ng机器学习视频笔记 ——机器学习系统调试(cv查准率与召回率等)
Posted lin_h
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ng机器学习视频笔记 ——机器学习系统调试(cv查准率与召回率等)相关的知识,希望对你有一定的参考价值。
ng机器学习视频笔记(八)
——机器学习系统调试(cv、查准率与召回率等)
(转载请附上本文链接——linhxx)
一、样本集使用方案
1、测试集
为了验证系统设计的是否准确,通常需要预留10%-20%的样本集,作为测试集,校验模型的准确率。测试集也有其对应的代价函数,其代价函数与对应的训练集的代价函数形式上一样,区别在于此处不加上正则化项,另外带入的数据是预留作为测试集的样本集的数据,这部分数据是没有参与训练的数据。

2、交叉验证集(cross validation set,简称CV)
为了验证假设函数h(x)中,x的次数是否过高或者过低,即验证是否存在欠拟合与过拟合的情况,会从训练集中,再预留一部分数据,作为交叉验证集。
和测试集的区别 ,在于测试集是不可用参与模型设计的全过程,仅仅用于测试。交叉验证集,是在训练模型的时候,每次从训练集中取一些数据,作为验证假设函数是否正确的数据。然后换几个不同的x的次数,再换一批数据作为验证数据。最终得到一个代价函数最小的值,此时的x的次数即为最好的。
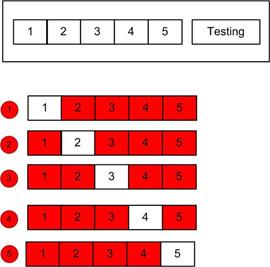
3、代价函数计算公式
实际上,公式和原始的公式没有很大区别,仅仅区别在于输入的数据不同。

二、高偏差和高方差
1、x的次数
绘制图像,纵轴是代价函数的值,横向是x的次数。会发现,x次数较小时,交叉验证和训练数据的代价函数都很大,此时既高方差(过拟合)又高偏差(欠拟合),模型非常不好。
随着x的次数增大,两者一起降低。当降到某个值,x次数再增加时,训练数据的代价函数会略微降低,但交叉验证的代价函数会显著升高,逐渐出现过拟合。
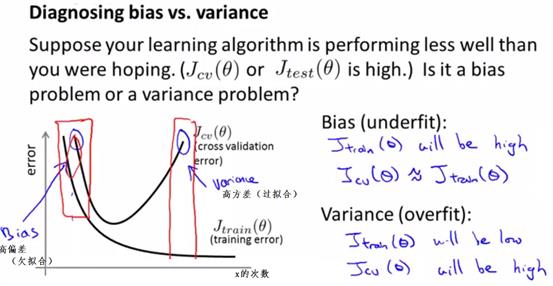
从上图也可以观察到,高偏差:cv和训练的代价函数都很大;高方差:cv的代价函数很大,训练的代价函数很小。
2、正则化对方差和偏差的影响
考虑正则化的时候,仅仅在计算权重θ的时候使用正则化,而在计算训练代价函数、交叉验证代价函数和测试代价函数的时候,不加入正则化项。

观察上面的代价函数,对于λ,值太小则等同于没有使用正则化,此时训练集会很准确,但是交叉集误差会很大,此时属于过拟合。
当λ增大 ,交叉验证的代价函数逐渐降低,训练的代价函数逐渐升高。当超过某个值,交叉验证的代价函数也会开始升高,此时即开始欠拟合。
极端情况下,λ值非常大,则此时除了θ0,其他的θ都会约等于0,h(x)变成一条直线,欠拟合。
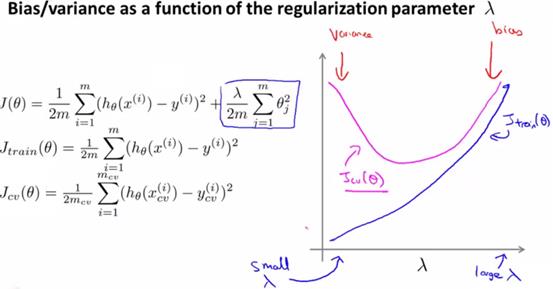
对于λ选取,通常可以先从0开始,然后0.01、0.02、0.04…逐渐2倍的增大,直到确定一个最优的值。
三、学习曲线
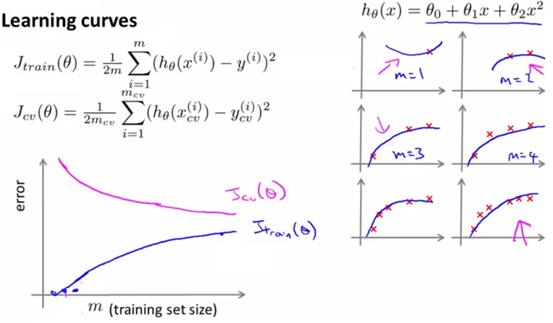
学习曲线(learning curve),也是一个衡量是否过拟合、欠拟合的工具。学习曲线是一种图形。其横坐标是训练集的数量,纵坐标是代价函数的值。
1、正常情况
在没有过拟合和欠拟合时,随着训练数量的增加,cv和训练集的代价函数逐渐一致,且保持在一个不会很高的值。
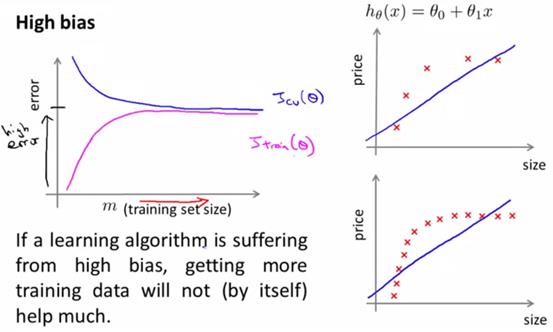
2、高偏差(欠拟合)
高偏差情况下,即x的次数太低,此时很快就无法用假设函数来表达训练集了,而训练集的数量再增加也没有很大的意义。
此时,学习曲线上,很快cv和训练集就几乎相等了,且保持在一个很高的代价函数上。训练集无论怎么增大,基本这两个代价函数都不会变了。
因此,学习曲线中,cv和训练集都保持的很高,而且数据集增大不会缓解,就表示很有可能欠拟合了。
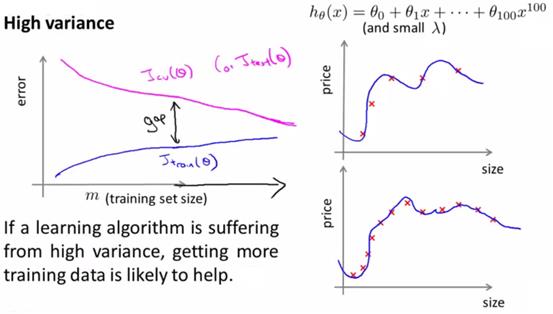
3、高方差(过拟合)
高方差情况下,在数据集不够大的情况下,cv很大,训练集很小,两者差距非常大。随着训练集无限增大,逐渐cv和训练集会接近,且代价函数都比较小。
因此,训练集增大对于过拟合有改善意义。
四、参数调整策略
当训练模型的误差很大时,先画出学习曲线,确定是过拟合还是欠拟合,接着:
过拟合:增加数据集样本、减少特征数、增加正则化参数λ;
欠拟合:减少特征数、增加x的次数、减小正则化参数λ。
对于神经网络,隐藏层少的神经网络,容易欠拟合,但是计算机计算量小;隐藏层多的神经网络,如果训练集不够多,有可能过拟合,同时计算量大。但是对于神经网络,通常建议层数多一些,层数越多效果往往越好。
五、误差分析
误差分析有三种方式:精确度(accuracy)、查准率(precision)、召回率(recall)。
1、精确度
精确度很容易知道,即精确度=预测正确数量/总预测数量。这是衡量模型是否估算正确的一个常用方法。
但是,在一个特殊情况下,精确度无法衡量模型的好坏。
考虑一种称为偏差类(skewed class)的情况,假设最终结果只有y=0或1,现在需要根据x预测y是否是1。例如y=1表示中彩票,由于中彩票的概率很低,因此假设在未知x的前提下,y=0的概率是99.95%,y=1的概率是0.05%。
现在,如果根据特征值x来预测y=1,精确度是99%,即存在1%的误差。对于这种情况下,这个1%的误差其实非常大,因为其本身发生的概率才0.05%。
为了弥补这个情况,则引入查准率和召回率的概念。
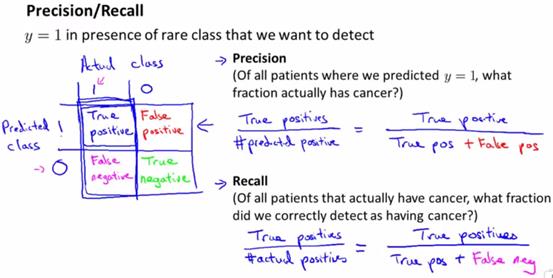
2、正例与反例
为了明确查准率和召回率,需要先说正例和反例的概念,一共有四个名词:真正例(true positive,简称TP)、真反例(true negative,TN)、假正例(false positive)、假反例(false negative)。
真正例TP,表示的是实际上是1,而且预测结果也为1。
真反例TN,表示的是实际上是0,而且预测结果也为0。
假正例FP,表示的是实际上是0,而预测结果是1。
假反例FN,表示的是实际上是1,而预测结果是0。
可以理解为,带“真”字的,表示预测结果是对的,即预测结果就是实际结果;带“假”的是预测结果错误的,即真正的结果和预测结果相反。
2、查准率
查准率,表示的是真正例占所有预测结果是正例的比例,即查准率=TP/(TP+FP),其衡量的是算法的正确性。
3、召回率
召回率,表示的是真正例占所有实际结果是正例的比例,即召回率=TP/(TP+FN),其衡量的是算法找出正确结果的能力。其中FN是假反例,也即实际上是正例。
4、关系
查准率和召回率关系如下图所示:

当一个算法的查准率很高,通常召回率就较低;反之亦然。考虑到logistic回归算法中,目前采用的是h(x)>=0.5时,认为y=1。
如果将值调整为h(x)>=0.9时,y=1。即系统非常“保守”,只有在h(x)非常接近1的时候才会认为y=1,当h(x)=0.899时,虽然其和1也很接近,而且非常大的概率结果也是1,但是模型评估其还是0。此时,系统的查准率(衡量结果正确度)非常高,但是其召回率会非常低(找出正确结果的能力)。
同理,如果调整成h(x)>=0.1时,y=1。这时候的系统非常的“大胆”,只要有一丝的可能,其都认为结果是1,虽然0.1离1还差了10倍。此时查准率会非常低,但是召回率会非常高(基本把所有可能都囊括了,肯定找出正确结果的能力很高,但是这个系统是没用的系统)。
当若干算法,在同一个样本下,有不同的查准率和召回率时,通常有一个标准来确定哪个算法最优:F1=2PR/(P+R)。F1越大的表示算法越优秀。
——written by linhxx
更多最新文章,欢迎关注微信公众号“决胜机器学习”,或扫描右边二维码。
以上是关于ng机器学习视频笔记 ——机器学习系统调试(cv查准率与召回率等)的主要内容,如果未能解决你的问题,请参考以下文章