sklearn之交叉检验1
Posted 风吹白杨的安妮
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了sklearn之交叉检验1相关的知识,希望对你有一定的参考价值。
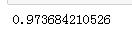
#下面是只是普通的,仅一次 from sklearn.datasets import load_iris from sklearn.model_selection import train_test_split from sklearn.neighbors import KNeighborsClassifier iris = load_iris() X = iris.data y = iris.target X_train,X_test,y_train,y_test = train_test_split(X,y,random_state=4) knn = KNeighborsClassifier(n_neighbors=5)#附近点的5个值 knn.fit(X_train,y_train) print(knn.score(X_test,y_test))
#下面开始交叉检验 #调用形式为:sklearn.cross_validation.cross_val_score from sklearn.cross_validation import cross_val_score knn = KNeighborsClassifier(n_neighbors=5) #socring是判断准确度的方法 scores = sklearn.cross_validation.cross_val_score(knn,X,y,cv=5,scoring=\'accuracy\') #如果是回归的话,scoring=\'mean_squared_error\',判断误差,要在前面加负号, #即loss = -sklearn.cross_validation.cross_val_score(knn,X,y,cv=5,scoring=\'mean_squared_error\') print(scores) #有两组到了100的境界,cv指的是分成几个set
#我们可以把它们平均一下 print(scores.mean())
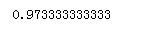
#现在我想看一下,n_neighbors为多少对结果有什么影响 import matplotlib.pyplot as plt from sklearn.datasets import load_iris iris = load_iris() X = iris.data y = iris.target k_range = (1,31) k_scores = [] for k in k_range: knn = KNeighborsClassifier(n_neighbors=k) scores = sklearn.cross_validation.cross_val_score(knn,X,y,cv=10,scoring=\'accuracy\') k_scores.append(scores.mean()) plt.plot(k_range,k_scores) plt.xlabel(\'Value of K for KNN\') plt.ylabel(\'Cross-Validated Accuracy\') plt.show()
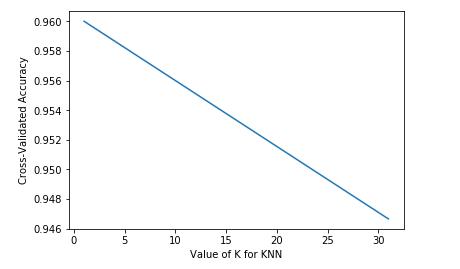
感觉上面这个线怪怪的啊,我得想一想。。。。。
以上是关于sklearn之交叉检验1的主要内容,如果未能解决你的问题,请参考以下文章
sklearn库学习----随机森林(RandomForestClassifier,RandomForestRegressor)