减少开发人员的学习成本;
(3).统一的元数据管理,可与implela/spark等共享元数据;
(4).易扩展(HDFS+MapReduce:可以扩展集群规模;支持自定义函数);
(5).数据的离线处理;比如:日志分析,海量结构数据离线分析。
(6).hive执行延迟比较高,因此hive常用于数据分析的,对实时性要求不高的场合;
(7).hive优势在于处理大数据,对于处理小数据没有 优势,因为hive的执行延迟比较高。
2,hive是hadoop的数据仓库
hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供简单的sql查询功能,可以将sql语句转换为MapReduce任务进行运行。其优点是学习成本低,可以通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析。它提供了一系列的工具,可以用来进行数据提取转化加载(ETL),这是一种可以存储、查询和分析存储在 Hadoop中的大规模数据的机制。
(1).hive由FaceBook开源用于解决海量结构化日志的数据统计。
(2).hive是基于hadoop的一个数据仓库工具,可以将结构化的数据文件映射成一张表,并提供类SQL查询功能。
(3).hive是构建在hadoop之上的数据仓库:
- 使用HQL语句作为查询接口
- 使用HDFS进行存储
- 使用mapreduce进行计算。
(4).hive本质是:将HQL转化成MapReduce程序。
(5).灵活和扩展性比较好:支持UDF,自定义存储格式。
(6).适合离线处理。
(7).查询和管理在分布式存储的大的数据集(数据库:增删改查,hive不支持增删该)。管理主要是对表的管理。
3,hive架构理解
hive在hadoop生态系统中的位置:
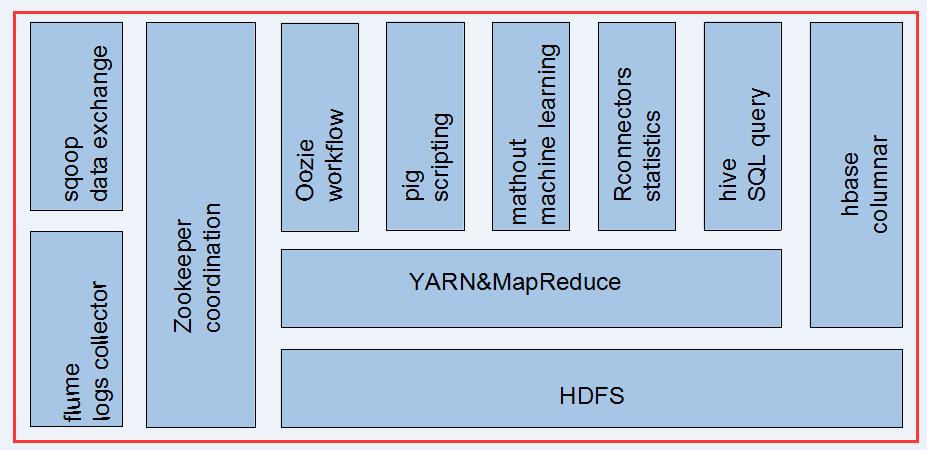
hive框架图:
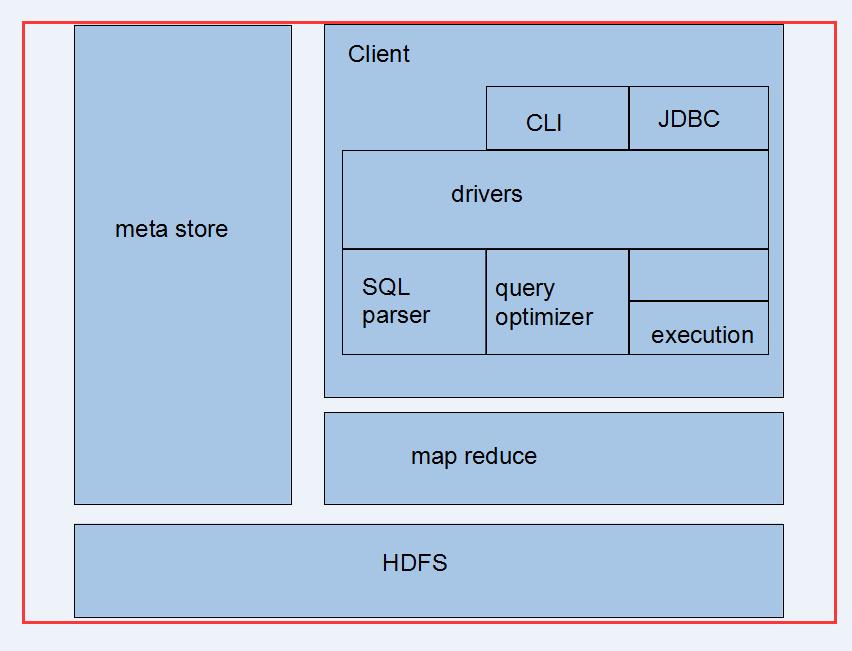
hive执行流程:

3.1 用户接口:client
CLI(hive shell)、JDBC/ODBC(java访问hive),WEBUI(浏览器访问hive)
3,2 元数据:metastore
元数据包括:表名、表所属的数据库(默认是default)、表的拥有者、列/分区字段、表的类型(是否是外部表)、表的数据所在目录等;
默认存储在自带的derby数据库中,推荐采用mysql存储metastore;
3,3 hadoop
使用HDFS进行存储,使用mapreduce进行计算
3.4 驱动器:driver
驱动器包含:解析器、编译器、优化器、执行器。
(1).解析器:
强SQL字符串转换成抽象语法树AST,这一步一般都用第三方工具完成,比如antlr;对AST进行语法分析,比如表是否存在、字段是否存在、SQL语义是否有误(比如select中被判定为聚合的字段在group by中是否出现).
(2).编译器
将AST编译生成逻辑执行计划。
(3).优化器
对逻辑执行计划进行优化。
(4).执行器。
把逻辑执行计划转换成可以运行的物理计划。对于hive来说,就是MR/TEZ/Spark。
3.5,hive与关系型数据库的区别。
(1).hive和关系数据库存储文件的系统不同,hive使用的是hadoop的HDFS(hadoop的分布式文件系统),关系数据库则是服务器本地的文件系统;
(2).hive使用的计算模型是mapreduce,而关系数据库则是自己设计的计算模型;
(3).关系数据库都是为实时查询的业务进行设计的,而hive则是为海量数据做数据挖掘设计的,实时性很差;实时性的区别导致hive的应用场景和关系数据库有很大的不同;
(4).Hive很容易扩展自己的存储能力和计算能力,这个是继承hadoop的,而关系数据库在这个方面要比数据库差很多。
以上是关于Hive初识功能架构的主要内容,如果未能解决你的问题,请参考以下文章