大白话聊缓存之一致性hash
Posted 中企老徐的架构笔记
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大白话聊缓存之一致性hash相关的知识,希望对你有一定的参考价值。
hash算法的缺点
先看图
cache做了sharding
用户服务做hash的方法也很简单 对key做hash后对sharding总数取模即可
伪代码如下
string key = “asdfasdf”long index = hash(key) % 3 //sharding = 3Cache cache = cachePool.getCache(index)cache.set(key, 'test value')
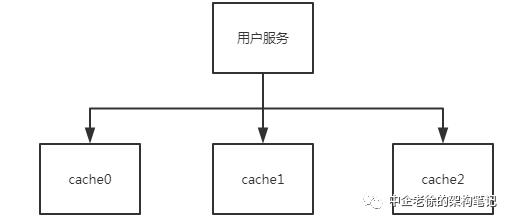
咋一看这个设计很好啊,但如果遇到cache节点网络抖动 宕机等问题就会无限放大
缓存失效引起雪崩

先了解下雪崩
还是上面的图,我稍作修改
现在我们看到cache0节点挂掉了
那么用户服务会感知到节点变成了 2 个
那么问题来了
同样是上面的伪代码,这次我们用户读取上次写入的数据
string key = “asdfasdf”long index = hash(key) % 2 //注意这儿 sharding = 2 了//index 的结果肯定与模 3 不同,获取到的cache节点同样也不同啦// 大家想象一个所有的读请求是不是都落到了错位节点上呢?结果就是大量的查询为空// 大量请求转发到数据库拿数据,雪崩来了Cache cache = cachePool.getCache(index)// 这个获取不到值,因为路由节点错了string value = cache.get(key)
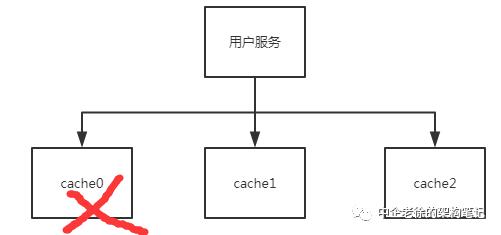
因为一个节点的问题,导致所有节点的数据都不能正确读取,这样的设计确实不妥,怎么治疗呢? 科学家们早就研究出更好的方法啦
一致性hash,专治各种缓存雪崩
什么是一致性hash
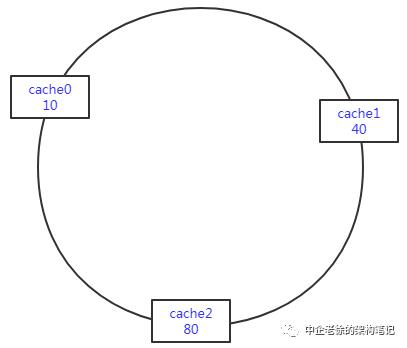
看图
这个环上平均分配了0~232 点
很多是吧,这里我们把这个数写小点(0-99)供100个点,但道理是一样的
一致性hash第一步:对节点做hash
对三个节点计算hash值,并保存到hash环上
hash环可以简单认为是个环形数组
伪代码如下
int index0 = hash("cache0:8001") % 100int index1 = hash("cache1:8001") % 100int index2 = hash("cache2:8002") % 100
这里我们分别假设index的值如下
index0 = 10index1 = 40index2 = 80
那么这个三个节点的值就会存储在这三个位置
下面重点来了
数据如何读写?
先看伪代码吧
string key = ‘qwerqr’int index = hash(key) % 100 //100是hash环的长度//关键来了 我们计算出来了index值 比如正好是10 那直接就命中了 cache0//就可以读写了,但是如果index是11怎么办呢//这儿就是一致性hash的核心算法了:如果没有命中cache实例 它会沿着当前index位置顺时针查询//一直到查到为止 请看代码for(int i = 11; i < 100 ; i ++){if(hashArray[i] != null)return cacheNode;}for(int i = 0; i < 11; i++){if(hashArray[i] != null)return cacheNode;}
用图表示下吧
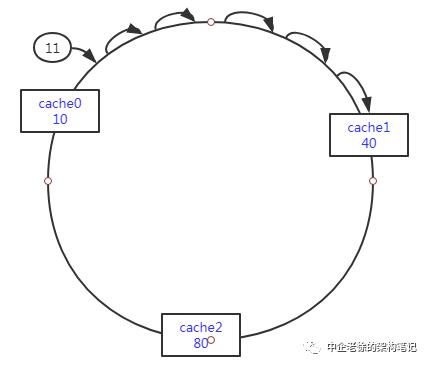
当然一个一个的查询是效率最低方法。
在java语言中有TreeMap既可以实现快速查询,又能节约大量内存开销
如下图,一下就可以命中下一个cache节点
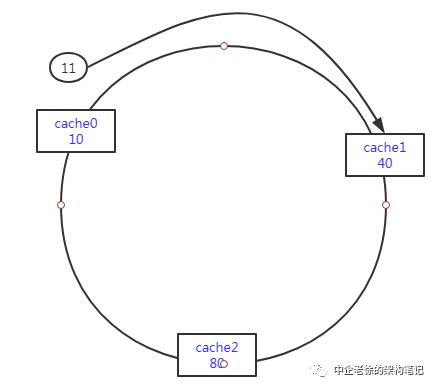
用一致性hash解决缓存雪崩问题
还是上面的图
假如cache2节点挂掉了
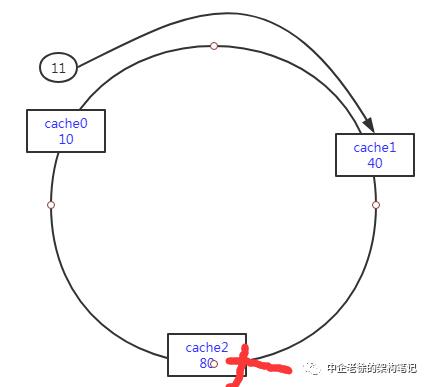
是不是不会影响index=11缓存读写的,大家思考一下
如果index=41读写呢,按照一致性hash的算法就会命中cache0节点
再思考下如果index=81呢,很显然也会命中cahce0节点
这样结论就很明显了
一致性hash算法,不会引起雪崩,只会把读写的压力转移到相邻的下一个节点
很显然这会导致数据的不平衡
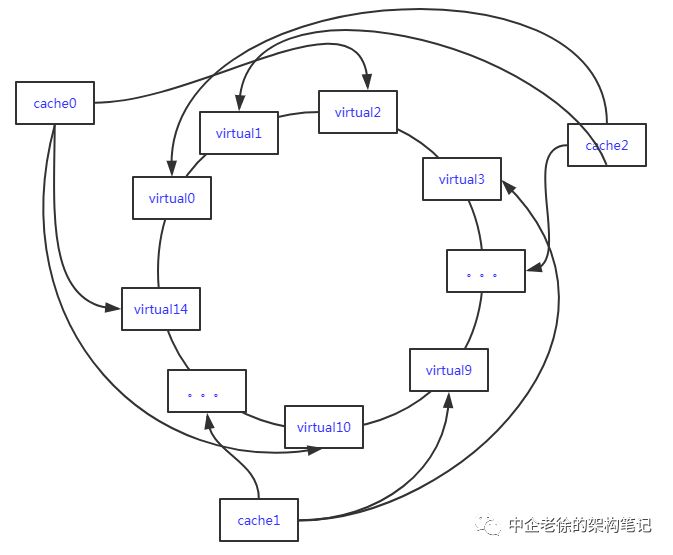
虚拟节点解决数据不平衡
对于数据不平衡的解决方式也很简单,增加一层虚节点
假设有三个真是节点 cache0 cache1 cache2 我们想虚拟出15个节点
伪代码如下
List cacheNode = {"cache0","cache1","cache2"}List virtualNode = new AaaryList(15);for(int i = 0; i < cacheNode.size(); i ++){for(int j = 0; j < 5; j ++){virtualNode.add(cacheNode[i])}}
这样我们得到了15个虚拟节点, 然后散落到hash环上
更多的虚拟节点会让节点的分布更加均匀,数据的读写会更加平衡
大家想象一样是不是这样呢
如下图 虚拟节点与真实节点的关系

End
更多精彩内容
猛戳左边二维码
了解更多哦
以上是关于大白话聊缓存之一致性hash的主要内容,如果未能解决你的问题,请参考以下文章