知识图谱中“三元组”抽取——Python中模型总结实战(基于TensorFlow2.5)
Posted lucky_chaichai
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了知识图谱中“三元组”抽取——Python中模型总结实战(基于TensorFlow2.5)相关的知识,希望对你有一定的参考价值。
目录
一、pyhanlp
【基于java的,安装使用前必须先安装java环境】
1、安装:pip install pyhanlp
【安装过程中会自动安装jpype1,该模块仅支持到python3.7,所以python3.7以上的安装老是报错。】
2、使用:
1)分词
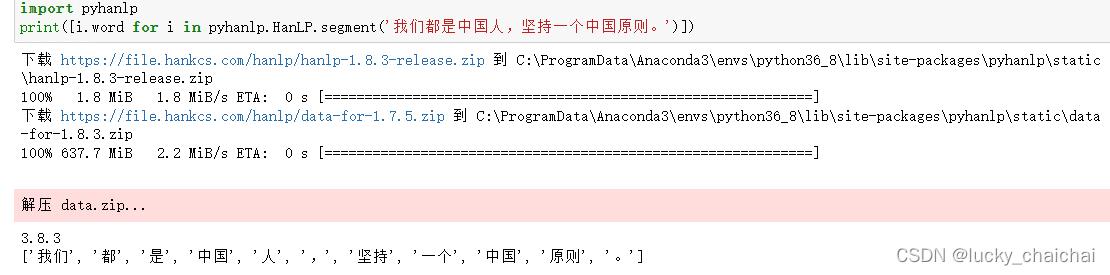
import pyhanlp
print([i.word for i in pyhanlp.HanLP.segment('我们都是中国人,坚持一个中国原则。')])
二、stanfordnlp
【官方GitHub介绍:https://stanfordnlp.github.io/stanfordnlp/training.html】
1、安装:pip 安装
pip install stanfordnlp --proxy 111.666.88.688:808
2、简单使用
import stanfordnlp
三、pyltp
【学习手札:https://blog.csdn.net/MebiuW/article/details/52496920 】
【基于C++的】
四、openNRE
GitHub:https://github.com/thunlp/OpenNRE#datasets
清华大学自然语言处理与社会人文计算实验室(THUNLP)推出的一款开源的神经网络关系抽取工具包,包括了多款常用的关系抽取模型。
使用wiki80数据集,包含80种关系。(也可以自己训练)
但是都是英文数据集,使用也都是基于英文的……
1、安装:我安装到windows上了
cmd中下载git相关安装文件:
git clone https://github.com/thunlp/OpenNRE.git
安装requirements.txt中的模块(括号中是我安装的模块版本)
torch==1.6.0 (1.9.0)
transformers==3.4.0 (4.21.3)
pytest==5.3.2
scikit-learn==0.22.1 (0.23.2)
scipy==1.4.1 (1.4.1)
nltk>=3.6.4 (3.6.2)
安装openNRE
python setup.py develop
2、使用
【注意】
1)windows在导入包的时候会报错:TypeError: expected str, bytes or os.PathLike object, not NoneType
原因:opennre中的pretrain.py中的第13行在windows运行出错(os.getenv(‘HOME’)获取用户主文件地址,windows没有home地址)。
改为:
# default_root_path = os.path.join(os.getenv('HOME'), '.opennre') # Linux
default_root_path = os.path.join(str(Path.home()), 'opennre') # cqf: windows
2)windows在opennre.get_model(‘wiki80_cnn_softmax’)获取模型时报错:wget不是内部执行命令
原因:wget 是一个Linux环境下用于从万维网上提取文件的工具,windows使用时需要单独安装。
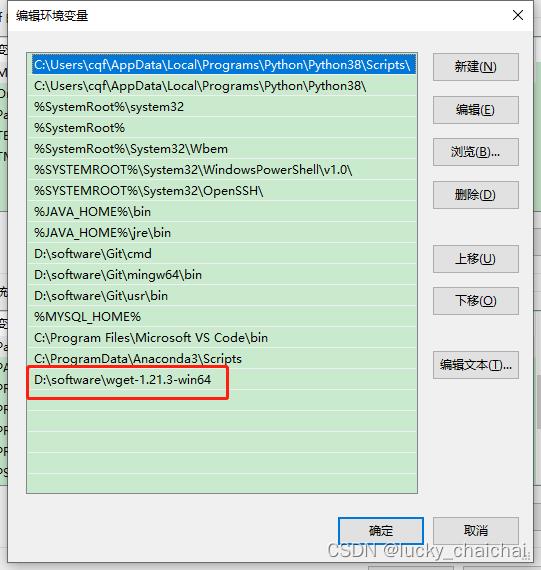
安装:①在网站 https://eternallybored.org/misc/wget/ 上下载windows 上适用的安装包(最新版就可);
②下载完成后解压:比如我下载的是 wget-1.21.3-win64.zip ,解压到 D:\\software\\wget-1.21.3-win64;
③添加环境变量:比如我的
导入模块、加载模型、预测
>>> import opennre
>>> model = opennre.get_model('wiki80_cnn_softmax') # 模型还包括:wiki80_bert_softmax、wiki80_bertentity_softmax、tacred_bert_softmax、tacred_bertentity_softmax
>>> model.infer('text': 'Huang Xiaoming starred in the TV series "the emperor of Han Dynasty", in which he played Emperor Wu of Han Dynasty.', 'h': 'pos':(0,13), 't': 'pos':(41,66))
('notable work', 0.96822190284729)
五、基于TensorFlow 2自定义NER模型(构建、训练与保存模型范例)
NER实质:对目标句子序列进行特征向量表示,然后输入模型,预测句子中每个词对应所有 class 的概率,概率最高的即为其标注结果。
环境要求:(keras4bert环境要求后面单独说明)
keras_bert.__version__ = 0.88.0 # 要求keras >= 2.4.3
keras.__version__ = 2.4.3
tf.__version__ = 2.5.0
tfa.__version__ = 0.16.1
transformers.__version__ = 4.9.1
超参:
# 超参
config_path='data/chinese_L-12_H-768_A-12/bert_config.json'
check_point_path='data/chinese_L-12_H-768_A-12/bert_model.ckpt'
seq_len=200
layer_nums=4 # keras_bert加载BERT时参数output_layer_num的值,BERT模型每个encoder的MultiHeadSelfAttentio层数
training=False
trainable=False
num_label=4
drop_rate=0.3
is_training=True
hidden_size=600
TransBERT_MODEL_NAME='data/bert-base-uncased'
1、BiLSTM+CRF模型
理解说明:
CRF作用:①训练过程中作为损失函数,计算loss;②预测过程中,用于解码,获取得分最高的句子标记结果。
CRF的解码函数:
tfa.text.crf_decode()获取CRF解码结果,即最高分数的句子标记结果,返回结果包括:
① decode_tags: A [batch_size, max_seq_len] matrix, with dtype tf.int32. Contains the highest scoring tag indices.
② best_score: A [batch_size] vector, containing the score of decode_tags.
1、模型构建
import tensorflow as tf
import tensorflow_addons as tfa # 需单独安装
# 基于tf.keras.layers.Layer类定义一个自己的CRF层
class CRF(tf.keras.layers.Layer):
def __init__(self, label_num) -> None:
super().__init__()
self.trans_params = tf.Variable(
tf.random.uniform(shape=(label_num, label_num)), name="transition")
def call(self, inputs, labels, seq_lens):
log_likelihood, self.trans_params = tfa.text.crf_log_likelihood(
inputs, # tensor:[batch_size, max_seq_len, num_tags]
labels, # tensor:[batch_size, max_seq_len]
seq_lens, # seq_lens为各个句子的真实长度(不包括padding的部分,本模型训练也将不存在于vocab中的部分排除)
transition_params=self.trans_params)
loss = tf.reduce_mean(-log_likelihood)
return loss
class BiLSTM_CRF_model(tf.keras.Model):
def __init__(self, embedding_dim, vocab_size, hidden_size, label_num) -> None:
super().__init__()
self.embeding_layer=tf.keras.layers.Embedding(input_dim=vocab_size,
output_dim=embedding_dim,
input_length=None, #Length of input sequences,如果该层后面连接flatten并dense则必须指定input_length。
embeddings_initializer='uniform')
self.bilstm_layer=tf.keras.layers.Bidirectional(tf.keras.layers.LSTM(hidden_size, return_sequences=True),
merge_mode='concat')
self.dense = tf.keras.layers.Dense(label_num)
self.crf_layer=CRF(label_num)
def call(self, input, labels=None, externalEmbed_file=None, training=True):
# tf.math.not_equal()比较x、y相等情况,返回bool类型的tensor,shape同x或y
# tf.cast()强制将给定数据转换为指定数据类型
seq_lens=tf.math.reduce_sum(tf.cast(tf.math.not_equal(input, 0), dtype=tf.int32), axis=-1) # 计算各个橘子的真实长度
if externalEmbed_file:
x=tf.nn.embedding_lookup(externalEmbed_file, input)
else:
x=self.embeding_layer(input)
x=self.bilstm_layer(x)
logits=self.dense(x) # 得到CRF的输入[batch_size, max_seq_len, num_tags]
if training:
labels = tf.convert_to_tensor(labels, dtype=tf.int32)
loss=self.crf_layer(logits, labels, seq_lens)
return loss, logits, seq_lens
else:
return logits, seq_lens
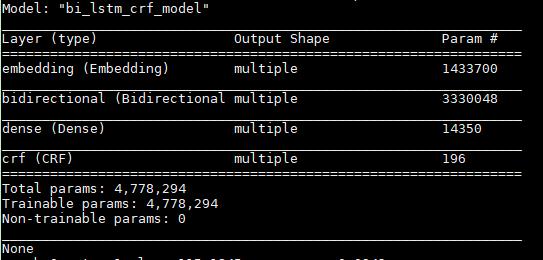
继承tf.keras.Model类构建的模型结构:
2、模型训练与保存:
def get_acc_one_step(logits, text_lens, labels_batch, model):
'''
【这个计算方式不是很好(一般一个句子中什么都不是的部分占比很大,导致即使全部标记结果都是非实体,那最终准确率也很高),
最后准确率普遍偏高,模型效果不咋地,可以尝试计算精确率、召回率】
计算实体识别准确率: 计算每个句子标注的准确率,然后所有句子准确率相加求平均。
'''
paths = []
accuracy = 0
for logit, text_len, labels in zip(logits, text_lens, labels_batch):
viterbi_path, _ = tfa.text.viterbi_decode(logit[:text_len], # BiLSTM_CRF模型中dense层的输出(CRF的输入/model.predict(dataset)结果),[batch_size, max_seq_len, num_tags]
model.get_layer('crf').get_weights()[0] # 获取CRF层的转移矩阵, [num_tags, num_tags]
)
paths.append(viterbi_path)
correct_prediction = tf.equal(
tf.convert_to_tensor(tf.keras.preprocessing.sequence.pad_sequences([viterbi_path], padding='post'),
dtype=tf.int32),
tf.convert_to_tensor(tf.keras.preprocessing.sequence.pad_sequences([labels[:text_len]], padding='post'),
dtype=tf.int32)
)
accuracy = accuracy + tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
accuracy = accuracy / len(paths)
return accuracy
def train_main(vocab_file, tag_file, train_path, output_dir):
# text_sequences, label_sequences分别为token2id、padding之后的句子、标签tensor
train_dataset = tf.data.Dataset.from_tensor_slices((text_sequences, label_sequences)) # 生成text和label一一对应的tensor
train_dataset = train_dataset.shuffle(len(text_sequences)).batch(batch_size, drop_remainder=True) # 打乱上述tensor的顺序并分成多个大小为batch_size的batch
model = BiLSTM_CRF_model(hidden_size = hidden_num, vocab_size = len(vocab2id), label_num= len(tag2id), embedding_dim = embedding_size)
optimizer = tf.keras.optimizers.Adam(lr)
# tf.train.Checkpoint是变量保存与恢复类,只保存模型的参数,不保存模型的计算过程,因此一般用于在具有模型源代码的时候恢复之前训练好的模型参数。
# ckpt.restore(),模型中的变量还没有被建立的时候,Checkpoint 可以等到变量被建立的时候再进行数值的恢复(即提前声明也不会报错)
# tf.train.CheckpointManager()对保存文件管理,指定文件保存路径、文件名前缀、保留的 Checkpoint数目
ckpt = tf.train.Checkpoint(optimizer=optimizer, model=model)
ckpt.restore(tf.train.latest_checkpoint(output_dir)) # 载入已训练的模型文件,以恢复模型(可以进一步训练或者用于预测)。当保存了多个文件时,载入最近的一个
ckpt_manager = tf.train.CheckpointManager(ckpt,
output_dir,
checkpoint_name='bilstm_crf_model.ckpt',
max_to_keep=3)
# 10个epoch,batch_size大小的batch基于Adam优化器(学习率1e-3)循环训练
for epoch in range(10):
for _, (text_batch, labels_batch) in enumerate(train_dataset):
step = step + 1
with tf.GradientTape() as tape:
loss, logits, text_lens = model(text_batch,
labels_batch,
externalEmbed_file=False)
gradients = tape.gradient(loss, model.trainable_variables)
optimizer.apply_gradients(zip(gradients, model.trainable_variables))
if step==1:
print(model.summary())
accuracy = get_acc_one_step(logits, text_lens, labels_batch, model)
print('epoch %d, step %d, loss %.4f , accuracy %.4f' % (epoch, step, loss, accuracy))
if accuracy > best_acc:
best_acc = accuracy
ckpt_manager.save() # 保存训练好的模型的参数(路径中若有不存在的文件夹会自动创建),得到三个文件:checkpoint、.ckpt-28.index、.ckpt-28.data-00000-of-00001
# ckpt.save(model_path_file) # 不通过CheckpointManager的话也可直接保存模型的参数
print("model saved")
if __name__=='__main__':
train_main(vocab_file='data/vocab_file.txt',
tag_file='data/tag_file.txt',
train_path='data/train.txt',
output_dir='checkpoints/')
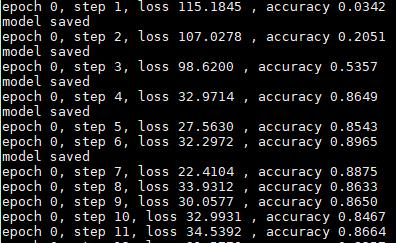
训练结果:loss值、准确率
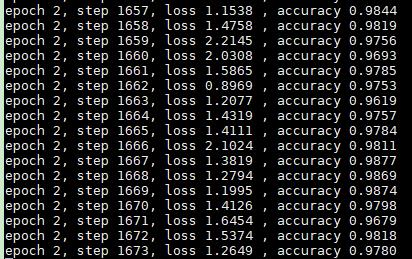
3、使用模型预测:
① 加载训练好的模型参数
② 使用predict()对输入序列预测
③ 基于预测的logit和模型中的转移矩阵,使用tfa.text.viterbi_decode()解码,得到最佳结果路径
def predict_main(vocab_file, tag_file, output_dir):
vocab2id, id2vocab = read_vocab(vocab_file)
tag2id, id2tag = read_vocab(tag_file)
model = BiLSTM_CRF_model(hidden_size = hidden_num,
vocab_size = len(vocab2id),
label_num= len(tag2id),
embedding_dim = embedding_size)
optimizer = tf.keras.optimizers.Adam(lr)
ckpt = tf.train.Checkpoint(optimizer=optimizer, model=model)
ckpt.restore(tf.train.latest_checkpoint(output_dir))
text = input("input:")
dataset = tf.keras.preprocessing.sequence.pad_sequences([[vocab2id.get(char,0) for char in text]], padding='post')
logits, text_lens = model.predict(dataset)
paths = []
for logit, text_len in zip(logits, text_lens):
viterbi_path, _ = tfa.text.viterbi_decode(
logit[:text_len],
model.get_layer('crf').get_weights()[0])
paths.append(viterbi_path)
print('结果路径:',paths) # 结果路径: [[1, 1, 1, 1, 1, 1, 5, 6, 6, 7, 1, 1, 1, 1, 1, 1, 1, 1, 1, 5, 6, 6, 7, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 2, 4, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]]
参考:https://github.com/saiwaiyanyu/bi-lstm-crf-ner-tf2.0
2、BERT+CRF(或 softmax)模型
BERT中包含四种special token,分别是:
[UNK]:指代在vocab中找不到的字/词
[CLS]:添加在每句句首。对于用于分类的向量,会聚集所有的分类信息
[SEP]:添加在每句句尾
[MASK]:使用[MASK]替换句子中的部分字/词。用于MLM(屏蔽语言模型)。
BERT的三种输入(可通过模块中的tokenizer处理得到):字向量token_ids,段向量segment_ids、位置向量position_ids
token_ids:使用 vocab 中的字索引表示的向量集合,shape=(batch_size, seq_len)
segment_ids:当每个文本只有一个句子时,则segment_ids为0向量,shape=(batch_size, seq_len);BERT处理句子对的分类任务时(就是判断两个文本是否是语义相似的),会将两个句子拼接作为输入,此时segment_ids为前一句的0向量和后一句的1向量拼接而成
position_ids:对应位置下标,由于是固定的,会在模型内部生成,不需要手动再输入一遍
1、使用keras_bert:
tokenizer数据处理部分:
from keras_bert import Tokenizer
token2id=
vocab_file=open('data/chinese_L-12_H-768_A-12/vocab.txt', 'r', encoding='utf-8')
for w in vocab_file.readlines():
w=w.strip()
token2id[w]=len(token2id)
tokenizer=Tokenizer(token2id)
r=tokenizer.tokenize('我是中糹国人!') # 对句子分字,并在句首和句尾分别添加[CLS]、[SEP]
print(r) # 结果:['[CLS]', '我', '是', '中', '糹', '国', '人', '!', '[SEP]']
r_encode=tokenizer.encode('我是糹中国人!') # 返回array类型的tikens_id, segments_id
【注意】当输入两个文本时:(与bert4keras很类似)
r=tokenizer.tokenize('我是中糹国人!', second='谁不说俺家乡好,啊啊啊啊!') # 对句子分字,并在句首和句尾分别添加[CLS]、[SEP]
print(r)# 结果:['[CLS]', '我', '是', '中', '糹', '国', '人', '!', '[SEP]']
r_encode=tokenizer.encode('我是糹中国人!', second='谁不说俺家乡好,啊啊啊啊!') # 返回array类型的tikens_id, segments_id
print(r_encode)
结果:

方式一、模型构建代码:继承tf.keras.Model()
bert_model( [tokenid_tensor, segmentid_tensor] )
class NonMaskingLayer(tf.keras.layers.Layer):
def __init__(self, **kwargs):
self.supports_masking = True
super(NonMaskingLayer, self).__init__(**kwargs)
def build(self, input_shape):
pass
def compute_mask(self, inputs, input_mask=None):
# do not pass the mask to the next layers
return None
def call(self, x, mask=None):
return x
class BertCrf(tf.keras.Model):
def __init__(self,
seq_len=200,
bertOut_layer_nums=4,
bertTraining=False,
bertTrainable=False,
num_label=4,
drop_rate=0.3,
is_training=True,
config_path='data/chinese_L-12_H-768_A-12/bert_config.json',
check_point_path='data/chinese_L-12_H-768_A-12/bert_model.ckpt'):
super(BertCrf, self).__init__()
self.config_path=config_path
self.check_point_path=check_point_path
self.seq_len=seq_len
self.layer_nums=bertOut_layer_nums
self.training=bertTraining
self.trainable=bertTrainable
self.num_label=num_label
self.drop_rate=drop_rate
self.is_training=is_training
self.bert_model=keras_bert.load_trained_model_from_checkpoint(
self.config_path,
self.check_point_path,
seq_len=self.seq_len,
output_layer_num=self.layer_nums, # 决定bert输出的最后一个维度是768 * bertOut_layer_nums
training=self.training,
trainable=self.trainable)
self.NonMask_layer=NonMaskingLayer()
self.Dropout_layer=tf.keras.layers.Dropout(self.drop_rate)
self.Dense_layer=tf.keras.layers.Dense(self.num_label)
self.crf_layer=CRF(self.num_label)
def call(self, input, labels=None, train=False):
'''
input: [padded_tokenid_tensor, padded_segmentid_tensor], tensor shape=[batch, seq_len]
'''
seq_reallens=tf.math.reduce_sum(tf.cast(tf.math.not_equal(input[0], 0), dtype=tf.int32), axis=-1)
out_put=self.bert_model(input)
out_put=self.NonMask_layer(out_put)
out_put=self.Dropout_layer(out_put)
logits=self.Dense_layer(out_put)
if train:
labels=tf.convert_to_tensor(labels, dtype=tf.int32电网知识图谱项目总结(1)python代码实现RDF三元组自动化标注
文章目录
简介
本次项目是电网知识图谱相关的,我们的主要任务是三元组的标注和知识图谱的构建,本篇讲述Python代码标注三元组的具体实现,相关知识图谱的构建在后期的内容中再进行总结。
总共有几百个文档(包括几百个预案),刚开始时手动标注一个文档需要两三个小时,长一点的文档得三个多小时,加上三元组关系之多,标注一两个文档头脑一片混乱,盯都盯不住了,心态直接炸裂!在手动标注了一个文档后,我尝试用代码标注,写代码的过程也是特别煎熬,毕竟每一种类型的三元组都得用代码实现,不过写多了就觉得简单了,都是一样的套路。花了一天半时间后,写完了近500行代码,若是足够规范的文档,可保证100%的标注准确率,大部分文档的标注准确率也达到了90%以上。在写代码时为某些不好处理的三元组特意做了模糊标注,所以代码标注后的三元组只需要对照文档内容核对检查修改即可,特别方便,几乎不需要新增。原来一个文档两三个小时的任务最后只需几分钟即可完成,极大地提高了效率!
文档内容
最开始的数据格式是.docx文档,每个word文档中包含了针对特定千伏变电站停电时的具体调度,下面以一个预案的具体结构和内容来作为示例。
以 侯家塘变35千伏其侯线停电风险预案为例,具体内容组织结构如下
-
侯家塘变35千伏其侯线停电风险预案
-
一、事故情况及影响
- 得地调告:侯家塘变全所失电。
- 侯家塘变1号、2号接地变失电,导致1号、2号所用电源失电。
- 两回全停
重要用户有:江苏省金陵监狱 - 一回停电的
双电源用户有:南京自来水公司汤山增压站
-
二、处理过程
-
得地调要求:侯家塘变10千伏负荷移出,并保证悦民变所用变电源
-
配调:
-
(1)恢复所用电
侯家塘变:拉开1号主变101开关、2号主变102开关及所有10千伏出线开关
汤山变:侯家塘线233开关定切保护停用,过流时间由1”改为1.5”
侯家塘变:侯家塘线135开关保护全部停用,合上侯家塘线135开关(汤山变侯家塘线233开关暂供进侯家塘变10千伏Ⅰ段母线转供1号接地变)
悦民变:百镇#1线118开关定切保护停用,过流时间由1”改为1.5”
雨花急修班:合上#6260开关
侯家塘变:官塘线235开关保护全部停用,合上官塘线235开关(悦民变百镇#1线118开关暂供进侯家塘变10千伏 Ⅱ段母线转供2号接地变并恢复江苏省金陵监狱供电)
-
恢复重要用户供电
侯家塘变:合上龙尚线134开关(恢复江苏省金陵监狱、南京自来水公司汤山增压站供电)
-
汇报地调。
-
得地调通知,侯家塘变1号、2号主变已恢复供电,事故方式自行恢复。
其中标黄的内容为每个文档中的固定大纲,部分内容(如变电站等)可能不同,但模式相同,标红的是一些需要标注的部分三元组关键字。
文档内容截图如下

RDF规范
RDF三元组规范如下,共有二十多种类型,要求是将这些三元组标注出并保存在Excel表格中。

以 侯家塘变35千伏其侯线停电风险预案为例,该预案中包含的所有三元组如下:
35千伏侯家塘变全停事故预案 事故情况 得地调告:侯家塘变全所失电。
35千伏侯家塘变全停事故预案 事故原因 侯家塘变1号、2号接地变失电,导致1号、2号所用电源失电。
35千伏侯家塘变全停事故预案 事故影响 两回全停的重要用户有:江苏省金陵监狱
35千伏侯家塘变全停事故预案 事故影响 一回停电的双电源用户有:南京自来水公司汤山增压站
35千伏侯家塘变全停事故预案 处理过程 得地调要求:侯家塘变10千伏负荷移出,并保证悦民变所用变电源
得地调要求:侯家塘变10千伏负荷移出,并保证悦民变所用变电源 下一步骤 侯家塘变:拉开1号主变101开关、2号主变102开关及所有10千伏出线开关
侯家塘变:拉开1号主变101开关、2号主变102开关及所有10千伏出线开关 下一步骤 汤山变:侯家塘线233开关定切保护停用,过流时间由1”改为1.5”
汤山变:侯家塘线233开关定切保护停用,过流时间由1”改为1.5” 下一步骤 侯家塘变:侯家塘线135开关保护全部停用,合上侯家塘线135开关(汤山变侯家塘线233开关暂供进侯家塘变10千伏Ⅰ段母线转供1号接地变)
侯家塘变:侯家塘线135开关保护全部停用,合上侯家塘线135开关(汤山变侯家塘线233开关暂供进侯家塘变10千伏Ⅰ段母线转供1号接地变) 下一步骤 悦民变:百镇#1线118开关定切保护停用,过流时间由1”改为1.5”
悦民变:百镇#1线118开关定切保护停用,过流时间由1”改为1.5” 下一步骤 雨花急修班:合上#6260开关
雨花急修班:合上#6260开关 下一步骤 侯家塘变:官塘线235开关保护全部停用,合上官塘线235开关(悦民变百镇#1线118开关暂供进侯家塘变10千伏 Ⅱ段母线转供2号接地变并恢复江苏省金陵监狱供电)
侯家塘变:官塘线235开关保护全部停用,合上官塘线235开关(悦民变百镇#1线118开关暂供进侯家塘变10千伏 Ⅱ段母线转供2号接地变并恢复江苏省金陵监狱供电) 下一步骤 侯家塘变:合上龙尚线134开关(恢复江苏省金陵监狱、南京自来水公司汤山增压站供电)
侯家塘变:合上龙尚线134开关(恢复江苏省金陵监狱、南京自来水公司汤山增压站供电) 下一步骤 汇报地调
回报地调 下一步骤 得地调通知,侯家塘变1号、2号主变已恢复供电,事故方式自行恢复。
侯家塘变1号、2号接地变失电,导致1号、2号所用电源失电。 失电(主) 侯家塘变1号接地变
侯家塘变1号、2号接地变失电,导致1号、2号所用电源失电。 失电(主) 侯家塘变2号接地变
侯家塘变1号、2号接地变失电,导致1号、2号所用电源失电。 失电(被) 侯家塘变1号所用电源
侯家塘变1号、2号接地变失电,导致1号、2号所用电源失电。 失电(被) 侯家塘变2号所用电源
得地调告:侯家塘变全所失电。 两回全停 江苏省金陵监狱
江苏省金陵监狱 属性 重要用户
得地调告:侯家塘变全所失电。 一回停电 南京自来水公司汤山增压站
南京自来水公司汤山增压站 属性 双电源用户
南京自来水公司汤山增压站 属性 重要用户
得地调要求:侯家塘变10千伏负荷移出,并保证悦民变所用变电源 移出 侯家塘变10千伏负荷
得地调要求:侯家塘变10千伏负荷移出,并保证悦民变所用变电源 保证 悦民变所用变电源
侯家塘变:拉开1号主变101开关、2号主变102开关及所有10千伏出线开关 属性 恢复所供电
汤山变:侯家塘线233开关定切保护停用,过流时间由1”改为1.5” 属性 恢复所供电
侯家塘变:侯家塘线135开关保护全部停用,合上侯家塘线135开关(汤山变侯家塘线233开关暂供进侯家塘变10千伏Ⅰ段母线转供1号接地变) 属性 恢复所供电
悦民变:百镇#1线118开关定切保护停用,过流时间由1”改为1.5” 属性 恢复所供电
雨花急修班:合上#6260开关 属性 恢复所供电
侯家塘变:官塘线235开关保护全部停用,合上官塘线235开关(悦民变百镇#1线118开关暂供进侯家塘变10千伏 Ⅱ段母线转供2号接地变并恢复江苏省金陵监狱供电) 属性 恢复所供电
侯家塘变:拉开1号主变101开关、2号主变102开关及所有10千伏出线开关 恢复所供电 侯家塘变
汤山变:侯家塘线233开关定切保护停用,过流时间由1”改为1.5” 恢复所供电 侯家塘变
侯家塘变:侯家塘线135开关保护全部停用,合上侯家塘线135开关(汤山变侯家塘线233开关暂供进侯家塘变10千伏Ⅰ段母线转供1号接地变) 恢复所供电 侯家塘变
悦民变:百镇#1线118开关定切保护停用,过流时间由1”改为1.5” 恢复所供电 侯家塘变
雨花急修班:合上#6260开关 恢复所供电 侯家塘变
侯家塘变:官塘线235开关保护全部停用,合上官塘线235开关(悦民变百镇#1线118开关暂供进侯家塘变10千伏 Ⅱ段母线转供2号接地变并恢复江苏省金陵监狱供电) 恢复所供电 侯家塘变
侯家塘变:侯家塘线135开关保护全部停用,合上侯家塘线135开关(汤山变侯家塘线233开关暂供进侯家塘变10千伏Ⅰ段母线转供1号接地变) 操作分支 侯家塘变:侯家塘线135开关保护全部停用,合上侯家塘线135开关
侯家塘变:侯家塘线135开关保护全部停用,合上侯家塘线135开关(汤山变侯家塘线233开关暂供进侯家塘变10千伏Ⅰ段母线转供1号接地变) 操作分支 汤山变侯家塘线233开关暂供进侯家塘变10千伏Ⅰ段母线转供1号接地变
侯家塘变:侯家塘线135开关保护全部停用,合上侯家塘线135开关 等价操作 汤山变侯家塘线233开关暂供进侯家塘变10千伏Ⅰ段母线转供1号接地变
侯家塘变:官塘线235开关保护全部停用,合上官塘线235开关(悦民变百镇#1线118开关暂供进侯家塘变10千伏 Ⅱ段母线转供2号接地变并恢复江苏省金陵监狱供电) 操作分支 侯家塘变:官塘线235开关保护全部停用,合上官塘线235开关
侯家塘变:官塘线235开关保护全部停用,合上官塘线235开关(悦民变百镇#1线118开关暂供进侯家塘变10千伏 Ⅱ段母线转供2号接地变并恢复江苏省金陵监狱供电) 操作分支 悦民变百镇#1线118开关暂供进侯家塘变10千伏 Ⅱ段母线转供2号接地变并恢复江苏省金陵监狱供电
侯家塘变:官塘线235开关保护全部停用,合上官塘线235开关 等价操作 悦民变百镇#1线118开关暂供进侯家塘变10千伏 Ⅱ段母线转供2号接地变并恢复江苏省金陵监狱供电
侯家塘变:拉开1号主变101开关、2号主变102开关及所有10千伏出线开关 拉开 侯家塘变1号主变101开关
侯家塘变:拉开1号主变101开关、2号主变102开关及所有10千伏出线开关 拉开 侯家塘变2号主变102开关
侯家塘变:拉开1号主变101开关、2号主变102开关及所有10千伏出线开关 拉开 侯家塘变10千伏出线开关
汤山变:侯家塘线233开关定切保护停用,过流时间由1”改为1.5” 定切保护停用 汤山变侯家塘线233开关
汤山变:侯家塘线233开关定切保护停用,过流时间由1”改为1.5” 过流时间由1”改为1.5” 汤山变侯家塘线233开关
侯家塘变:侯家塘线135开关保护全部停用,合上侯家塘线135开关(汤山变侯家塘线233开关暂供进侯家塘变10千伏Ⅰ段母线转供1号接地变) 保护全部停用 侯家塘变侯家塘线135开关
侯家塘变:侯家塘线135开关保护全部停用,合上侯家塘线135开关(汤山变侯家塘线233开关暂供进侯家塘变10千伏Ⅰ段母线转供1号接地变) 合上 侯家塘变侯家塘线135开关
悦民变:百镇#1线118开关定切保护停用,过流时间由1”改为1.5” 定切保护停用 悦民变百镇#1线118开关
悦民变:百镇#1线118开关定切保护停用,过流时间由1”改为1.5” 过流时间由1”改为1.5” 悦民变百镇#1线118开关
雨花急修班:合上#6260开关 合上 #6260开关
侯家塘变:官塘线235开关保护全部停用,合上官塘线235开关(悦民变百镇#1线118开关暂供进侯家塘变10千伏 Ⅱ段母线转供2号接地变并恢复江苏省金陵监狱供电) 保护全部停用 侯家塘变官塘线235开关
侯家塘变:官塘线235开关保护全部停用,合上官塘线235开关(悦民变百镇#1线118开关暂供进侯家塘变10千伏 Ⅱ段母线转供2号接地变并恢复江苏省金陵监狱供电) 合上 侯家塘变官塘线235开关
侯家塘变:合上龙尚线134开关(恢复江苏省金陵监狱、南京自来水公司汤山增压站供电) 合上 龙尚线134开关
侯家塘变:合上龙尚线134开关(恢复江苏省金陵监狱、南京自来水公司汤山增压站供电) 属性 恢复重要用户供电
侯家塘变:合上龙尚线134开关(恢复江苏省金陵监狱、南京自来水公司汤山增压站供电) 恢复重要用户供电 江苏省金陵监狱
侯家塘变:合上龙尚线134开关(恢复江苏省金陵监狱、南京自来水公司汤山增压站供电) 恢复重要用户供电 南京自来水公司汤山增压站供电
侯家塘变1号主变101开关 属于 侯家塘变
侯家塘变2号主变102开关 属于 侯家塘变
汤山变侯家塘线233开关 属于 汤山变
侯家塘变侯家塘线135开关 属于 侯家塘变
侯家塘变10千伏Ⅰ段母线 属于 侯家塘变
侯家塘变1号接地变 属于 侯家塘变
悦民变百镇#1线118开关 属于 悦民变
侯家塘变官塘线235开关 属于 侯家塘变
侯家塘变龙尚线134开关 属于 侯家塘变
雨花急修班#6260开关 属于 雨花急修班
标注思路
总体来说整个过程可分为三步:
- 读取docx文件(
import docx) - 标注(对
str字符的处理) - 写入xlsx文件(
import openpyxl)
在读取内容后,为了处理字符串的方便,将每段内容句首和句末的空格、制表符、标点符号等去除。
其中最麻烦的是标注代码的编写,本质就是对字符串的一些处理技巧,这个只要掌握了字符串的分割和特定字符的位置查找其实也不难实现。
在三元组分类时要考虑以下两个问题:
- 哪几种类型的三元组放在一起处理比较好?
- 哪些内容段包含哪几种类型的三元组?
首先根据三元组的分布对内容进行大致划分,得到固定标题下的内容,这样方便后面特定三元组的处理,缩小查找范围。如layer1和layer2层下的内容,datas是所有内容,datas1是二、处理过程:下的内容。在处理特定三元组的时候,看它出现在哪些特定的内容中,或者某几条内容中包含几种类型的三元组。根据大致位置和三元组关键词找到包含三元组内容的具体位置,然后根据关键字、标点符号、以及三元组特征对内容进行拆分、拼接和添加,从而得到最后的结果。
下面举两个例子方便大家更好地了解:
内容一:
一、事故情况及影响
得地调告:侯家塘变全所失电
侯家塘变1号、2号接地变失电,导致1号、2号所用电源失电
两回全停重要用户有:江苏省金陵监狱。
一回停电的双电源用户有:南京自来水公司汤山增压站。
对于上面这段内容,由于它是连续的,先不考虑每个句子中包含的其他三元组,我们发现事故情况、事故原因、事故影响这几个三元组放在一起处理比较好,在得到标题后依次写入即可。对应代码中的函数为def step_1(datas, name, layer1, layer2)。
35千伏侯家塘变全停事故预案 事故情况 得地调告:侯家塘变全所失电。
35千伏侯家塘变全停事故预案 事故原因 侯家塘变1号、2号接地变失电,导致1号、2号所用电源失电。
35千伏侯家塘变全停事故预案 事故影响 两回全停的重要用户有:江苏省金陵监狱
35千伏侯家塘变全停事故预案 事故影响 一回停电的双电源用户有:南京自来水公司汤山增压站
内容二:
侯家塘变1号、2号接地变失电,导致1号、2号所用电源失电。
首先是事故原因三元组,这个只要得到标题就可以构成三元组。(这一条我是按照内容一中程相关的三元组一起处理的)
35千伏侯家塘变全停事故预案 事故原因 侯家塘变1号、2号接地变失电,导致1号、2号所用电源失电。
其次是失电(主)和失电(被),首先定位接地变对前段话中**“1号”和“2号”进行检测根据顿号、拆分,得到“失电(主)“三元组,之后定位所用电源对后半句话同样进行字符定位拆分,得到”失电(被)“**三元组。对应代码中的函数为def step_3(datas, layer1)。
侯家塘变1号、2号接地变失电,导致1号、2号所用电源失电。 失电(主) 侯家塘变1号接地变
侯家塘变1号、2号接地变失电,导致1号、2号所用电源失电。 失电(主) 侯家塘变2号接地变
侯家塘变1号、2号接地变失电,导致1号、2号所用电源失电。 失电(被) 侯家塘变1号所用电源
侯家塘变1号、2号接地变失电,导致1号、2号所用电源失电。 失电(被) 侯家塘变2号所用电源
代码结构
其他的三元组处理方式与此类似,下面是整个代码的函数结构图,详解介绍了各个函数的功能和所要处理的三元组。
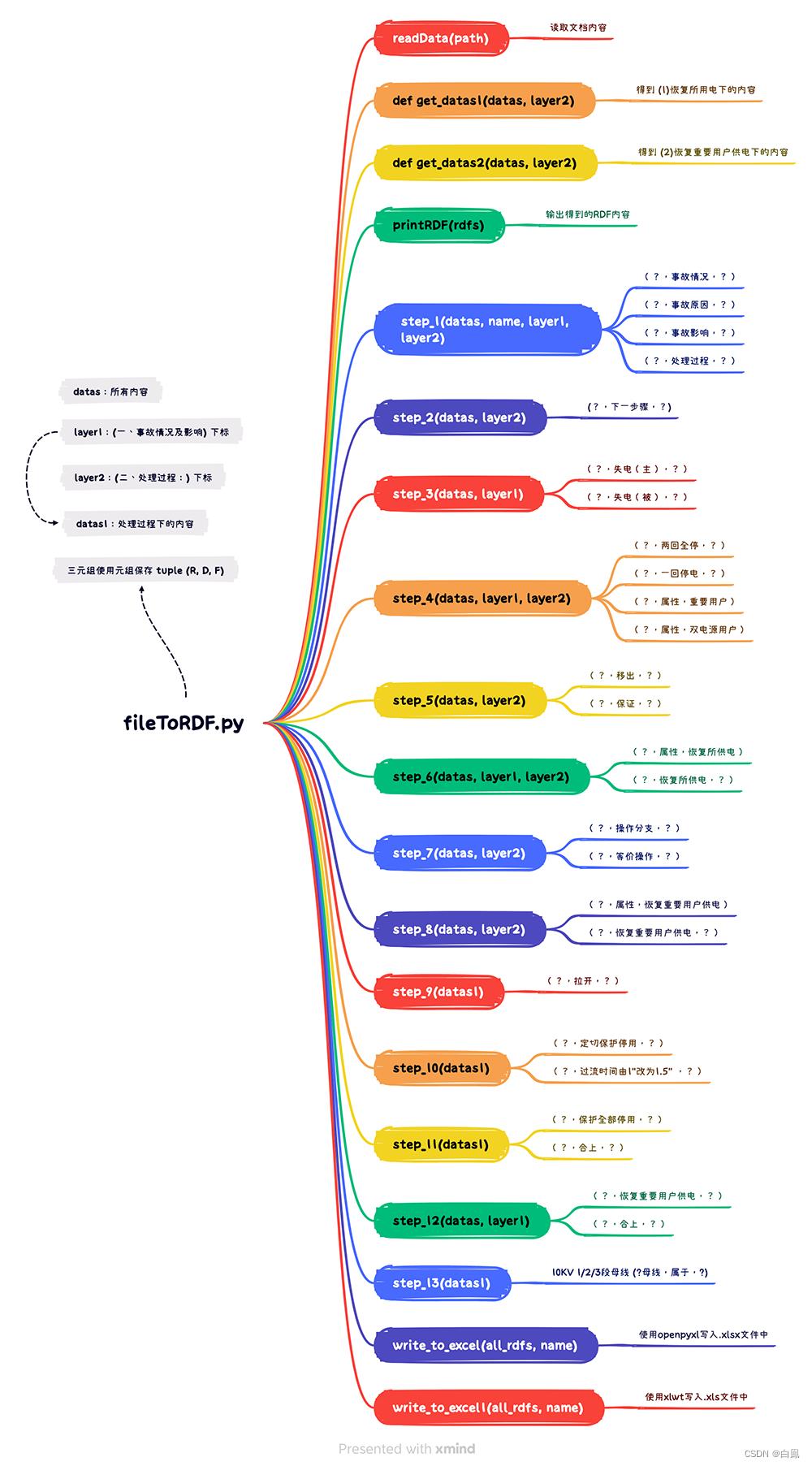
详细代码
import docx
import xlwt
import openpyxl
import os
switches_rdf = []
def readData(path):
file = docx.Document(path)
datas = []
for p in file.paragraphs:
cur = str(p.text.strip())
cur.replace('\\n', '').replace('\\r', '').replace(' ', '')
if cur != "":
datas.append(cur)
return datas
def printRDF(rdfs):
if rdfs is None:
return
for rdf in rdfs:
print(rdf)
# RDF 三元组使用 tuple 存储 (R, D, F)
# step_1 事故情况、事故原因、事故影响、处理过程
def step_1(datas, name, layer1, layer2):
rdf1 = []
for i in range(layer1 + 1, layer2):
data = datas[i]
if data.count("得地调告"):
rdf1.append((name, "事故情况", data))
elif data.count("导致"):
rdf1.append((name, "事故原因", data))
elif data.count("用户"):
if data[-1] != "无":
rdf1.append((name, "事故影响", data))
rdf1.append((name, "处理过程", datas[layer2 + 1][2:]))
return rdf1
# setp_2 (?, 下一步骤, ?)
def step_2(datas, layer2):
cycle_data = []
for i in range(layer2 + 1, len(datas)):
data = datas[i]
if data.count("1、得地调要求:"):
cycle_data.append(data[2:])
elif data.count("2、配调:") or data.count("(1)恢复所用电") or data.count("(2)恢复重要用户供电"):
pass
elif data.count("3、汇报地调"):
cycle_data.append(data[2:])
elif data.count("4、得地调通知"):
cycle_data.append(data[2:])
else:
cycle_data.append(data)
# 使用循环加入三元组
rdf2 = []
for i in range(0, len(cycle_data) - 1):
rdf2.append((cycle_data[i], "下一步骤", cycle_data[i + 1]))
return rdf2
# step3 失电(主),失电(被)
def step_3(datas, layer1):
data = datas[layer1 + 2]
head_id = data.find("1号")
head_name = data[:head_id]
# 使用 , 划分前后部分
data_sp = data.split(',')
rdf3 = []
for i in range(1, 5):
if data_sp[0].count(str(i) + "号"):
rdf3.append((data, "失电(主)", head_name + str(i) + "号接地变"))
# add switches_rdf
switches_rdf.append((head_name + str(i) + "号接地变", "属于", head_name))
for i in range(1, 5):
if data_sp[1].count(str(i) + "号"):
rdf3.append((data, "失电(被)", head_name + str(i) + "号所用电源"))
return rdf3
# step_4 两回全停、一回停电, 重要度,属性
def step_4(datas, layer1, layer2):
s1 = datas[layer1 + 1]
fst_s, sec_s = "", ""
for i in range(layer1 + 1, layer2):
if datas[i].find("两回全停") == 0:
fst_s = datas[i]
elif datas[i].find("一回停电") == 0:
sec_s = datas[i]
# 找出两回全停的地点
fst_s1 = fst_s.split(":")
fst_s_list = fst_s1[1].split("、")
# 找出一回停电的地点
sec_s1 = sec_s.split(":")
sec_s_list = sec_s1[1].split("、")
rdf4 = []
# 加入 两回全停、一回停电 三元组
for s in fst_s_list:
if s != "无":
rdf4.append((s1, "两回全停", s))
for s in sec_s_list:
if s != "无":
rdf4.append((s1, "一回停电", s))
# 处理属性问题 (双电源、 重要用户)
if fst_s1[0].count("重要"):
for s in fst_s_list:
if s != "无":
rdf4.append((s, "属性", "重要用户"))
if sec_s1[0].count("重要"):
for s in sec_s_list:
if s != "无":
rdf4.append((s, "属性", "重要用户"))
if fst_s1[0].count("双电源"):
for s in fst_s_list:
if s != "无":
rdf4.append((s, "属性", "双电源用户"))
if sec_s1[0].count("双电源"):
for s in sec_s_list:
if s != "无":
rdf4.append((s, "属性", "双电源用户"))
return rdf4
# step_5 (?, 移出, ?) , (?, 保证, ?)
def step_5(datas, layer2):
data = datas[layer2 + 1][2:]
parts = data[data.find(":") + 1:].split(",")
id1 = parts[0].find("移出")
id2 = parts[1].find("保证")
rdf5 = []
rdf5.append((data, "移出", parts[0][:id1]))
rdf5.append((data, "保证", parts[1][id2 + 2:]))
return rdf5
# step_6 (?, 属性, 恢复所供电) (?, 恢复所供电, ?)
def step_6(datas, layer1, layer2):
id1, id2 = 0, 0
for i in range(layer2 + 1, len(datas))以上是关于知识图谱中“三元组”抽取——Python中模型总结实战(基于TensorFlow2.5)的主要内容,如果未能解决你的问题,请参考以下文章