Sklearn的datasets数据库
Posted 风吹白杨的安妮
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Sklearn的datasets数据库相关的知识,希望对你有一定的参考价值。
from sklearn import datasets from sklearn.linear_model import LinearRegression #来导入sklearn提供的波士顿房价的数据 loaded_data = datasets.load_boston() X_data = loaded_data.data y_data = loaded_data.target model = LinearRegression() #模型用线性回归哟 model.fit(X_data,y_data) #先显示前面4个 print(model.predict(X_data[:4,:])) print(y_data[:4])
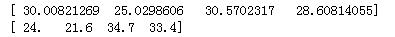
Sklearn还允许我们自己创造一些数据
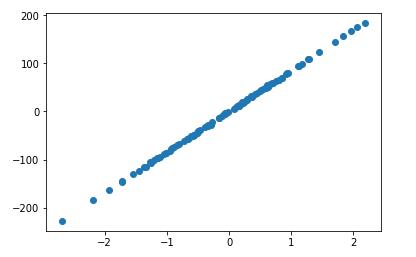
X,y = datasets.make_regression(n_samples=100,n_features=1,n_targets=1,noise=1) #有100个样本,特征一个,目标变量一个,来玩画图
import matplotlib.pyplot as plt #画X,y的散点图咯 plt.scatter(X,y) plt.show()
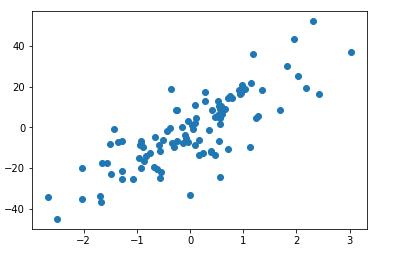
#把noise变大点,会更加离散,例如noise=10 X,y = datasets.make_regression(n_samples=100,n_features=1,n_targets=1,noise=10) plt.scatter(X,y) plt.show()
#我们可以查看该线性回归方程的参数 print(model.coef_) print(model.intercept_)

#显示对model定义的参数 print(model.get_params())
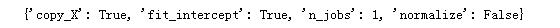
#对mdel学到的东西进行一个评分,X_data是用来预测的,y_data是用来比较的 print(model.score(X_data,y_data)) #74%的数据是吻合的
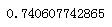
以上是关于Sklearn的datasets数据库的主要内容,如果未能解决你的问题,请参考以下文章
如何使用 sklearn.datasets.load_files 加载数据百分比
sklearn中决策树算法DesiciontTreeClassifier()调用以及sklearn自带的数据包sklearn.datasets.load_iris()的应用