HashSet和TreeSet的区别
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了HashSet和TreeSet的区别相关的知识,希望对你有一定的参考价值。
HashSet
无序(存入和取出的顺序不同),不重复,无索引
底层是哈希表结构,也称散列表结构,查找和删除快,添加慢
像HashSet中存储自定义对象需要重写hashCode()和equals()方法
import java.util.HashSet;
import java.util.Iterator;
/**
* 演示HashSet是如何保证元素的唯一性的
* @author WangShuang
*
*/
public class Demo {
public static void main(String[] args) {
Person p = new Person("张三","男");
Person p1 = new Person("张三","男");
HashSet<Person> hashSet=new HashSet<Person>();
hashSet.add(p);
hashSet.add(p1);
Iterator<Person> iterator = hashSet.iterator();
while(iterator.hasNext()){
Person next = iterator.next();
System.out.println(next);
}
}
}
class Person{
private String name;
private String sex;
public Person(String name, String sex) {
this.name = name;
this.sex = sex;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getSex() {
return sex;
}
public void setSex(String sex) {
this.sex = sex;
}
@Override
public int hashCode() {
return name.hashCode()+sex.hashCode() ;
}
@Override
public boolean equals(Object obj) {
if(!(obj instanceof Person)){
return false;
}
Person p = (Person)obj;
return this.name.equals(p.name)&& this.sex.equals(p.sex);
}
@Override
public String toString() {
return "Person [name=" + name + ", sex=" + sex + "]";
}
}HashSet在存元素时,会调用对象的hashCode方法计算出存储位置,然后和该位置上所有的元素进行equals比较,
如果该位置没有其他元素或者比较的结果都为false就存进去,否则就不存。
这样的原理注定了元素是按照哈希值来找存储位置,所有无序,而且可以保证无重复元素
我们在往HashSet集合存储元素时,对象应该正确重写Object类的hashCode和equals方法
正因为这样的原理,HashSet集合是非常高效的。
比如,要查找集合中是否包含某个对象,首先计算对象的hashCode,折算出位置号,到该位置上去找就可以了,而不用和所有的元素都比较一遍
TreeSet
可以对set集合中的元素进行排序,默认按照asic码表的自然顺序排序
之所以treeset能排序是因为底层是二叉树,数据越多越慢,TreeSet是依靠TreeMap来实现的
像TreeSet中存储自定义对象需要实现comparable接口
import java.util.Iterator;
import java.util.TreeSet;
/**
* 让人根据年龄排序,如果年龄一样根据姓名的自然顺序排序
* @author WangShuang
*
*/
public class Demo {
public static void main(String[] args) {
Person p0 = new Person("张三",3);
Person p = new Person("张三",1);
Person p1 = new Person("张三",2);
Person p2 = new Person("张四",2);
Person p3 = new Person("张四",2);
TreeSet<Person> treeSet=new TreeSet<Person>();
treeSet.add(p0);
treeSet.add(p);
treeSet.add(p1);
treeSet.add(p2);
treeSet.add(p3);
Iterator<Person> iterator = treeSet.iterator();
while(iterator.hasNext()){
Person next = iterator.next();
System.out.println(next);
}
}
}
class Person implements Comparable<Person>{//该接口强制让人具有比较性
private String name;
private int age;
public Person(String name,int age) {
this.name = name;
this.age=age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public int compareTo(Person o) {
if(this.age>o.age){
return 1;
}else if(this.age<o.age){
return -1;
}else{
return this.name.compareTo(o.name);
}
}
@Override
public String toString() {
return "Person [name=" + name + ", age=" + age + "]";
}
}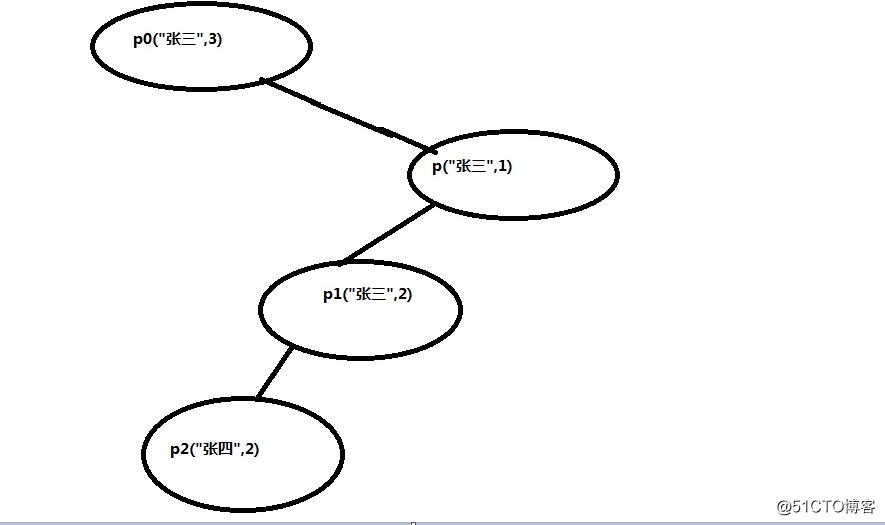
首先把p0("张三,3)存到根部,
然后p("张三",1)调用compareTo()方法和p0("张三,3)比较年龄,小的放在右边,
然后p1(“张三”,2)调用,调用compareTo()方法和p0("张三,3)比较年龄,小的放在右边,因为右边有p("张三",1),在调用ompareTo()方法和p("张三",1),大的放在左边,
然后p2("张四",2)调用compareTo()方法和p0("张三,3)比较年龄,小的放在右边,因为右边有p("张三",1),在调用ompareTo()方法和p("张三",1),大的放在左边,因为左边有p1(“张三”,2),调用ompareTo()方法和p1(“张三”,2),年龄一样,比较姓名,大的放在左边,
然后p3("张四",2)调用compareTo()方法和p0("张三,3)比较年龄,小的放在右边,因为右边有p("张三",1),在调用ompareTo()方法和p("张三",1),大的放在左边,因为左边有p1(“张三”,2),调用ompareTo()方法和p1(“张三”,2),年龄一样,比较姓名,大的放在左边,因为左边有p2("张四",2),调用ompareTo()方法和p2(“张四”,2),姓名一样,年龄一样,去除重复
以上是关于HashSet和TreeSet的区别的主要内容,如果未能解决你的问题,请参考以下文章