《数据库设计入门经典》,现在学习的是这本书,虽然以前就看过类似的书,可能由于之前经验不足,书中说的某些东西只消化了一部分,现在重温一边好懂多了。所以说读第一遍读不懂不要紧,过个一年半载的再来读,还是会读不懂的,哈哈。

就是这本了。
第一章 数据库建模的过去与现在
数据库模型和数据库之间有什么区别?
数据库将服务于某类型的应用程序。不同类型的数据库模型支持不同类型的应用程序。
联机事务处理(Online Transaction Processing,OLTP)数据库通常是专门的、高并发性的(可共享的)体系结构,它需要快速访问非常少量的数据。
文件系统
层次结构数据库模型
网络数据库模型
关系数据库模型
对象数据库模型:相比于关系数据库模型,对象数据库模型可以解决一些更加难以理解的复杂问题,比如消除了类型和多对多关系替换表的需求。对象数据库模型的另一个优点是管理和迎合非常复杂的应用程序和数据库模型的内在能力。这是因为对象方法学的基本原则:非常复杂的元素可以分解为最基本的部分,允许对这些基本部分进行显式访问和执行这些基本部分。在书中介绍关系型数据库模型时讨论对象数据库模型非常重要,因为许多现代的应用程序都是使用以对象方法学为基础的SDK(例如java)编写的。对象编程应用程序和关系数据之间一个最重要的关键点是:两种结构化类型(对象和关系)之间的映射过程的性能。
在检索多个数据项的时候,对象数据库模型的执行性能比较差。另一个方面,关系型数据最适合检索数据组,但也可以有效地访问唯一的数据项。
数据库的类型:
事务的:对数据库进行少量改动(小型事务)
决策支持系统(Decision support system,DSS):数据仓库数据库一般不灵活,因为它们可能极其庞大
混合的:对中小型公司是更为合适的选择,因为仅仅有一个而不是两个数据库,更少的机器,更少的软件许可,更少的人
对于数据库模型,必须在构建之前设计它,然后开始用数据填充它,并且将它关联到应用程序。
数据库的设计非常重要,因为根据数据库模型设计编写的所有应用程序都是完全与底层数据库的结构相关的。如果必须在后面的阶段中修改数据库模型,则可能必须修改基于该数据库模型构造的所有内容,也可能需要完全重写。
具有良好结构的数据库目标——具有良好结构的数据库模型是简单的、易于阅读的、并且易于理解的数据库模型。
数据完整性——完整性是数据库模型中的一组规则,用于确保数据库中的数据不会丢失。
支持有计划的查询以及ad-hoc或无计划的查询——ad-hoc查询越少,当然越好。在某些环境中(例如在非常高并发性的OLTP数据库中)可能必须完全禁止ad-hoc查询,或者转移到更适当的数据仓库平台。
还有一些小的要点:
ad-hoc查询可能造成严重的性能问题。需要毫秒响应时间的面向客户的应用程序不会与ad-hoc查询很好的相处。
支持业务目标——高度规范化的表结构不一定直接代表业务结构,非规范化的、数据仓库的、事实-纬度的结构可能更适合于操作性业务。
为任何必须的修改操作提供适当的性能
数据库模型中的每个表应该更适合代表某个题目或主题——不要过多地设计数据库模型,不要创建太多的表。OLTP数据库可能因为更多的细节和更多的表而变得庞大;将数据分到太多的表中,数据仓库可能崩溃。
未来增长必须总是要认真考虑的事项——一些数据库可能以无法估量的速度增长。
数据库设计的方法
如何着手设计数据库模型?
需求分析——收集如下相关信息:数据的性质、必需的特性和任何特别的需求,例如期望的输出响应。
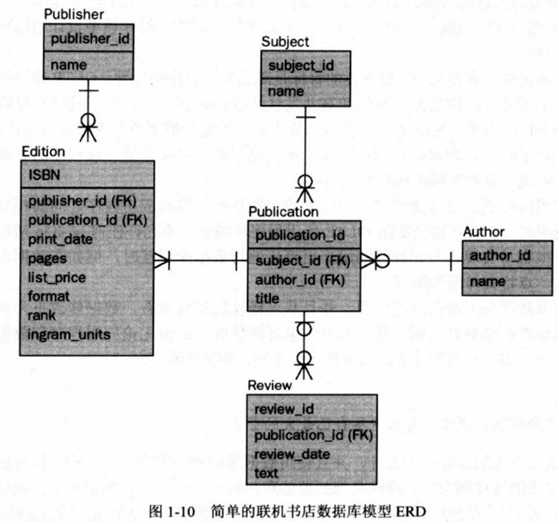
概念设计——开始使用图形工具绘制漂亮的图形:实体关系图(ERD)。这个步骤包括创建表、表中字段以及表之间的关系。这个步骤也包括了规范化。
逻辑设计——创建数据库语言命令以生成表定义。
物理设计——调整数据库语言命令以针对表的底层物理属性修改数据库模型。
调整阶段——这个步骤包括了多项,例如适当地建立索引、进一步的规范化、甚至是反规范化、安全特性、以及前面步骤中没有包括的其他内容。
这些单独的步骤是可互换的、可重复的、迭代的、并且是真正能够做任何事情的。
应该坚持的唯一通用事实是:在构建元数据表创建代码之前应该很好地绘制ERD并构建表,并且在实际实现之前应进行可视的设计。