ng机器学习视频笔记(十五) ——大数据机器学习(随机梯度下降与map reduce)
Posted lin_h
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ng机器学习视频笔记(十五) ——大数据机器学习(随机梯度下降与map reduce)相关的知识,希望对你有一定的参考价值。
ng机器学习视频笔记(十五)
——大数据机器学习(随机梯度下降与map reduce)
(转载请附上本文链接——linhxx)
一、概述
1、存在问题
当样本集非常大的时候,例如m=1亿,此时如果使用原来的梯度下降算法(也成为批量梯度下降算法(batch gradient descent),下同),则速度会非常慢,因为其每次遍历整个数据集,才完成1次的梯度下降的优化。即计算机执行1亿次的计算,仅仅完成1次的优化,因此速度非常慢。
2、数据量考虑
在使用全量数据,而不是摘取一部分数据来做机器学习,首先需要考虑的是算法的学习曲线,如果学习曲线中训练代价函数和cv代价函数差距很大,未收敛,则可以考虑加大样本容量的使用。否则应该先考虑优化算法,加大数据量未必一定有用。
下图左边是可以加大数据量解决的问题,右边是加大数据量也无法解决的问题。

3、说明
本文下面用到的方法,都是在当数据量非常大(如1亿以上)的时候,才会考虑的方法,当数据量不大时,使用批量梯度下降最好,用下面的方法反而会有问题。
二、随机梯度下降
为了解决批量梯度下降收敛速度慢的问题,有了随机梯度下降算法(stochastic gradient descent)。
1、公式
随机梯度下降,本质上就是把批量梯度下降中,不是把整个数据集都计算完取平均值后,再调整对应的θ,而是对于每个样本,计算完该样本后,就直接更新θ。
如下图所示:
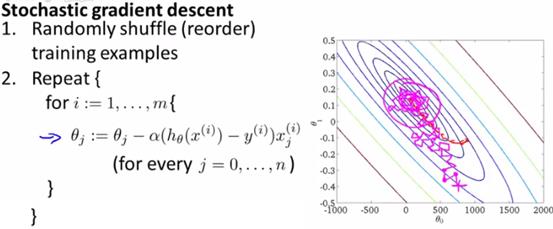
这里的重复次数,实际上数据量很大的时候,1次遍历整个数据集即可。如果想要多次优化,理论上1~10次即可,不需要太多次。
另外,随机梯度下降算法,使用之前,要打散整个数据集,这样效果更好。
2、原理
对于每个样本,计算出来的θ,实际上是一个小范围内的最优梯度。所以用这个来更新,不会直接逼近最优值,而是逼近区域的最优值,因此可能会非常的波动,蜿蜒曲折的靠近最优值,就像上图的粉色的线那样。如上图粉色的线。
而批量梯度下降,由于每次都是用整个样本最优值的均值,因此确保了样本能够直接朝着全局最优值的范围优化。如上图红色的线。
三、随机梯度下降的优化
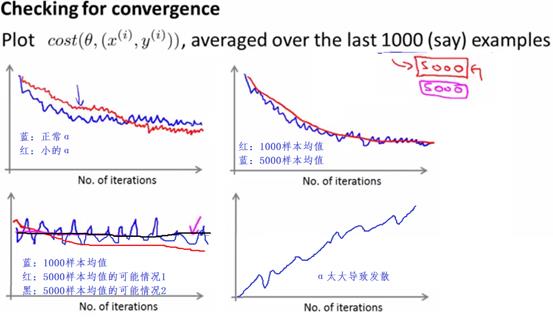
随机梯度下降,也需要考虑到α,以及考虑算法是否正确执行。随机梯度算法正确的衡量,通常是每1000次优化,取一次误差的均值,进而画出均值-优化次数图,通过图像是否往0方向收敛,来判断算法是否正确。
之前学过,α越小,其相当于往梯度迈进的步子越小,即优化的更精确,但是收敛速度会比较慢,如下面的左上方的图。
由于随机梯度,每次的优化是局部的优化,因而会有抖动,如果把1000换成5000,图像会更平缓,但是这样算法的改变在图上表现的也不那么明显,因为是5000次的均值。如下面右上方的图。
如果发现图像一直上下波动,没有收敛也没有发散,可能是因为均值的基数太小,此时用5000来做均值,有可能会解决此问题。但是也有可能本身算法问题,或者数据等的问题导致的,这样的就无法解决。如下图左下角的图。
另外,如果α取的太大,图像发散,需要减小α,如下图右下角的图。
动态α:
为了保证抖动更少,还可以通过动态取α的值来做到,令α=C/(D+迭代次数),C、D是两个常数。这样随着迭代的深入,α越来越小,则会越来越精确,而尽量避免越过最低值导致波动的现象。
但是,这样带来的问题,就是原来需要一个α作为参数,现在需要C、D两个参数,这样需要设置的参数更多,算法更加复杂。
四、微型批量梯度下降
有一种梯度下降,介于批量梯度下降和随机梯度下降之间,叫做微型梯度下降(Mini batch gradient descent),其做法是,既不像批量梯度下降那样要遍历整个样本才做一次优化更新,也不像随机梯度下降那样每个样本更新一次,而是设定一个参数b,每遍历b个样本做一次优化更新。b通常取2~100。如下图所示:

五、在线学习
1、过程
当无法一次性获取整个数据集,或者需要不断的优化时,则要用到在线学习(online learning)技术。
在线学习,实际上就是拥有无限输入的随机梯度下降。随机梯度下降是遍历整个数据集,对于每个样本进行一次计算和优化;而在线学习没有指定的样本集,是每次来一个新的样本,就做一次优化。
这里输入的是样本的特征,并将是否被用户选择作为输出,可以用logistic回归的方式来进行学习。
如下:

2、主要业务场景
例如新闻网站,需要根据用户的点击,在用户下次登陆时展示不同的信息。这样就可以将展示出来的新闻作为样本,用户点击的话则判断为1,不点击则判断为0。对于被判断为1的新闻,拥有这种类型的特征的新闻,下次展示的概率都会更大。
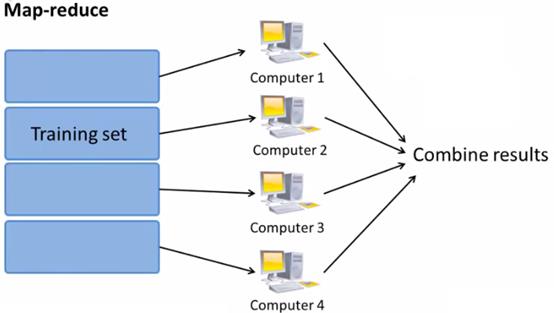
六、Map-reduce
当数据量非常大,而且有多台电脑,或者计算机集群时,可以并行的来解决问题,运用map-reduce的思想来处理。
map-reduce,实际上是将一个庞大的数据集,根据当前情况进行分片,把不同的片分给不同的处理器处理,每片再把处理结果都传给同一个中央处理器,进行汇总计算。
例如现在有400个数据(这里为了举例说明,实际上400个数据用不到map-reduce,而4亿的数据则可以考虑用map-reduce),4台计算机,要进行线性回归的机器学习,采用批量梯度下降的方式进行优化。
批量梯度下降每次优化,需要累加所有的样本的求偏导的计算结果,则可以把400个数据分成4个100个的数据集,同时给4台机器处理。每台机器处理完,都将结果传给一个中央处理器。中央处理器在把这些结果求和,求均值,乘以α,做减法,触发下一次的优化。
这样,当不考虑网络延迟等问题时,可以达到原来速度的4倍。
如下图所示:

机器如下图所示:
另外,现在的很多计算机是多核的,如果一个计算机有四核,则也可以进行map-reduce,而且这样还省去了网络延时,效果更好。
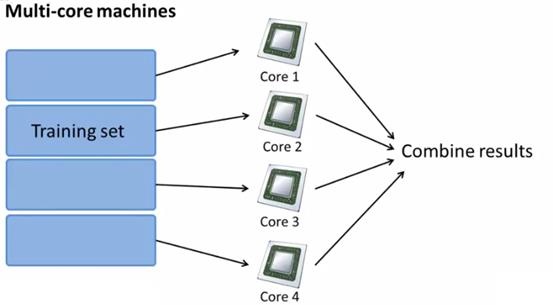
另外,有的函数库,会自动的去调用计算机的多核来处理,则就不需要考虑map-reduce了。
七、总结
这一章主要提到大数据情况下的处理方式,数据量非常大时,很多平时很好用的算法会慢慢无法适应,这也是上面提到的一些改版的梯度下降的起源。对于数据量小时,如果使用随机梯度下降或者微型梯度下降,反而无法很好的收敛,因为数据量不足会导致训练次数不够。
另外,对于map-reduce,实际上是用到并行的思想来处理问题,要使用这个,首先要确定数据量足够大,有必要使用;此外,也要保证对应的机器学习算法,里面的优化过程(或部分子过程)可以拆成几个部分给各个机器同时处理,而且是耗时的部分进行拆解处理,这样才能最大的提示计算机是效用。
——written by linhxx
更多最新文章,欢迎关注微信公众号“决胜机器学习”,或扫描右边二维码。
以上是关于ng机器学习视频笔记(十五) ——大数据机器学习(随机梯度下降与map reduce)的主要内容,如果未能解决你的问题,请参考以下文章