交叉验证——Cross-validation
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了交叉验证——Cross-validation相关的知识,希望对你有一定的参考价值。
参考技术A 交叉验证是建立模型后进行参数调整和模型检验的一个步骤。本文就sklearn自带的鸢尾花数据集,进行基本的建模思路整理和交叉验证梳理。注:
鸢尾花案例的背景是,通过已知(历史)花的数据和对应的分类,训练出模型结果,从而得到分类模型。
实现效果是可以预测鸢尾花的分类。
交叉验证的基本思想是在某种意义下将原始数据(dataset)进行分组,一部分做为训练集(train set),另一部分做为验证集(validation set or test set),首先用训练集对分类器进行训练,再利用验证集来测试训练得到的模型(model),以此来做为评价分类器的性能指标。
而对一个数据集进行多次(cv)交叉验证,并对每一次的得分求平均得到最客观的评价分数可以作为最终评分。
因此,它的作用就是:用于参数调整和模型选择/评价。
0.9736842105263158
0.9733333333333334
该结果接近满分,说明模型分类效果较好。可以采用该模型。
KNN算法中k值的大小,代表分类时考虑训练数据点周围的数据点的个数。不同的k的取值,分类结果不同。我们可以用循环的方法对k进行循环,根据不同k值对应的得分(上述交叉验证的评价得分)决定k的取值,从而确定最终的模型和模型评价。
上图是以准确度为评价标准,k从1~31对应的score的值
这组数据选择12~18至间的数字会比较好。
上图是用平均方差值来作为评价标准(越接近0说明拟合效果越好),k选择13~18是比较合适的。
(回归模型的评价一般用R^2 值来判断,R^2越接近1,也就是误差平方和越接近0,拟合效果越好)
上述两个不同评价标准下的数值是调参的过程,可以由此定下k的值,从而确定模型。
交叉验证Cross-Validation
PRML中首章绪论的模型选择,提到两个方法:
1、交叉验证(Cross-Validation)
2、赤池信息准则(Akaike Information Criterion),简称:AIC。
交叉验证是模型选择的一种方法,若有模型选择问题,就可以用交叉验证。例如做线性回归,你有 10 个变量,就有 (2的10次方=)1024 个模型需要选择,就可以使用交叉验证 或者 AIC。
使用交叉验证是从预测的角度去做,使用 AIC 是从模型的复杂度与模型的拟合角度去做。
交叉验证:
(ref-baidu :在给定的建模样本中,拿出大部分样本进行建模型,留小部分样本用刚建立的模型进行预报,并求这小部分样本的预报误差,记录它们的平方加和。)
如果模型的设计使用有限规模的数据集迭代很多次,那么对于验证数据会发生一定程度的过拟合,因此保留一个第三方的测试集是很有必要的。
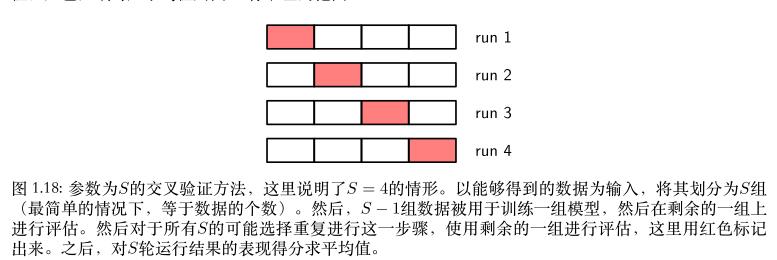
例如一个 “五折交叉验证”,
将数据划分为5组,分别为 G1、G2、G3、G4、G5。
① 取G1组作为测试组,其余4组作为训练组;
② 取G2组作为测试组,其余4组作为训练组;
③ 取G3组作为测试组,其余4组作为训练组;
④ 取G4组作为测试组,其余4组作为训练组;
⑤ 取G5组作为测试组,其余4组作为训练组。
对5轮运行结果的表现得分求平均值。
以上是关于交叉验证——Cross-validation的主要内容,如果未能解决你的问题,请参考以下文章