TensorFlow实战之Softmax Regression识别手写数字
Posted 蓝色之旅
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了TensorFlow实战之Softmax Regression识别手写数字相关的知识,希望对你有一定的参考价值。
关于本文说明,本人原博客地址位于http://blog.csdn.net/qq_37608890,本文来自笔者于2018年02月21日 23:10:04所撰写内容(http://blog.csdn.net/qq_37608890/article/details/79343860)。
本文根据最近学习TensorFlow书籍网络文章的情况,特将一些学习心得做了总结,详情如下.如有不当之处,请各位大拿多多指点,在此谢过。
一、相关概念
1、MNIST
MNIST(Mixed National Institute of Standards and Technology database),作为一个常见的数据集,是一个巨大的手写数字数据集,经常被用来测试神经网络,被广泛应用于机器学习识别领域。MNIST 数据集可在 http://yann.lecun.com/exdb/mnist/ 获取, 它包含了四个部分:
-
Training set images: train-images-idx3-ubyte.gz (9.9 MB, 解压后 47 MB, 包含 60,000 个样本)
-
Training set labels: train-labels-idx1-ubyte.gz (29 KB, 解压后 60 KB, 包含 60,000 个标签)
-
Test set images: t10k-images-idx3-ubyte.gz (1.6 MB, 解压后 7.8 MB, 包含 10,000 个样本)
-
Test set labels: t10k-labels-idx1-ubyte.gz (5KB, 解压后 10 KB, 包含 10,000 个标签)
每一个训练元素都是28*28像素的手写数字图片,只有灰度值信息,空白部分为0,笔迹根据颜色深浅取[0, 1], 784维,丢弃二维空间信息,目标分0~9共10类。
2、One-Hot编码
在我们机器学习应用任务的实现过程中,针对有些非连续的数据,我们也会考虑使用数字来进行编码。例如“女人”编码为1,“男人”编码为2,即便如此,二者在数学上不存在连续关系,但是在机器学习算法中,会认为“女人”和“男人”之间存在着数学上的有序关系。
One-Hot编码:独热编码,又被称为一位有效编码,其方法是使用N位状态寄存器来对N个状态进行编码,任意一个状态都有它独立的寄存器位,并且在任意时候只有一位有效。例如上文中说的“女人”和“男人”共有两种状态,那么就可以编码为01和10,对于有N个状态的特征,经过one-hot编码后就会变成N个二元值,而其中只有一个为1。
主要优点如下:
-
解决了分类器不好处理属性数据的问题;
-
在一定程度上也起到了扩充特征的作用;
3、Softmax回归
在 logistic 回归中,我们的训练集由 m 个已标记的样本构成: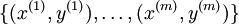 ,其中输入特征
,其中输入特征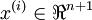 。(我们对符号的约定如下:特征向量
。(我们对符号的约定如下:特征向量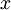 的维度为
的维度为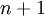 ,其中
,其中 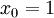 对应截距项 。) 由于 logistic 回归是针对二分类问题的,因此类标记
对应截距项 。) 由于 logistic 回归是针对二分类问题的,因此类标记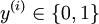 。假设函数(hypothesis function) 如下:
。假设函数(hypothesis function) 如下:
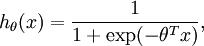
将训练模型参数 \\textstyle \\theta,使其能够最小化代价函数 :
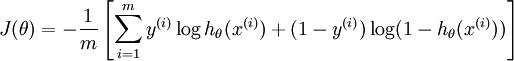
在 softmax回归中,我们解决的是多分类问题(相对于 logistic 回归解决的二分类问题),类标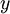 可以取
可以取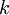 个不同的值(而不是 2 个)。因此,对于训练集
个不同的值(而不是 2 个)。因此,对于训练集 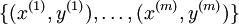 ,我们有
,我们有 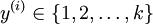 。(注意此处的类别下标从 1 开始,而不是 0)。例如,在 MNIST 数字识别任务中,我们有
。(注意此处的类别下标从 1 开始,而不是 0)。例如,在 MNIST 数字识别任务中,我们有 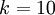 个不同的类别。
个不同的类别。
对于给定的测试输入,我们想用假设函数针对每一个类别j估算出概率值 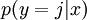 。也就是说,我们想估计 的每一种分类结果出现的概率。因此,我们的假设函数将要输出一个 维的向量(向量元素的和为1)来表示这 个估计的概率值。 具体地说,我们的假设函数
。也就是说,我们想估计 的每一种分类结果出现的概率。因此,我们的假设函数将要输出一个 维的向量(向量元素的和为1)来表示这 个估计的概率值。 具体地说,我们的假设函数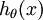 形式如下:
形式如下:
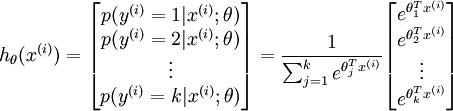
其中 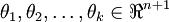 是模型的参数。请注意
是模型的参数。请注意 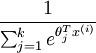 这一项对概率分布进行归一化,使得所有概率之和为 1 。
这一项对概率分布进行归一化,使得所有概率之和为 1 。
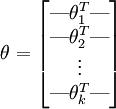
为了方便起见,我们同样使用符号 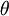 来表示全部的模型参数。在实现Softmax回归时,将 用一个
来表示全部的模型参数。在实现Softmax回归时,将 用一个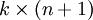 的矩阵来表示会很方便,该矩阵是将
的矩阵来表示会很方便,该矩阵是将 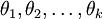 按行罗列起来得到的,如下所示:
按行罗列起来得到的,如下所示:
二、案例一Softmax回归实现
1、简要概述
截止目前,我们已经知道了Logistic函数只能被使用在二分类问题中,但是它的多项式回归,即softmax函数,可以解决多分类问题。假设softmax函数ς的输入数据是C维度的向量z,那么softmax函数的数据也是一个C维度的向量y,里面的值是0到1之间。softmax函数其实就是一个归一化的指数函数,定义如下:
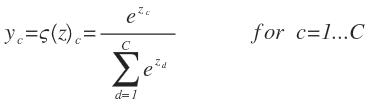
式子中的分母充当了正则项的作用,可以使得
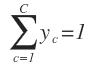
作为神经网络的输出层,softmax函数中的值可以用C个神经元来表示。
对于给定的输入z,我们可以得到每个分类的概率t = c for c = 1 ... C可以表示为:
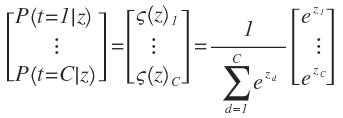
其中,P(t=c|z)表示,在给定输入z时,该输入数据是c分类的概率。
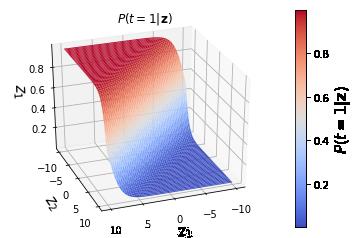
下图展示了在一个二分类(t = 1, t = 2)中,输入向量是z = [z1, z2],那么输出概率P(t=1|z)如下图所示。
2、代码实现过程如下
#Softmax分类函数及其应用代码实现 import numpy as np import matplotlib.pyplot as plt from matplotlib.colors import colorConverter,ListedColormap from mpl_toolkits.mplot3d import Axes3D from matplotlib import cm %matplotlib inline #定义Softmax函数 def softmax(z): return np.exp(z)/np.sum(np.exp(z)) #展示在一个二分类(t=1,t=2)中,输入向量是z=[z1,z2], #那么输出概率为P(t=1|Z)的情况。 nb_of_zs = 200 zs = np.linspace(-10,10,num=nb_of_zs) zs_1, zs_2 = np.meshgrid(zs, zs) y = np.zeros((nb_of_zs,nb_of_zs,2)) for i in range(nb_of_zs): for j in range(nb_of_zs): y[i,j,:] = softmax(np.asarray([zs_1[i,j],zs_2[i,j]])) fig = plt.figure() ax = fig.gca(projection=\'3d\') surf = ax.plot_surface(zs_1,zs_2,y[:,:,0],linewidth =0, cmap=cm.coolwarm) ax.view_init(elev=30,azim=70) cbar = fig.colorbar(surf) ax.set_xlabel(\'$z_1$\', fontsize=15) ax.set_ylabel(\'$z_2$\', fontsize=15) ax.set_zlabel(\'$z_1$\', fontsize=15) ax.set_title(\'$P(t=1|\\mathbf{z})$\') cbar.ax.set_ylabel(\'$P(t=1|\\mathbf{z})$\', fontsize=15) plt.grid() plt.show()
最终生成图像如下:
3、Softmax回归模型参数化的特点
Softmax 回归有一个不寻常的特点:它有一个“冗余”的参数集。为了便于阐述这一特点,假设我们从参数向量 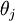 中减去了向量
中减去了向量 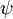 ,这时,每一个 都变成了
,这时,每一个 都变成了  (
(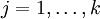 )。此时假设函数变成了以下的式子:
)。此时假设函数变成了以下的式子:
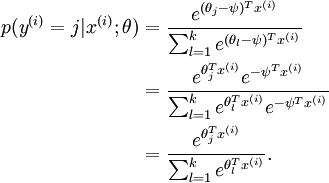
换句话说,从 中减去完全不影响假设函数的预测结果!这表明前面的 softmax 回归模型中存在冗余的参数。更正式一点来说, Softmax 模型被过度参数化了。对于任意一个用于拟合数据的假设函数,可以求出多组参数值,这些参数得到的是完全相同的假设函数 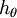 。
。
进一步而言,如果参数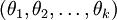 是代价函数
是代价函数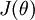 的极小值点,那么
的极小值点,那么 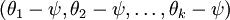 同样也是它的极小值点,其中 可以为任意向量。因此使 最小化的解不是唯一的。(有趣的是,由于 仍然是一个凸函数,因此梯度下降时不会遇到局部最优解的问题。但是 Hessian 矩阵是奇异的/不可逆的,这会直接导致采用牛顿法优化就遇到数值计算的问题)。
同样也是它的极小值点,其中 可以为任意向量。因此使 最小化的解不是唯一的。(有趣的是,由于 仍然是一个凸函数,因此梯度下降时不会遇到局部最优解的问题。但是 Hessian 矩阵是奇异的/不可逆的,这会直接导致采用牛顿法优化就遇到数值计算的问题)。
注意,当 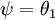 时,我们总是可以将
时,我们总是可以将 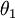 替换为
替换为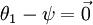 (即替换为全零向量),并且这种变换不会影响假设函数。因此我们可以去掉参数向量 (或者其他 中的任意一个)而不影响假设函数的表达能力。实际上,与其优化全部的
(即替换为全零向量),并且这种变换不会影响假设函数。因此我们可以去掉参数向量 (或者其他 中的任意一个)而不影响假设函数的表达能力。实际上,与其优化全部的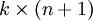 个参数 (其中
个参数 (其中 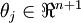 ),我们可以令
),我们可以令 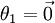 ,只优化剩余的
,只优化剩余的 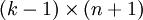 个参数,这样算法依然能够正常工作。
个参数,这样算法依然能够正常工作。
在实际应用中,为了使算法实现更简单清楚,往往保留所有参数 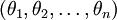 ,而不任意地将某一参数设置为 0。但此时我们需要对代价函数做一个改动:加入权重衰减。权重衰减可以解决 softmax 回归的参数冗余所带来的数值问题。
,而不任意地将某一参数设置为 0。但此时我们需要对代价函数做一个改动:加入权重衰减。权重衰减可以解决 softmax 回归的参数冗余所带来的数值问题。
三、TensorFlow实现Softmax Regression识别手写数字
1、项目背景
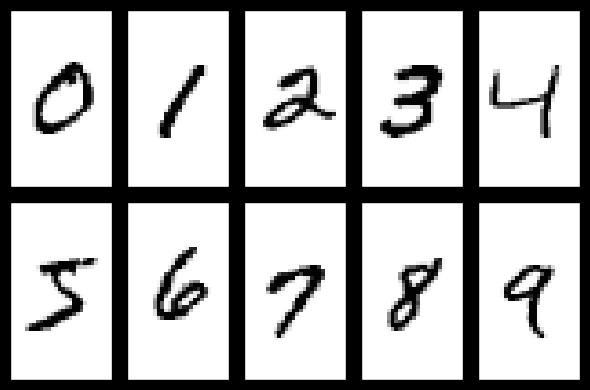
MNIST(Mixed National Institute of Standards and Technology database),简单机器视觉数据集,由几万张28X28像素的手写数字组成,这些图片只包含灰度值信息,空白部分为0,笔迹根据颜色深浅取[0, 1], 784维,我们的目标是对这些手写数字的图片进行分类,转化成0~9共10类。
2、MNIST手写数字图片示例图
3、算法结构特点
-
使用Softmax Regression分类模型进行分类。
-
只有输入层和输出层,没有隐含层。
4、TensorFlow 实现简单机器算法步骤
-
定义算法公式,神经网络forward计算。
-
定义loss,选定优化器,指定优化器优化loss。
-
迭代训练数据。
-
测试集、验证集评测准确率。
5、实现过程
Softmax函数
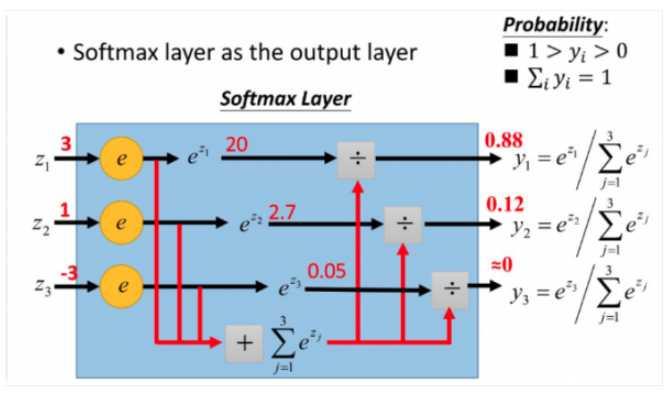
计算过程可视化如下
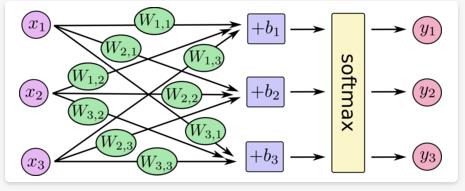
具体代码实现如下
#调用相关数据
from tensorflow.examples.tutorials.mnist import input_data mnist = input_data.read_data_sets("MNIST_data/", one_hot=True) #展示训练集、测试集、验证集样本 print(mnist.train.images.shape, mnist.train.labels.shape) print(mnist.test.images.shape, mnist.test.labels.shape) print(mnist.validation.images.shape, mnist.validation.labels.shape) #图像展示 import numpy as np import matplotlib.pyplot as plt #imshow data imgTol = mnist.train.images img = np.reshape(imgTol[1,:],[28,28]) plt.show()
图像如下
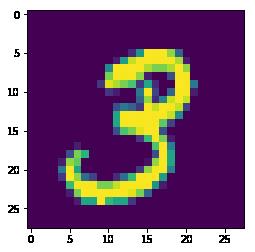
继续执行后续代码,查看Softmax Regression模型的效果情况
import tensorflow as tf sess = tf.InteractiveSession() x=tf.placeholder(tf.float32, [None,784]) W =tf.Variable(tf.zeros([784,10])) b=tf.Variable(tf.zeros([10])) y = tf.nn.softmax(tf.matmul(x,W)+b) y_ =tf.placeholder(tf.float32, [None, 10]) cross_entropy =tf.reduce_mean(-tf.reduce_sum(y_*tf.log(y), reduction_indices=[1])) train_step =tf.train.GradientDescentOptimizer(0.5).minimize(cross_entropy) tf.global_variables_initializer().run() for i in range(1000): batch_xs, batch_ys = mnist.train.next_batch(100) train_step.run({x: batch_xs, y_:batch_ys}) correct_prediction =tf.equal(tf.argmax(y,1),tf.argmax(y_,1)) accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32)) print(accuracy.eval({x: mnist.test.images, y_: mnist.test.labels}))
关于执行准确率情况,笔者测试了7次,结果不尽相同,基本都是0.92左右。
第一次执行结果:0.9216;第二次三次执行结果:0.9171;第四次执行结果:0.9216;第五次执行结果:0.9193;第六次:0.9219;第七次:0.9165。
四、小结
本文涉及TensorFlow实现了一个简单的机器学习算法Softmax Regression,是一个没有隐含层的最浅的神经网络,整个流程在第三部分也提到,这里再次罗列出来,如下:
- 定义算法公式,神经网络forward计算。
- 定义loss,选定优化器,指定优化器优化loss。
- 迭代训练数据。
- 测试集、验证集评测准确率。
这四部分是使用TensorFlow进行算法设计、训练的核心流程,会贯穿神经网络的各类应用。需要提醒的是,我们定义的各个公式其实只是Computation Graph,在执行该行代码时,计算还没有实际发生,只有等调用run方法,并feed数据时计算才真正执行。例如cross_entropy、trian_step、accuracy等都是计算图中的节点,而并不是数据结果,可以通过调用run方法执行这些节点或者讲运算操作来获取结果。
至于第三部分Softmax Regression达到的效果,92%的准确率还不错,但还达不到实用的程度。手写数字的识别主要应用在银行等金融领域,如果准确率不够高,引起的后果将会非常严重。后续文章中,会从感知机、卷积神经网络的角度解决MNIST手写数字识别问题。
关于使用TensorFlow来实现Softmax Regression识别手写数字的撰写,暂时先到此。
主要参考资料《TensorFlow实战》(黄文坚 唐源 著)(电子工业出版社)
以上是关于TensorFlow实战之Softmax Regression识别手写数字的主要内容,如果未能解决你的问题,请参考以下文章
TensorFlow 入门之手写识别(MNIST) softmax算法
tensorflow学习之softmax regression