机器学习中的算法主要分为两类,一类是监督学习,监督学习顾名思义就是在学习的过程中有人监督,即对于每一个训练样本,有对应的标记指明它的类型。如识别算法的训练集中猫的图片,在训练之前会人工打上标签,告诉电脑这些像素组合在一起,里面包含了一只猫。而自然界中更多的数据样本,事实上是没有这些标记的,而我们针对这些没有标记的数据样本,对它们进行学习的算法就叫做无监督学习。聚类算法就是一种典型的无监督学习的算法。俗话说,物以类聚,聚类算法通常就是把分散在空间中的样本按照一定的规则聚集在一起。K-Means聚类算法是聚类算法中最简单最易于实现的一种。
在说明K-Means聚类算法的思想之前,我们先要搞懂距离的测量。
针对2维空间的点两个点X=(1,2) Y=(3,4),通常我们将两个点之间的距离所采用的方法都是欧式距离
sqrt((1-3)2 +(2-4)2)
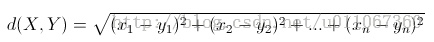
欧氏距离表示的就是两点在欧氏空间中线段的长度
但除了欧式距离之外我们还有很多度量距离的方法,比如曼哈顿距离
因为曼哈顿城区很方正,从一个地方走到另一个地方的距离就等于,起点的X坐标与终点坐标的X坐标差的绝对值加上起点Y坐标与终点Y坐标的差的绝对值,推广到n维欧氏空间,
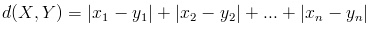
针对两个向量的比较,我们还能够使用向量的余弦夹角来定义相似性,也可以用来进行向量间距离的度量
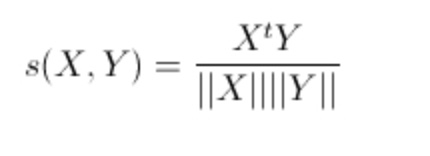
在K-means聚类中,通常还是采用欧氏距离来表示样本间的距离,在这里只是说明对于样本,我们是可以采用不同的度量方法去判断样本间的距离的。距离的度量就不做推广了。
K-Means聚类算法的思想其实很简单,K代表了聚类结果中包含了几个簇,也就是聚类结果有几个集合,这个K值是需要进行聚类的人手工添加的。
1.人工确定K的值后,我们先将在样本空间中随机选取K个值作为聚类的中心
2.接着遍历样本集,计算每一个样本到各个中心的距离,将样本点归类到离它最近的中心所属的簇
3.计算出每一个簇的中心
4.重复2,3直到收敛
用数学来表示这个思想就是:
1.初始化 t = 0(t代表迭代次数), 随机选取k个中心点c1,…ck
2.将样本分配到每个中心
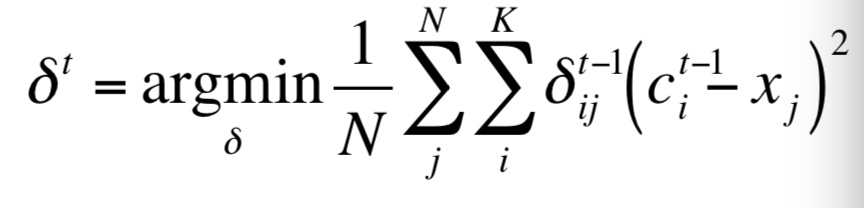
3.更新簇中心

4 t=t+1 ,重复2,3,知道Ct不在变化
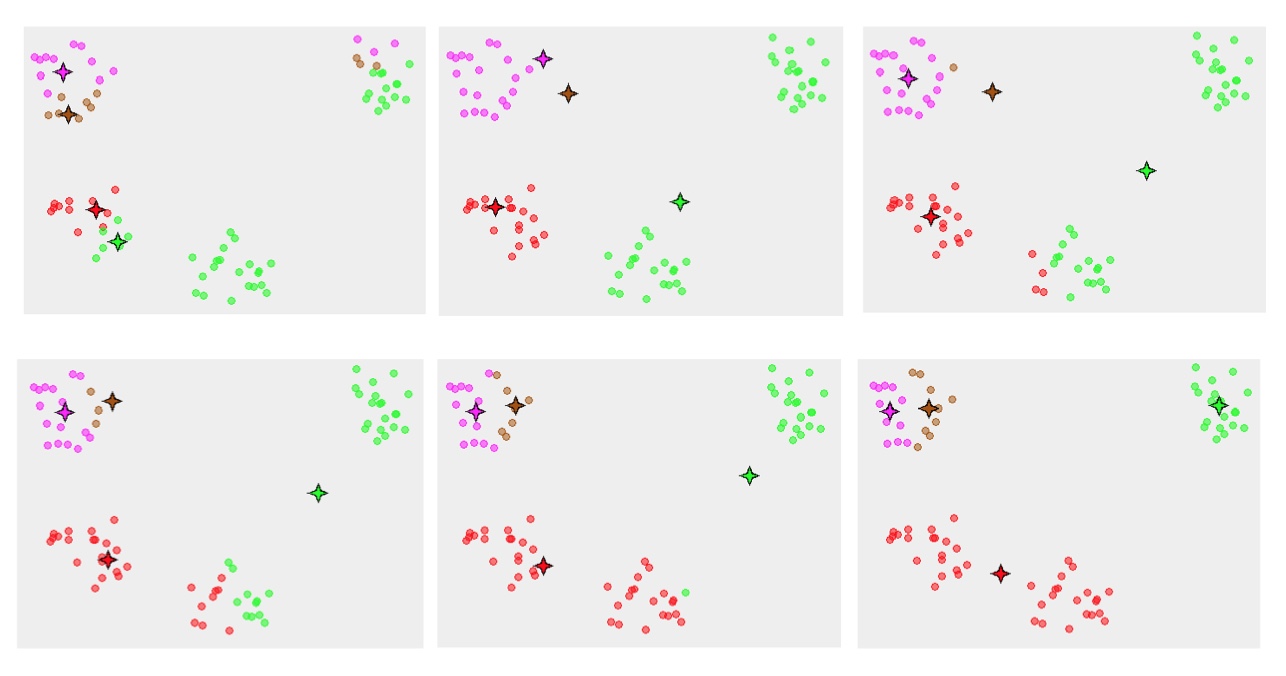
k-Means聚类算法运行过程
K-Means聚类的优缺点
优点:
简单,算法效率高
易于实现
缺点:
需要人工设置K值
对离群点敏感
容易掉入局部最小值
一点小思考,如果样本空间大,而样本集并没有均匀的分布在样本空间中,那第一步的初始化就不能以在随机在样本空间中生成的方法产生,而应该在样本集中随机选点来产生中心。甚至在样本中可能有一些偏离样本集中心太大的样本,我们把这样的样本叫做离群点,针对离群点,会对k-Means算法造成很大的影响,通常将这样的样本取出单独分析,因为这些样本作为高频信息,本身就具有很好的研究价值。还有一个问题就是,K-Means聚类的收敛性,以及当k相同时,它的收敛结果都是一样的吗?
可以证明k-Means算法是可以收敛的,但是随机的初始点不同,k-Means即使在k相同的情况下,也会得到不同的结果。因为我们有可能会陷入局部最优,而不是全局最优解中。
K-Means收敛性:
首先我们定义畸变函数:

畸变函数表示每个样本点到其质心的距离平方和。K-Means算法的目的就是将畸变函数调整到最小。假设畸变函数没有到达最小值,那么首先可以固定每个类的质心,调整每个样例的所属的类别c来让J函数减少,同样,固定C,调整每个类的质心μ也可以使J减小。这两个过程就是内循环中使J单调递减的过程。当J递减到最小时,μ和c也同时收敛。(在理论上,可以有多组不同的μ和c值能够使得J取得最小值,但这种现象实际上是很少见的)。
由于畸变函数J是非凸函数,意味着我们不能保证取得的最小值是全局最小值,也就是说k-Means对质心初始位置的选取比较感冒,但一般情况下k-means达到的局部最优已经满足需求。但如果你怕陷入局部最优,那么可以选取不同的初始值多跑几遍k-Means,然后取其中最小的J对应的μ和c输出。
针对K-Means掉入局部最小值的优化
二分K-Means算法:
首先将所有点看成一个簇
当簇的数目小于k时
对于每一个簇
计算总误差
在给定的簇上面进行K-Means聚类(k=2)
计算将该簇一分为二后的总误差
选择使得误差最小的那个簇进行划分操作
因为K-Means算法中初始的随机种子点会对最后的结果产生深远的影响,除了上面提到的多次运行产生结果外,也有改进的K-Means++算法:
假设已经选取了n个初始聚类中心(0<n<k),则在选取第n+1个聚类中心时,距离当前n个聚类中心越远的点会有更高的概率被选中为第n+1个聚类中心。既聚类中心的距离离得越远越好。
1.先随机挑选随机点当做种子点
2.针对每个点,我们都计算其和最近的种子点的距离D(x)并计算所有D(x)的距离sum(D(x))
3.再取一个随机值,用权重的方式来取计算下一个种子点,先取一个能落在sum(D(x))中的随机值Random,然后用Random-=D(x),直到其<=0,此时的点就是下一个种子点
4.重复2,3直到选出k个种子点
5.进行k-means算法
K-Means在计算机视觉领域的应用
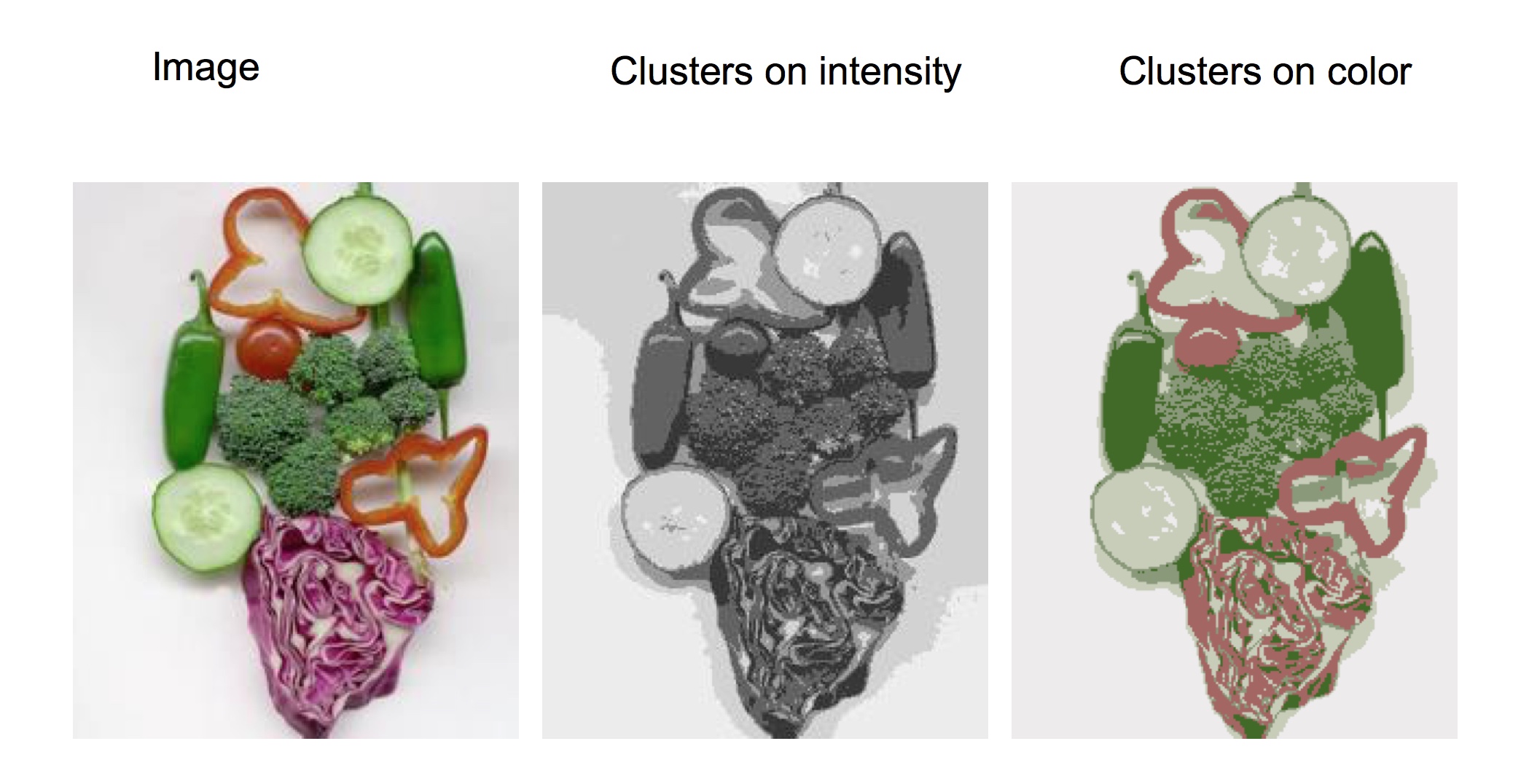
1.对图像像素进行聚类
对像素进行聚类通常有两种分类方法,一是根据图片的灰度值(也就是响应值)进行聚类,二是根据图片的色彩空间进行聚类
这个地方就可以用到文章开头提到的距离度量问题,在针对灰度值进行聚类是,因为每个灰度值都是一个标量,我们可以采用欧氏距离来度量距离,但针对色彩空间进行聚类,例如RBG,每一个RGB值我们都可以看做一个三维向量,那针对向量进行距离的度量,我们就应该采用向量间的夹角的余弦来定义。
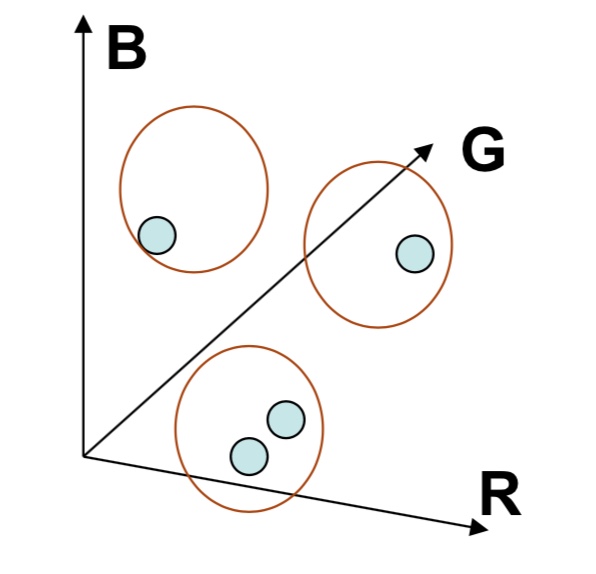
下图是图片基于灰度值以及色彩空间进行k-means聚类的结果
2.针对图像算法中的一些向量特征,例如SIFT中的128维兴趣点特征,构建一个匹配框架,将学习到兴趣点进行聚类,建立一个匹配字典,再匹配新的特征时,对各个簇进行匹配
后记:阅读了大量资料后,我发现K-Means算法与EM算法应该有很多内在的联系,笔者没有学习过EM算法,暂时不对这部分进行记录,学习EM算法后,再对这部分进行更新