规范化用于粒度化和组织在数据库中使用的数据。
在第4章中将详细介绍规范化和应用范式的过程。在这个阶段只需要知道规范化是用于将数据划分到单独表中的方法或公式——根据一组规则。
不信任将视图用于除了安全性目标之外的任何事情。
表的概念
在数据模型理论中,表是连续存入数据的存储桶。关系数据库模型和规范化的思想是,特定表中的数据直接与相同表中的所有其他项关联。
相同表中的所有记录具有相同的字段结构。
表、字段、记录、元组
字段、列、属性都是用于描述表中字段的术语。
数据类型
数据类型可以分为3中类型:
- 简单数据类型——这些是在单值上应用模式或者值限制的数据类型。
- 复杂数据类型——包括连接对象和关系数据库的任何数据类型,包括二进制对象和集合数组等项。
- 专门的数据类型——存在较为高级的关系数据库中,这些数据库可以存储固有的结构化数据,比如XML文档、空间坐标数据、多媒体数据。
关于规范化
规范化通常设法将信息划分为较小的、更容易管理的部分,但最好不要太小。大多数明显的冗余通常可以删除。从商业上来说,主要的目标是节省空间和组织数据以实现可用性和可管理性。非常繁忙的应用程序和终端用户的要求可能会迫使在许多方面违反规范化的规则,以满足性能需要。第三范式以上的范式通常被忽略,有时甚至第三范式也被忽略。
规范化是自增的过程。换言之,每个范式层添加到已经应用的范式。例如,第二范式只可以应用于第一范式中的表,而第三范式不可以应用于第四范式中的表,因为根据定义,第四范式中的表是已经在第三范式中表的积累。
规范化的优点
- 减少存储数据的物理需求
- 数据组织得更好
- 规范化允许立刻修改表中的少量数据(也就是一条记录)。
潜在的规范化危险
在规范化的一些细节方面的积极影响可能具有消极的副作用,并且有时是产生反效果,这取决于数据库的应用程序关注对象。性能总是又这样的问题:由过度的应用程序规范化造成的过分粒度化。过分要求并发的OLTP数据库可能受到过分粒度化的负面影响。要注意以下几点:
- 涉及的物理空间不断增大
- 过度的最小化冗余暗示过细的粒度和过多的表。过多的表可能导致特别大的SQL连接查询。SQL连接查询的表越多,该查询的执行就越慢。性能受到彻底的影响,从而使应用程序彻底无用。
- 使用过度数量的冗余最小化较好地组织数据实际上可能导致更多的复杂性。规范化层次越深入,模型就变得越数学化。
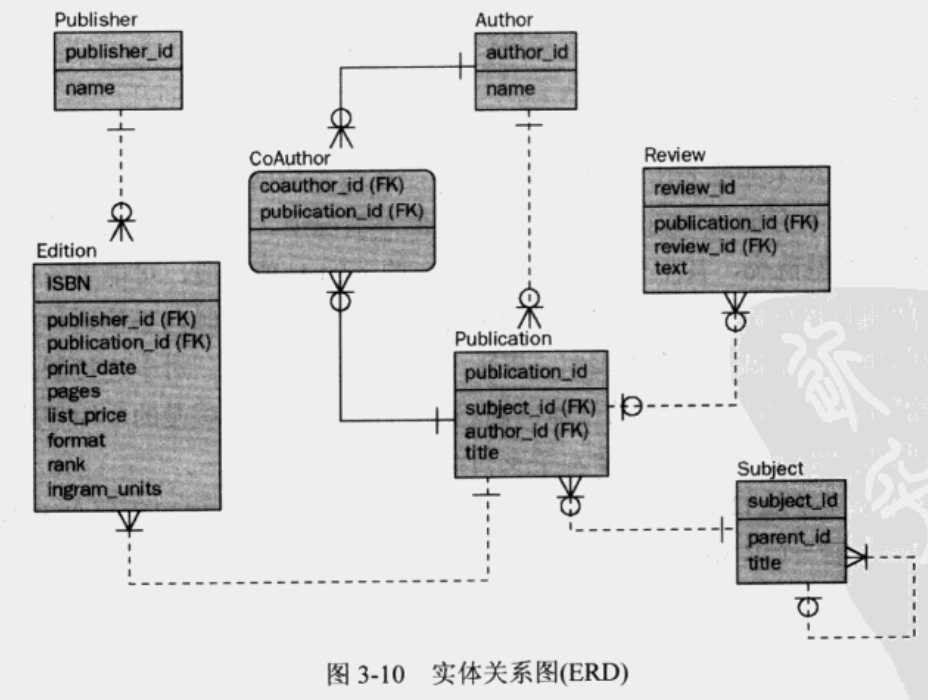
用ERD表示关系
表和表之间可以有各种类型的关系,可以通过实体关系图(Entity Relationship Diagram, ERD)中的显示最好描述不同类型的表之间的关系。
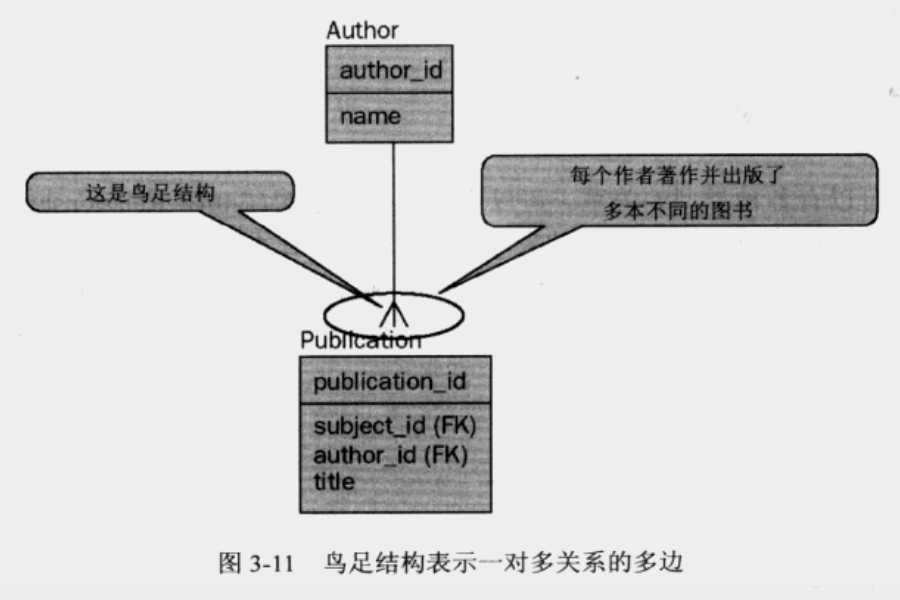
鸟足结构
鸟足结构(crow‘s foot)用于描述一对多关系或多对多关系的"多"边。应该可以了解到,许多脚趾是指多于一个,因此是多个。
一对一
一对一关系用的比较少,除非在因为存储空间的价格非常便宜的例外情况中。一对一关系是第四范式转换的典型情况。

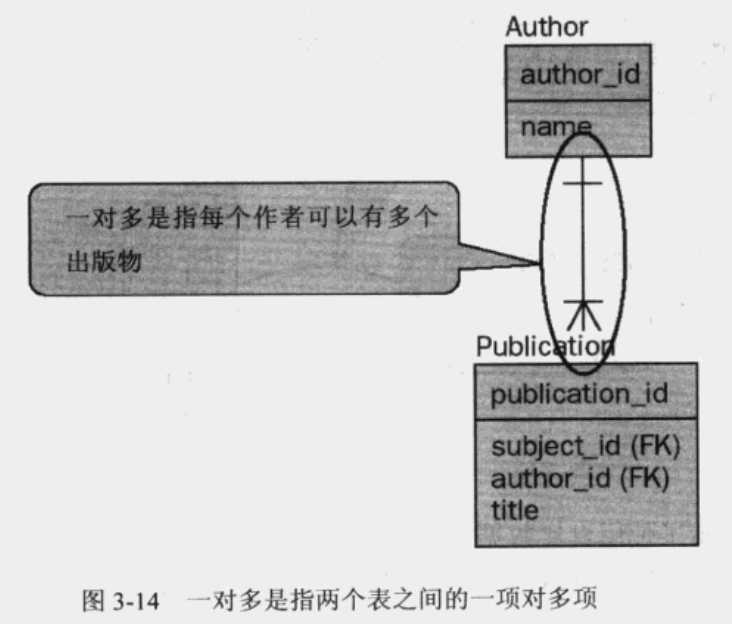
一对多
一对多关系在关系数据库模型的表之间特别常见。
多对多
多对多关系意味着,对于一个表中的每一条记录,在另一个表中有许多可能的对应记录,反之亦然。多对多关系的经典示例是多个学生注册大学中的多门课程。含义是每个学生注册多门课程,而没门课程有多个学生注册。
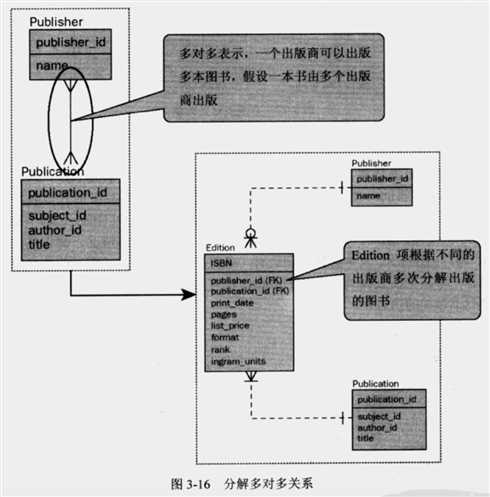
多对多的关系可以用中间关联表来解决,用两个一对多来解决。
零、一或多
表之间的关系可以是零、一或多。零是指记录不需要存在于目标表中,具有零的一是指它可以存在,没有零的一是指它必须存在,而多就是指多个。
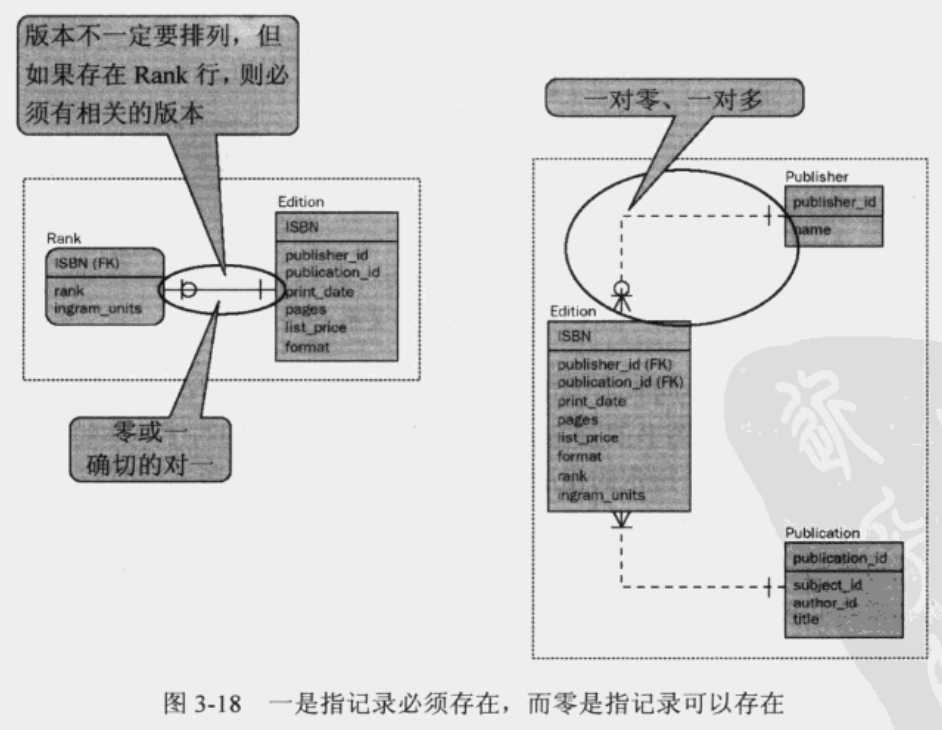
即使出版商当前没有出版任何图书,也可以称之为出版商。
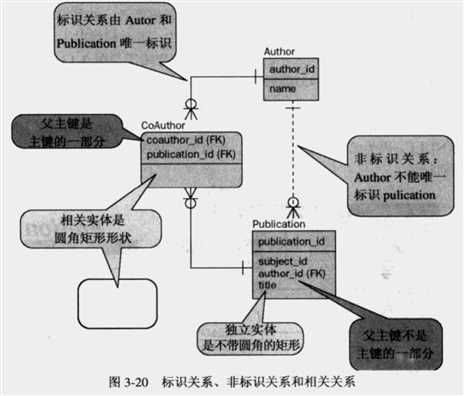
标识和非标识的关系
图3-20显示了标识关系、非标识关系、以及依赖表。
- 标识关系——子表由父表部分标识,并且部分取决于父表。父表的主键包括在子表的主键中。
- 非标识关系——子表不取决于父表,从而子表作为外键包括父表的主键,而不是作为子表主键的一部分。
- 依赖实体或表——CoAUTHOR表依赖于AUTHOR和PUBLICATION表。对于具有于父表的标识关系的表,存在依赖表。
- 非依赖实体或表——这是依赖表的对立面。
键用于标识并最终用于在日后从数据库中检索记录。