数据说明
数据来源:http://archive.ics.uci.edu/ml/datasets/Bike+Sharing+Dataset
数据说明:仅使用day.csv文件
字段说明:Instant记录号
Dteday:日期
Season:季节
1=春天 2=夏天 3=秋天 4=冬天
yr:年份(0: 2011, 1:2012)
mnth:月份( 1 to 12)
holiday:是否是节假日
weekday:星期中的哪天,取值为 0~6
workingday:是否工作日 1=工作日 (非周末和节假日) 0=周末
weathersit:天气 1:晴天,多云 2:雾天,阴天 3:小雪,小雨 4:大雨,大雪,大雾
temp:气温摄氏度
atemp:体感温度
hum:湿度
windspeed:风速
cnt:给定日期(天)时间(每小时)总租车人数,响应变量 y
方式:用2011年的数据预测2012年的数据
数据导入与工具包导入
1 import numpy as np 2 import pandas as pd 3 import seaborn as sns 4 import matplotlib.pyplot as plt 5 from sklearn.metrics import r2_score 6 %matplotlib inline 7 8 data = pd.read_csv("Desktop/Bike-Sharing-Dataset/day.csv") 9 data.head()

特征casual,registered与cnt都是要预测的y,但因题目要求,所以去掉casual,registered两个特征。
特征中,instant为序号,dteday为日期,无法对cnt造成影响,所以也删掉这两个特征。
data = data.drop([‘instant‘,‘dteday‘,‘casual‘,‘registered‘],axis=1) data.head()
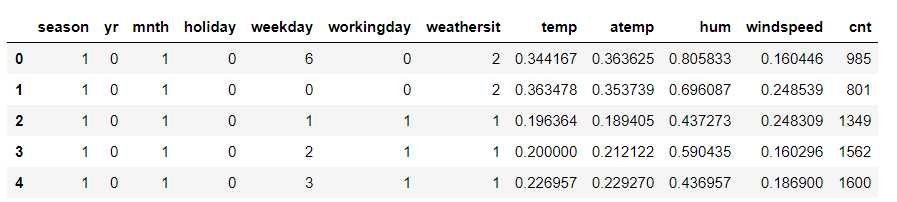
data.info()
数据中没有缺失值,因此不需要填补缺失值这一步。结合对数据前五行的观察,发现season,yr,mnth,holiday,weekday,workingday,weatherist均为分类特征,而其他包括目标cnt在内的其他特征均为数值型特征。
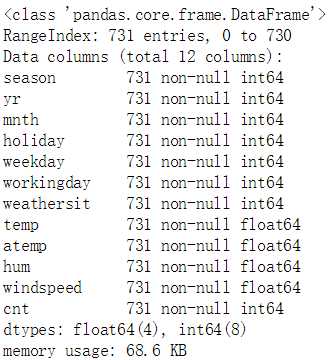
data.describe()
对于分类特征,统计数据的意义不是特别大,主要看数值型数据。 通过观察可以得出,这几个数值型特征的均值与中位数离的比较近,说明数据不会出现一头重一头轻的情况。cnt的方差很大,而其他特征方差很小,原因是本身 这几个特征的度量单位就很小,最大值也都不超过1,而cnt的值普遍很大。因此据此大胆设想,对cnt做数据处理时可以采用标准化,对其他特征采用归一化。
接下来主要观察单个变量的分布
plt.scatter(range(data.shape[0]),data.cnt.values)
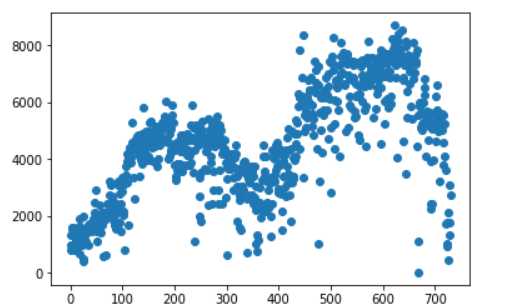
这是目标cnt的散点图分布,明显可以看到在[4000,5000]和[6000,8000]的数据很多,说实话,不是特别符合高斯分布的规律,原因暂时存疑。
sns.distplot(data.cnt,bins=50)
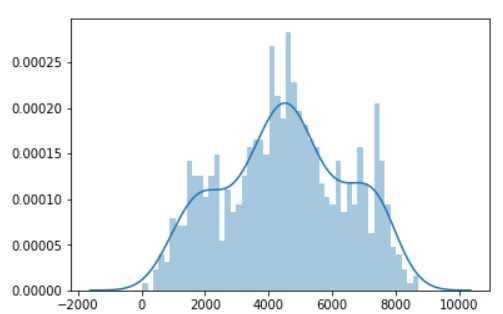
大体形状还是符合高斯分布的,但在2000和8000左右都各有一个突增点。
结合散点图,可以看到0附近和8200的地方有一些离群点,数据处理时可以考虑去掉。
接下来观察数值型特征的分布。
常识判断,温度temp和体感温度atemp的关联性应该是比较强的,因此将两个特征的散点图一起展示:
plt.scatter(range(data.shape[0]),data.temp.values)
plt.scatter(range(data.shape[0]),data.atemp.values)
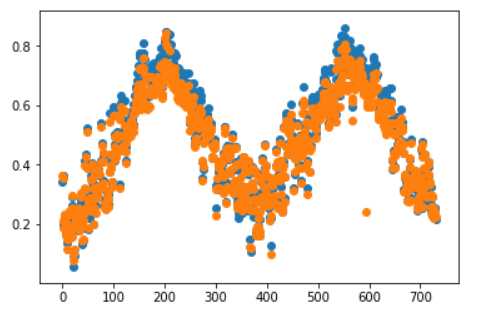
果然,两个特征的分布形状大致相同。其实在计算相关性之前,就可以判定两个特征是冗余的了。
plt.scatter(range(data.shape[0]),data.hum.values)
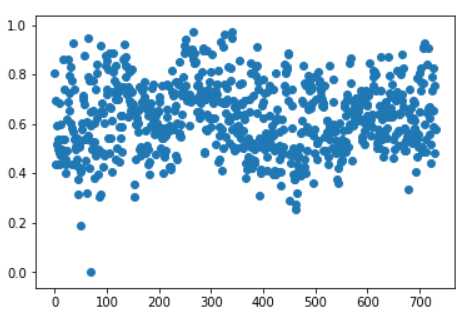
hum的分布是相对集中且均匀的,有一些离群点需要处理,但在散点图上看不出明显的分布,所以看一看它的直方图。
sns.distplot(data.hum,bins=50)
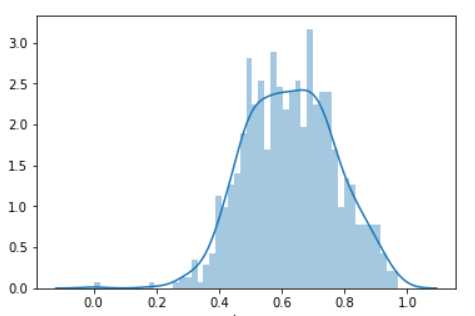
形状有点像高斯分布,但高峰值拉的比较长,和cnt的分布不是特别像
sns.distplot(data.windspeed,bins=50)
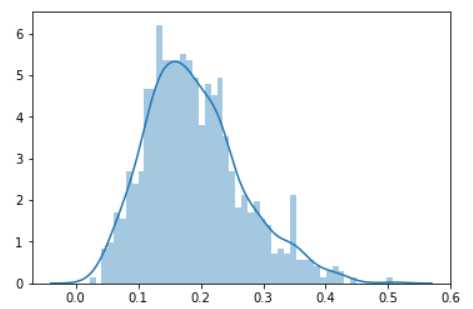
形状略微有些左倾,但大体也是符合高斯分布的
按照步骤,接下来应该要观察分类数据的,但突然发现观察季节和月份的分布是很无脑的,因为一年四季十二个月,难道会因为骑车人数变化而变化?于是果断放弃。
突然发现观察季节和月份的分布是很无脑的,因为一年四季十二个月,难道会因为骑车人数变化而变化?实际上我认为,对于分类特征,尤其是常识可以判断的东西,关注点应该是它们和目标y之间的关联。所以下一步,直接对特征及目标y之间的相关性做计算与可视化。
data_corr = data.corr().abs() plt.subplots(figsize=(12,9)) sns.heatmap(data_corr,annot=True) sns.heatmap(data_corr,mask=data_corr<1,cbar=False)
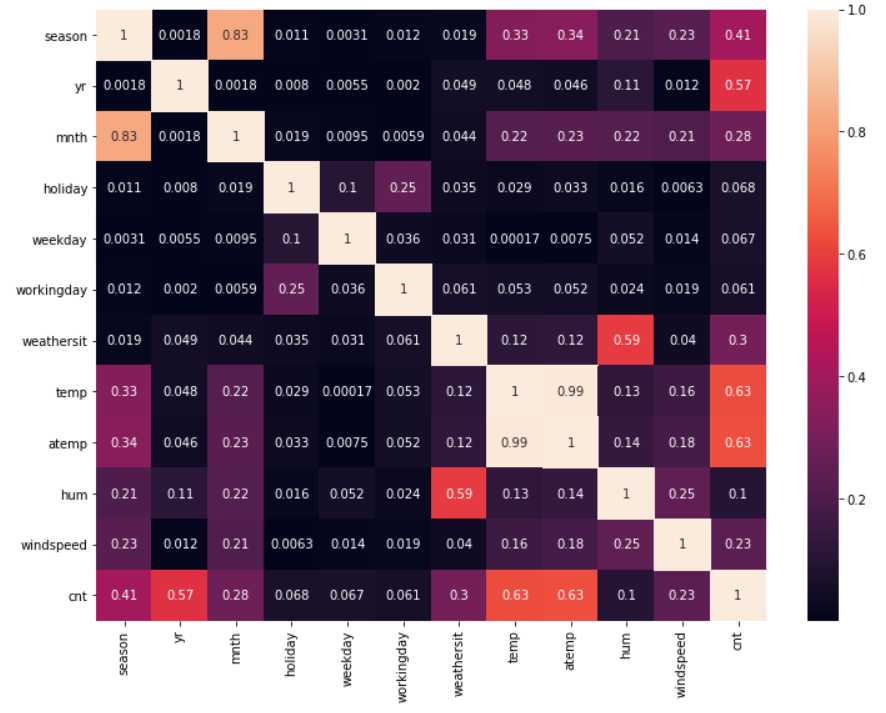
单从cnt的角度看,yr,temp,atemp与cnt的相关性是比较高的;从特征的角度看,temp和atemp的相关性已经达到了0.99,和之前的估计一样,是可以删去一个特征的;season和mnth的相关性也比较强,但只有0.83,还没有到直接可以删的地步,等到以后学到pca,或许可以对它进行处理。
sns.pairplot(data,x_vars=‘atemp‘,y_vars=‘cnt‘)
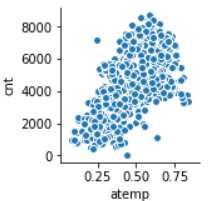
看起来还可以,但毕竟相关性也只有0.63,没法完全贴合线性关系。由于temp和atemp相关性太强,所以只展示一个。
sns.pairplot(data,x_vars=‘yr‘,y_vars=‘cnt‘)
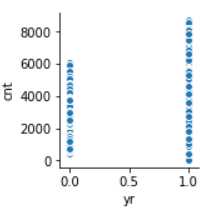
这时候惊奇地发现,2012年地数据不管从分布广度还是数量来说都比2011要大的多,这也解释了为什么cnt的分布图中会有两个小波峰。即便如此,我还是决定先这样做下去,待会儿再考虑是否将数据分开做数据探索。
数据探索部分基本上完成了,接下来整理一下,实现数据清理代码就可以了
#直观上感受,体感温度比室外温度更能够影响用户的骑车意愿,所以去掉temp特征,保留atemp特征 data = data.drop(‘temp‘,axis=1) #去除cnt离群点 data = data[data.cnt<8000] data = data[data.cnt>50] #去除hum离群点 data = data[data.hum>0.3]
数据处理完了,接下来该按题目要求,分离测试数据和训练数据,以及x和y
train = data[data.yr==0].drop(‘yr‘,axis=1) test = data[data.yr==1].drop(‘yr‘,axis=1)
x_train = train.drop(‘cnt‘,axis=1)
x_test = test.drop(‘cnt‘,axis=1)
y_train = train[‘cnt‘]
y_test = test[‘cnt‘]
数据处理
按照上面的分析,要对特征做归一化,对cnt做标准化。这里对分类特征暂时不做特别处理,先把它们和数值型特征一起归一化。
#对特征做归一化 from sklearn.preprocessing import MinMaxScaler mms = MinMaxScaler() x_train = mms.fit_transform(x_train) x_test = mms.transform(x_test) #对cnt做标准化 from sklearn.preprocessing import StandardScaler ss = StandardScaler() y_train = ss.fit_transform(y_train.reshape(-1,1)) y_test = ss.transform(y_test.reshape(-1,1))
最小二乘线性回归
下面用最小二乘线性回归进行拟合
from sklearn.linear_model import LinearRegression lr = LinearRegression() lr.fit(x_train,y_train)
用模型预测训练集和测试集的y,并用r2_score评分
y_train_pred = lr.predict(x_train)
y_test_pred = lr.predict(x_test)
print("训练集r2_score评分:",r2_score(y_train,y_train_pred))
print("测试集r2_score评分:",r2_score(y_test,y_test_pred))
训练集r2_score评分: 0.7559148011319624 测试集r2_score评分: -0.6798040252290449
这个结果是令人惊讶的,经过分析,发现主要原因是2012年的cnt比2011年的cnt要大的多,显然的,有一些这份数据以外的因素导致cnt的增长,因此,无论如何努力,都无法使得测试集上的r2_score追上训练集上的r2_score。但是,r2_score为负的情况实在让人没有办法接受。有什么方法能够改进吗?我找到了一种不算很正规但我觉得应该没错的方法。
通过观察,发现在做数据标准化的时候,训练数据(尤其是y_test)使用训练数据的StandardScaler来处理的,换句话说,实际上y_test标准化处理时,用的均值和方差都是y_train的均值和方差。这显然和事实是不相符的。即便两者方差的误差是可以接受的,但均值的差距可不是一星半点,毕竟y_test有很大一部分聚集在8000附近。这样就明白了,在做标准化的时候,不能用训练集的标准化模型来处理测试集(仅限于测试集和训练集的误差太大的情况)。那不对y做标准化可以吗?我觉得也不太好。因为即使不做标准化,最后线性拟合的结果也是不好的,因为未知因素的影响实在太大了。经过斟酌,我想如果将测试数据与训练数据分开做标准化是不是会好一些呢?
数据处理与线性回归改进版
#对特征做归一化 from sklearn.preprocessing import MinMaxScaler mms = MinMaxScaler() x_train = mms.fit_transform(x_train) x_test = mms.transform(x_test) #对y_test和y_train分开做标准化 from sklearn.preprocessing import StandardScaler ss_train = StandardScaler() ss_test = StandardScaler() y_train = ss_train.fit_transform(y_train.reshape(-1,1)) y_test = ss_train.fit_transform(y_test.reshape(-1,1)) from sklearn.linear_model import LinearRegression lr = LinearRegression() lr.fit(x_train,y_train) y_train_pred = lr.predict(x_train) y_test_pred = lr.predict(x_test)
print("训练集r2_score评分:",r2_score(y_train,y_train_pred))
print("测试集r2_score评分:",r2_score(y_test,y_test_pred))
训练集r2_score评分: 0.7559148011319624 测试集r2_score评分: 0.6882682443144608
果然,结果变为正值了,虽然和训练集上的结果还是有差距,不过总还是迈出了一大步。
数据处理改进版——独热编码
其实训练集的结果也不算太好,于是我决定着手处理分类型特征。查来查去,发现好像独热编码用的比较多。大概的作用就是将分类型数值进行扩维,使得分类特征的数据都只用0和1来表示,这样就避免了分类数值较大的样本对结果的影响。比如season特征,原本有1,2,3,4,四个取值,经过独热编码,变成了[1,0,0,0],[0,1,0,0],[0,0,1,0],[0,0,0,1]四种取值。
#分离出数值型数据,并对数值型数据做归一化 x_train_type = x_train.drop([‘hum‘,‘atemp‘,‘windspeed‘],axis=1) x_train_num = x_train[[‘hum‘,‘atemp‘,‘windspeed‘]] x_test_type = x_test.drop([‘hum‘,‘atemp‘,‘windspeed‘],axis=1) x_test_num = x_test[[‘hum‘,‘atemp‘,‘windspeed‘]] #对数值型数据做标准化 from sklearn.preprocessing import StandardScaler ss_x_train = StandardScaler() ss_x_test = StandardScaler() x_train_num = ss_x_train.fit_transform(x_train_num) x_test_num = ss_x_test.fit_transform(x_test_num) #对类别型特征做独热编码 from sklearn.preprocessing import OneHotEncoder enc_train = OneHotEncoder() enc_test = OneHotEncoder() x_train_type = enc_train.fit_transform(x_train_type).toarray() x_test_type = enc_test.fit_transform(x_test_type).toarray() #还原特征矩阵 x_train = np.concatenate((x_train_type,x_train_num),axis=1) x_test = np.concatenate((x_test_type,x_test_num),axis=1) #对cnt做标准化 from sklearn.preprocessing import StandardScaler ss_y_train = StandardScaler() ss_y_test = StandardScaler() y_train = ss_y_train.fit_transform(y_train.reshape(-1,1)) y_test = ss_y_test.fit_transform(y_test.reshape(-1,1)) from sklearn.linear_model import LinearRegression lr = LinearRegression() lr.fit(x_train,y_train) y_train_pred = lr.predict(x_train) y_test_pred = lr.predict(x_test) print("训练集r2_score评分:",r2_score(y_train,y_train_pred)) print("测试集r2_score评分:",r2_score(y_test,y_test_pred))
训练集r2_score评分: 0.8372356607708061 测试集r2_score评分: 0.6861106294392454
好吧,这次调优有点失败,但终归还是一种尝试,况且今后的分类特征也要用类似方法来处理,就算是提前熟悉一下吧
岭回归
from sklearn.linear_model import RidgeCV
alphas = [0.01,0.1,1,10]
lr = RidgeCV(alphas=alphas,store_cv_values=True)
lr.fit(x_train,y_train)
y_train_pred = lr.predict(x_train)
y_test_pred = lr.predict(x_test)
print("训练集r2_score评分:",r2_score(y_train,y_train_pred))
print("测试集r2_score评分:",r2_score(y_test,y_test_pred))
训练集r2_score评分: 0.8389856732863064
测试集r2_score评分: 0.6960917881076827
性能好了不少,测试集的评分也略有升高,说明正则项还是起到了一定的作用的。接下来看一看它的正则项是否能调优。
print("最佳正则参数为:",lr.alpha_) mse_mean = np.mean(lr.cv_values_,axis=0) plt.plot(np.log10(alphas),mse_mean.reshape(len(alphas),1))
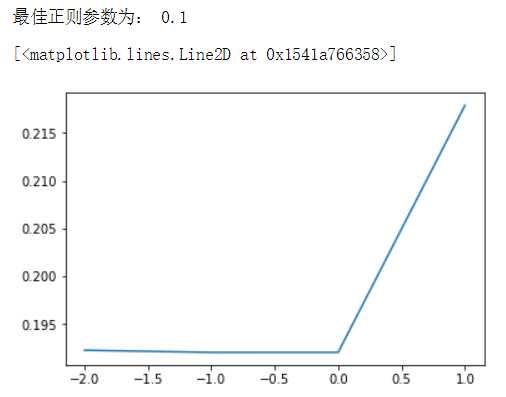
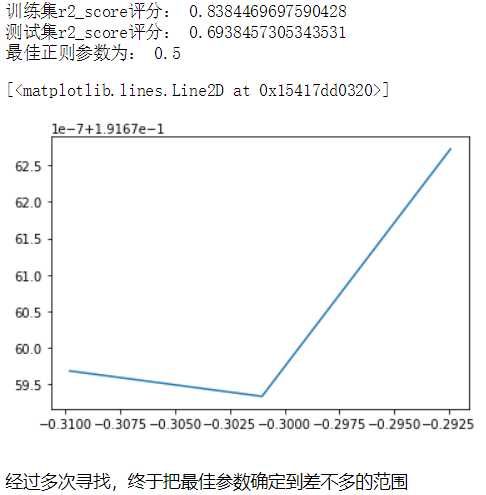
接下来再用Lasso回归尝试一下
Lasso回归
#Lasso回归 from sklearn.linear_model import LassoCV alphas = [0.01,0.1,1,10,100] ls =LassoCV(alphas=alphas) ls.fit(x_train,y_train) y_train_pred = ls.predict(x_train) y_test_pred = ls.predict(x_test) print(r2_score(y_train,y_train_pred)) print(r2_score(y_test,y_test_pred))
0.8097799324474826
0.6968362860350117
在这个例子中,Lasso回归要略好于岭回归,但差距不大。Lasso回归参数调优与岭回归差距不大,此处略去过程。
结语
至此,第一次线性回归的尝试基本完成,有瑕疵或是有疑惑的地方今后修改,欢迎大佬们批评指正!