1、技术背景
1.1、技术举例:Memcache
1.2、技术瓶颈
memcached服务器端本身不提供分布式cache的一致性,由客户端实现提供。以余数分布式算法为例。
余数分布式算法是根据添加进入缓存时key的hash值通过特定的算法得出余数,然后根据余数映射到关联的缓存服务器,将该key-value数据保存到该服务器
1.2.1、假设有3台缓存服务器以及它们对应的余数值
Node A:0,3,6,9
Node B:1,4,7
Node C:2,5,8
1.2.2、此时添加一台服务器Node D
服务器对应的余数值发生变化,如下
Node A:0,1,2
Node B:3,4
Node C:5,6
Node C:7,8,9
根据上面的变化,发现只有余数值为0,4,5所对应的缓存服务器没有发生改变,也就是说其它余数值对应的缓存服务器发生了改变,即缓存失效,如果大量缓存失效会严重影响系统的性能,也就是缓存动荡。针对这样大片缓存失效的技术瓶颈,于是提出了一致性hash算法。缩小失效缓存范围。
2、一致性Hash算法
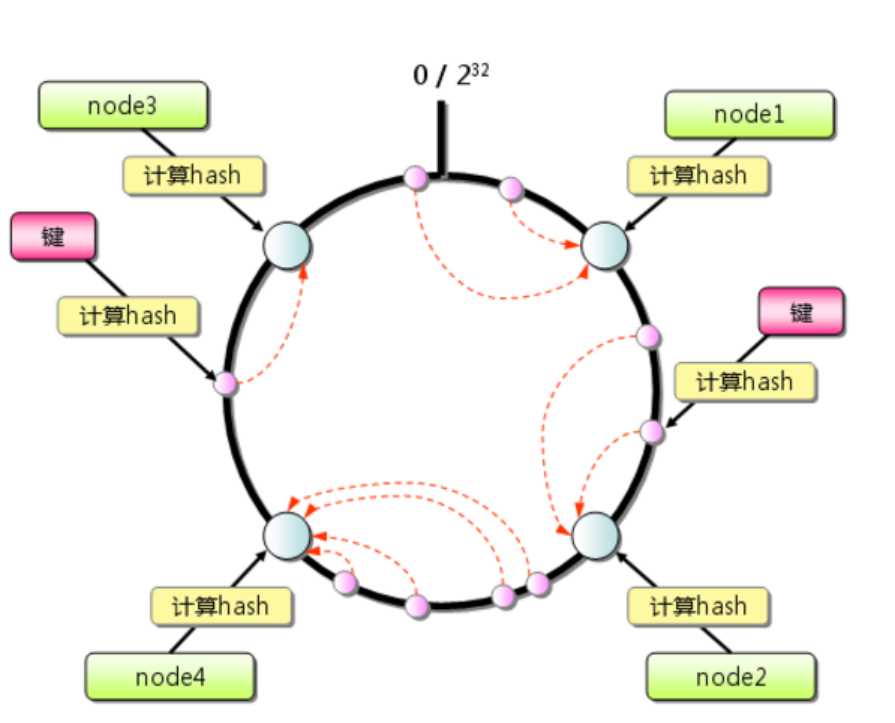
2.1、将hash值范围看成一个0~232的圆。
2.2、将服务器节点的hash值映射到该圆上。
2.3、对数据进行缓存时,计算key的hash值,然后找到该值在圆上的位置,顺时针进行查找,将数据保存到第一个查找到的服务器。
2.4、添加一个缓存服务器,如图
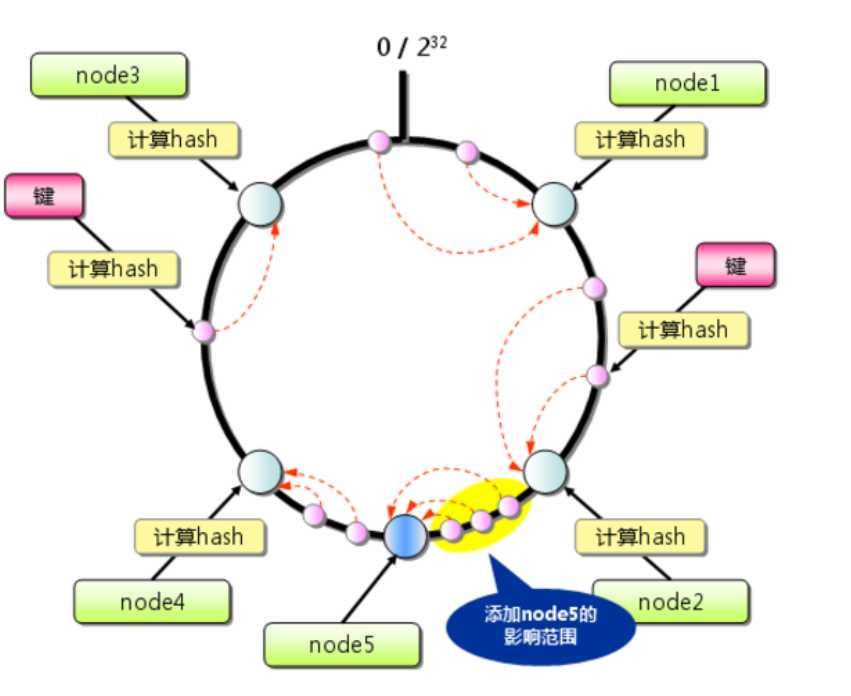
根据hash一致算法的映射查找规则,受影响的缓存只有新服务器的hash值----新服务器逆时针的第一个服务器hash值得范围,也就这块区域的缓存失效,大大降低了失效范围。
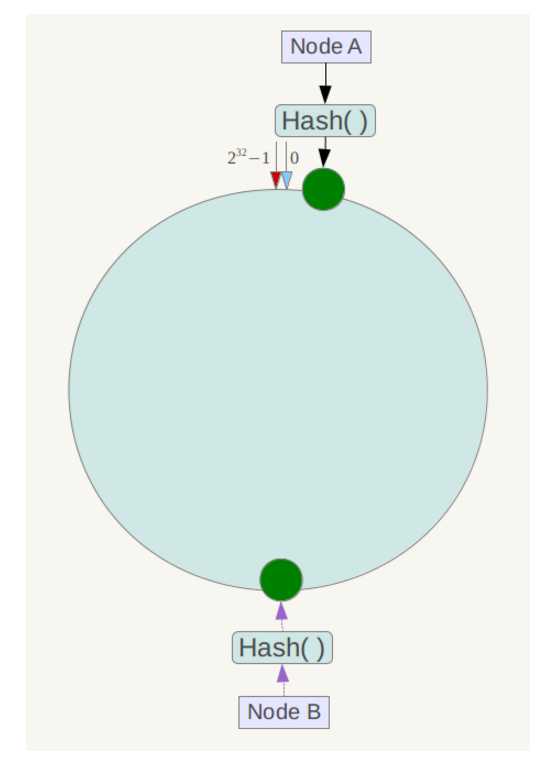
2.5、当服务器过少时,会带来数据倾斜问题
加入只有两台服务器A和B,那么hash范围如下
Node A:0-231
Node B:0-232
很容易造成数据堆积在节点A,于是一致性哈希算法引入了虚拟节点机制,即对每一个服务节点计算多个哈希,每个计算结果位置都放置一个此服务节点,称为虚拟节点。具体做法可以在服务器ip或主机名的后面增加编号来实现。过程如图
无虚拟节点
引入虚拟节点
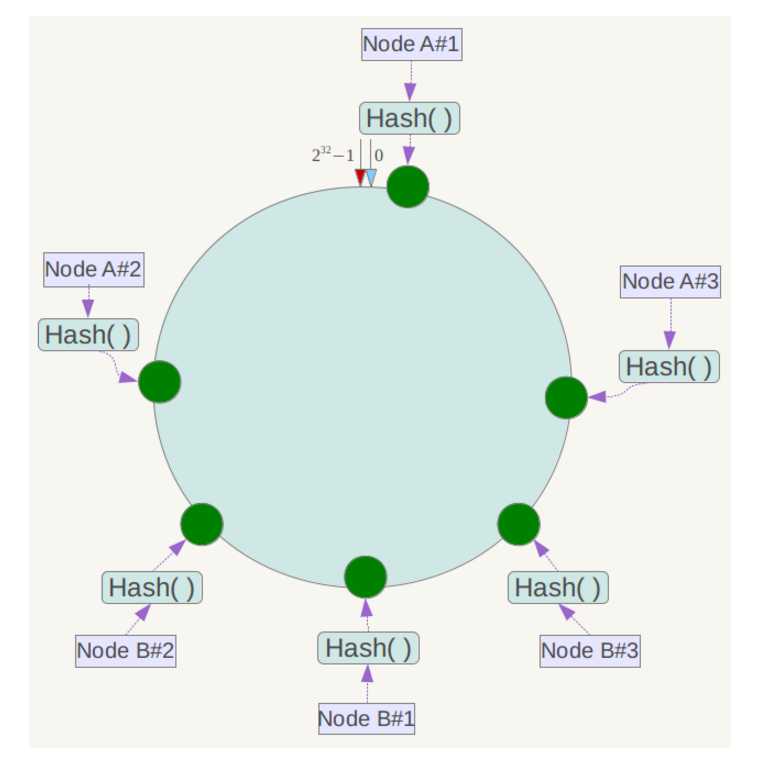
注:图是从其它网站下载