简单的方法爬取b站dnf视频封面步骤解释
Posted 樱花落舞
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了简单的方法爬取b站dnf视频封面步骤解释相关的知识,希望对你有一定的参考价值。
这随笔代码链接:http://www.cnblogs.com/yinghualuowu/p/8186375.html
首先我们要知道,一个分区封面显示到底在哪里可以找到。
很明显,查看审查元素并不能找到封面。这个时候应该想到封面是动态加载的。
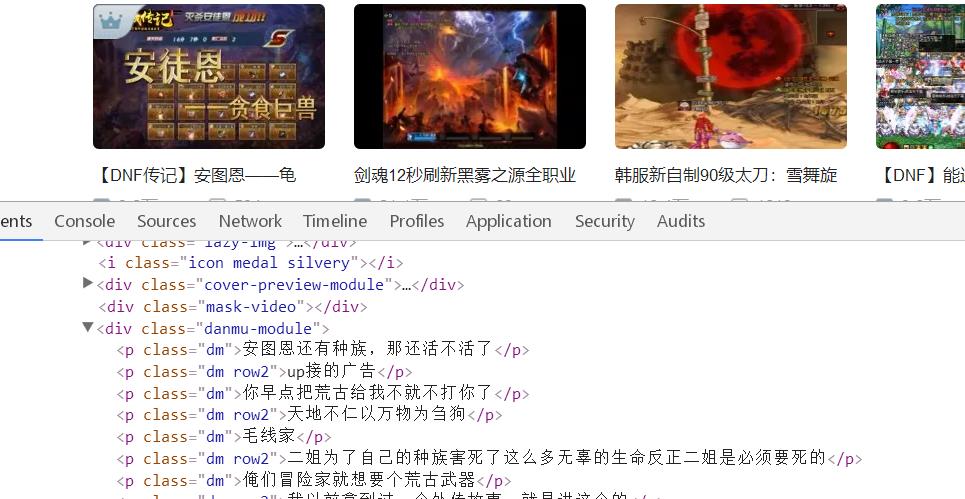
再次去Network寻找,我们发现这样一个JS。这是右侧热门视频封面的内容,点开之后存在pic:正是封面的链接。
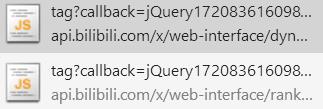

进行json解析之后,判定pic在data>archives结构下。这个时候链接是有了,那么将如何把Json拿出来呢?

让我们观察一下原来的信息,除去JQuery........()这层,里面就是json字符串了,既然如此简单,那么我们就...

查找开头第一个(,然后截取至最后一个),里面不就是了吗?
def instr(keystr): st=keystr.find(\'(\')+1 strhtml=keystr[st:len(keystr)-1] return strhtml
def picsave(strJson,number): global cnt strdic=strJson[\'data\'][\'archives\'] num=len(strdic) for i in range(0,num,1): cnt=cnt+1 strdic=strJson[\'data\'][\'archives\'][i] print(strdic[\'pic\']) urllib.request.urlretrieve(strdic[\'pic\'],\'E:\\图片\\dnf\\%s.jpg\'%(cnt))
然后进行翻页判断,我们尝试点开第一页和后面几页,看看不同。pn数字貌似变化很有规律啊。

![]()
于是...
def urlget(num): for i in range(1,num,1): url=\'https://api.bilibili.com/x/tag/ranking/archives?callback=jQuery172014070206081723846_1514982701564&tag_id=5033&rid=65&type=0&pn=\'+str(i)+\'&ps=20&jsonp=jsonp&_=1514982702144\' response=urllib.request.urlopen(url) html=response.read().decode(\'utf-8\') html=instr(html) strJson=eval(html) picsave(strJson,i)
然后,就没有了。其实要高清大图的话,你需要点进去一个视频,然后审查元素,后面我会写一个输入av号来获取封面的代码

以上是关于简单的方法爬取b站dnf视频封面步骤解释的主要内容,如果未能解决你的问题,请参考以下文章