Apache顶级项目介绍6 - Spark
Posted erixhao
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Apache顶级项目介绍6 - Spark相关的知识,希望对你有一定的参考价值。

火花四溢,热情洋溢。极客朋友么知道,我们翘首以盼的Spark来了。
提及Spark, 这几年如日中天,谈到大数据如果不提及Spark, Hadoop,就好比这年代带耳机不是2B的,你都不好意思带。Spark最初由加州大学伯克利分校(太屌的大学,出了多少名人,名作啊)的AMPLab Matei为主的小团队使用Scala开发,其核心代码只有63个Scala文件(早期版本,这里提及一下Scala语言又是一个创时代的大作,有人说它太锋利,有人说它太妖魔)。
Spark作者Matei:

Spark于2010年才成为Apache开源项目之一。经过短短几年的发展,尤其是在2014年很多知名重量级公司如IBM, Cloudera等大力支持,到如今已经是登峰造极,在大数据并行计算,MapReduce领域,完全无人能及其只右,甚至已然代替了Hadoop的MapReduce模块,以及到后来Hadoop也只好把Spark作为其生态重要的一部分作为介绍。
老样子,看看Spark官方如何介绍吧:
Spark官网是作者比较喜欢的风格,虽说没有后来Docker那么cool,但简单,清新,美观,有图有真相,显然看起来是一个产品,不像Hadoop的官网,这个...
Spark是一个高速,通用大数据计算处理引擎。简单明了,低调中包涵了野心。
官网继续介绍亮点:
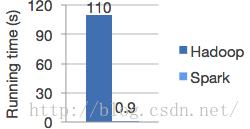
1. 速度快,Spark直接上数据,超过Hadoop内存MapReduce速度100+以上,又或者磁盘MapReduce速度10+以上。why?Spark拥有高级DAG(有向无环图)引擎支持数据循环利用,多步数据管道以及in-memory computing。
其实Spark用到了减少IO以及其精华RDD。其实我们在上一篇介绍Hadoop的时候提到了虽然MR v2解决了MR v1的一些问题,但是由于其对HDFS的频繁操作(包涵了计算临时结果持久化,数据备份以及shuffle等)导致了磁盘I/O成为系统瓶颈,因而只适用于离线数据处理,无法支持大规模实时数据处理能力,从而也为其埋下了重大隐患,被Spark乘胜追击。
2.易用性,支持Java, Scala, Python, R. 简单,高效。还记得我们介绍
hadoop的时候提到案例word count,spark只用下面2行甚至可以简化到1行代码就实现hadoop几十,上百行的功能,不得感慨其之强大,这里提一下之所以着么简单是得益于函数式编程以及RDD.

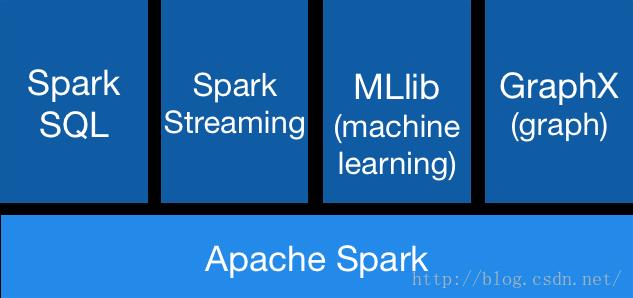
3.功能强大,涵盖数据各个领域: SQL, Streaming, Analytics, Machine
Learning, Graph X, 野心勃勃,一统大数据江山。
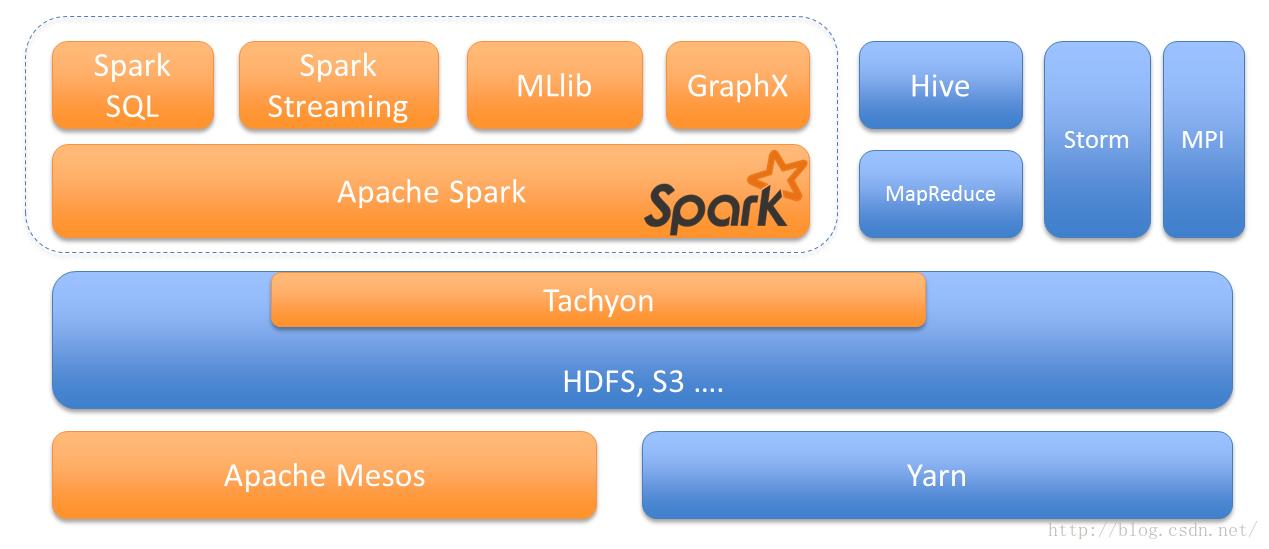
4.兼容各大生态圈,可以运行在Hadoop, Mesos单机或者云端。同时支持访问多种多样的数据源:HDFS, Cassandra, HBase, S3.

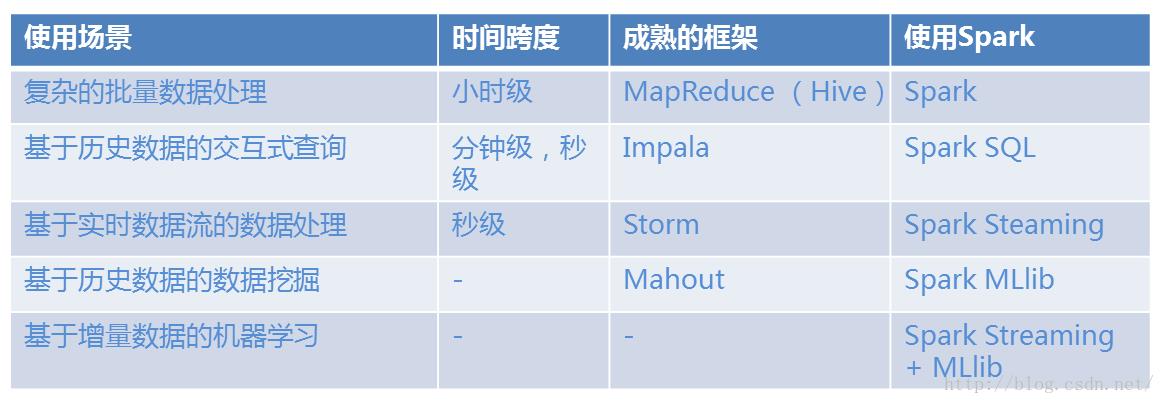
可以看出,Spark的团队除了包涵技术大拿,还有顶级的宣传广告达人,看完了这些介绍,你想不用Spark都难。换句话说,Spark提供了一站式大数据解决方案:
Spark目前官方稳定版本为1.6于2016年3月9日发布,当然激动人心的大版本2.x正在紧锣密鼓中,我们下面也会提到其新特性。
下面开始介绍一些核心模块。
架构图如下:
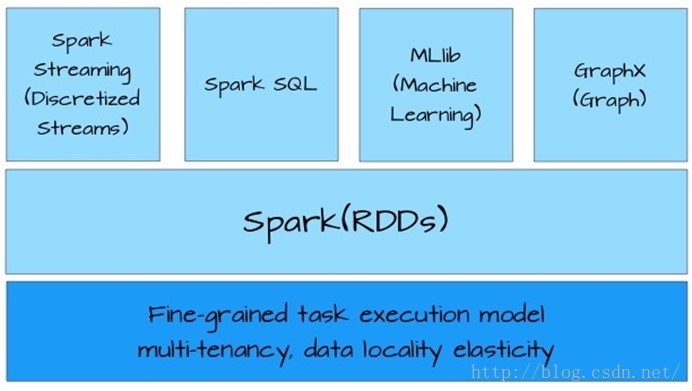
如果我们在缩放一下的化看spark的设计架构:
 RDD(Resilient Distributed Dataset):
RDD(Resilient Distributed Dataset):
以上是关于Apache顶级项目介绍6 - Spark的主要内容,如果未能解决你的问题,请参考以下文章