目的: 有效的存储,高效的访问。
优良的设计特点
1.减少数据冗余
2.避免数据异常
3.节约存储空间
4.高效的数据访问
数据库设计步骤
1.需求分析
2.逻辑设计ER建模
3.物理设计(mysql、Oracle、Sql server)
4.维护优化(新需求建表、索引优化、大表拆分)
需求分析
搞清楚实体与实体之间的关系?
实体包含哪些属性?
实体的唯一标识是什么?
对于日志类的实体,可以进行分库分表设计,定期归档。
电商实例,用户模块、商品模块、订单模块、购物车模块、供应商模块。
用户模块,包含属性:用户名、密码、电话、邮箱、身份证号、地址、姓名、昵称...
可选唯一标识,用户名、身份证、电话、邮箱。
存储特点,随系统上线逐渐增加,需要永久存储。
商品模块,包含属性:商品编码、商品名称、商品描述、商品分类、供应商名称、价格
可选唯一标识(商品编码)、(商品名称、供应商名称)
存储特点:对于下线商品可以归档存储(不要删除)。
订单模块,包括属性:订单号、用户姓名、电话、收货地址、商品编号、商品名称、数量、价格、订单状态、支付状态、订单类型...
可用唯一标识,订单号。
存储特点:永久存储(分库分表)
购物车模块,包括属性:用户名、商品编号、商品名称、商品价格,商品分类,加入时间,商品数量...
可选唯一标识:(用户名、商品编号、加入时间)、(购物车编号)
存储特点:不用永久存储(设置归档,清理规则)
供应商模块,包括属性:供应商编号、供应商名称、联系人、电话、营业执照号、地址、法人...
可选唯一标识:供应商编号、营业执照号
存储特点:永久存储。
逻辑设计
矩形表示实体集
菱形表示联系集
椭圆表示实体属性
线段连接属性与实体,实体与联系集
遵循一二三范式就基本够用了,遵循它可以有效的避免数据库操作异常及数据冗余。
第一范式(1NF),字段不可拆分。表中的每个字段都是最小的数据单元
下面的设计就不符合第一范式。
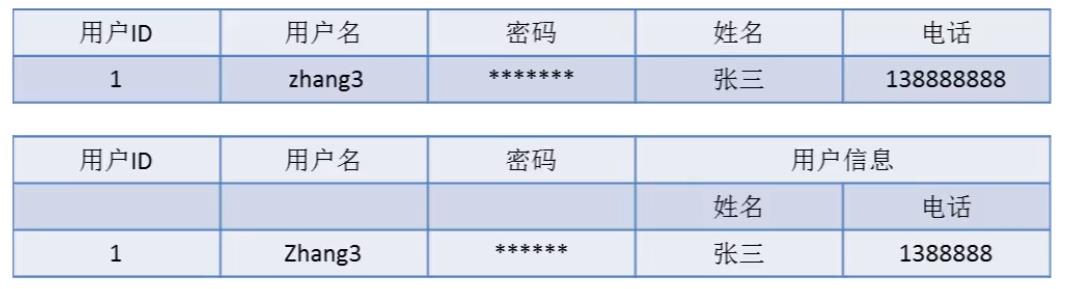
第二范式(2NF)要求实体的属性完全依赖于主关键字。所谓完全依赖是指不能存在仅依赖主关键字一部分的属性,如果存在,那么这个属性和主关键字的这一部分应该分离出来形成一个新的实体,新实体与原实体之间是一对多的关系。在 1NF 的基础上,表中所有的非码属性必须【完全依赖】于候选码,不可以部分依赖
存在部分依赖主属性。
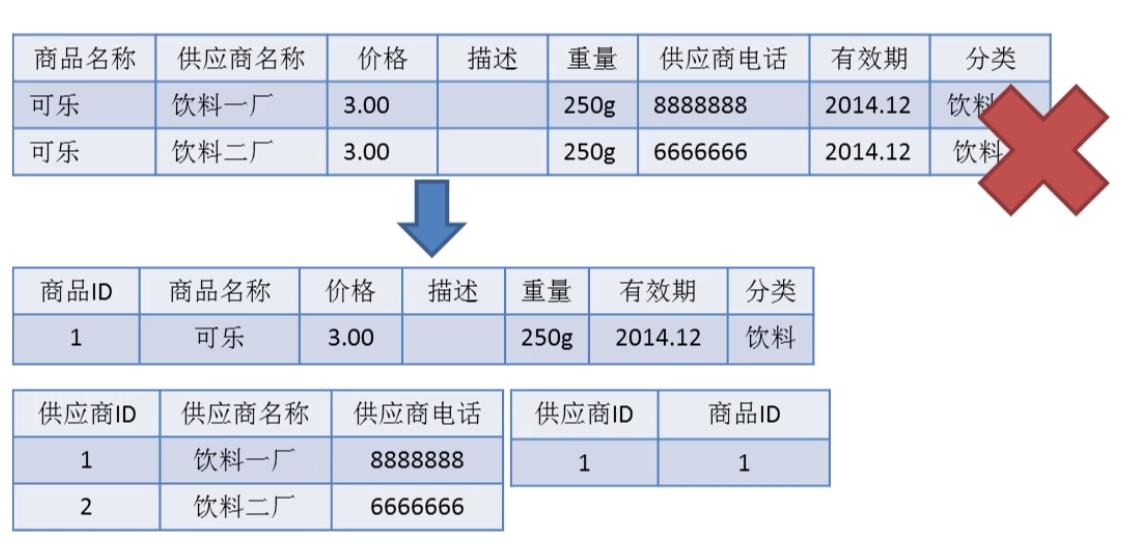
商品价格与重量,有效期,分类,依赖于商品。
供应商电话,依赖于供应商名称。
拆分成3个表。商品表,供应商表,供应商与商品关联表。
或者拆分成2个表。商品表,供应商表。商品表关联供应商表。
第三范式(3NF),就是不能重复存储相同的信息。在 2NF 的基础上,非主属性之间没有相互依赖(消除传递依赖)

分类描述与分类存在传递依赖。
拆分成商品表,分类表。通过分类id来关联分类。

BC范式(BCNF)复合关键字之间也不能存在函数依赖关系

拆成供应商,供应商联系人
商品ID、供应商联系人,商品数量
物理设计
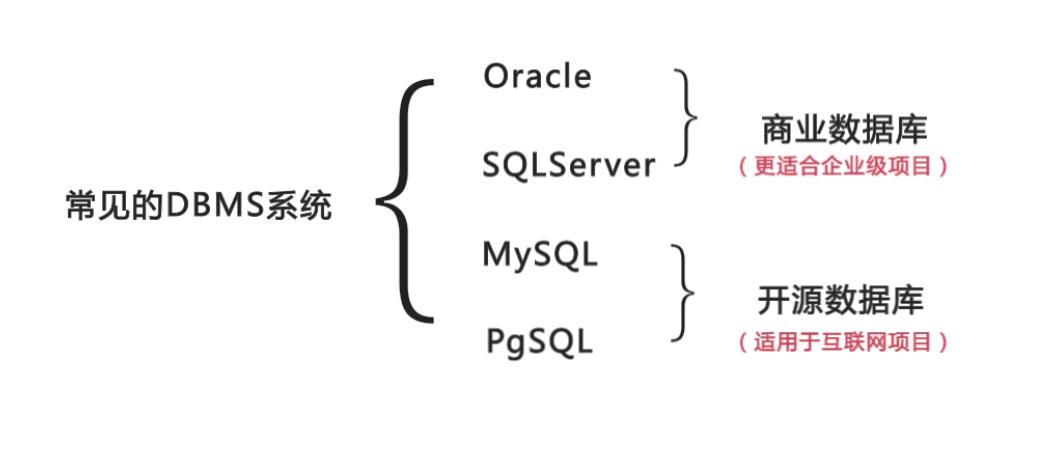
选择合适的数据库管理系统,Mysql 、Oracle、Sql Server。
建立数据库、表以及命名规范。
根据所选的DBMS,选择合适的字段类型。
反范式化设计,冗余,以空间换时间。
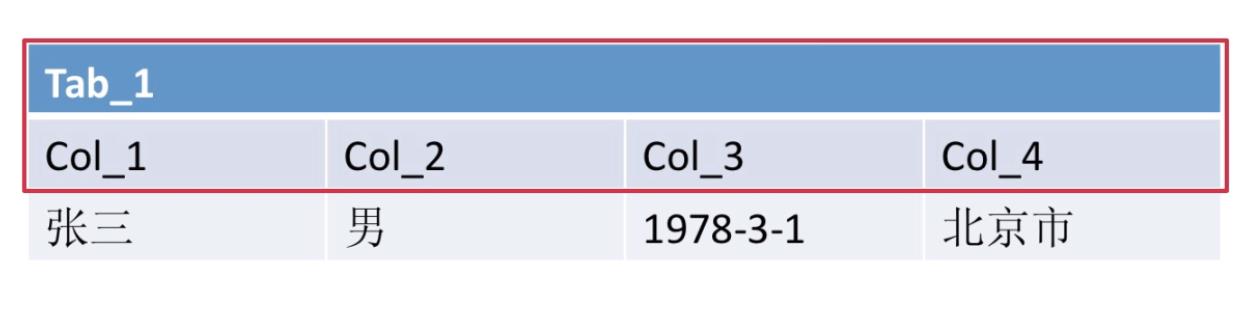
尊徐可读原则、表意原则、长名原则。下面的表命名就不可取。
对于日期,优先,int,datetime,char ,varchar。
避免使用外键约束,影响高并发。(降低导入效率,增加维护成本)。
避免使用触发器(可能出现数据异常,业务逻辑变复杂)。
反范式,以空间换时间,适用于高并发项目。

减少表关联数量
增加读取效率
反范式化要适度适量
维护优化
维护数据字典(特别是状态字段),增加备注
维护索引(增加索引,优化索引)
表结构优化
水平拆分,垂直拆分表
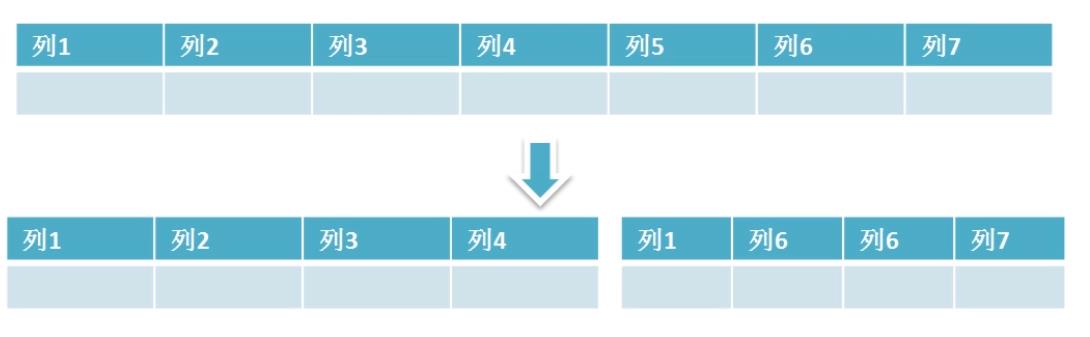
经常查的放在一个表中。不常用,大字段的放到另一张表。(垂直拆分),解决表宽度大问题。
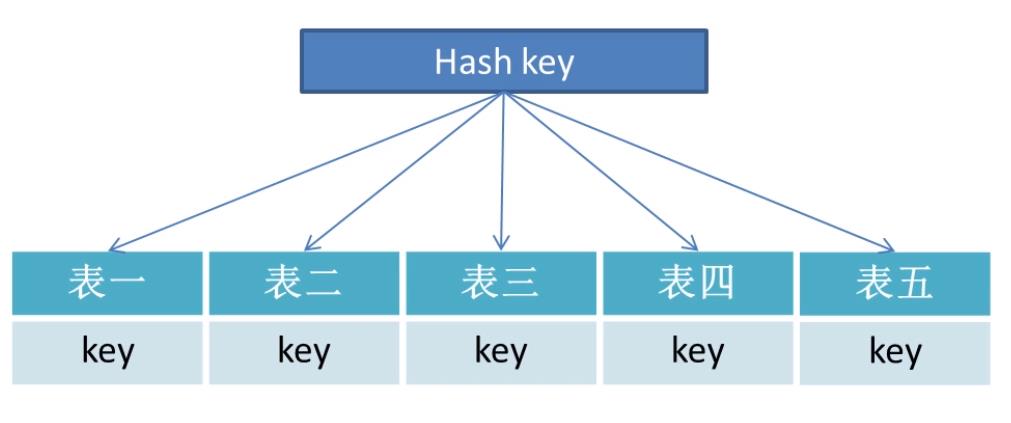
通过hash来实现水平拆分。解决数据量大问题。
具体的设计,还要根据业务进行分析。尽量设计出合适的表。好的底层,才能盖出牢固的大楼。后期维护的时候,也尽量遵守设计步骤和原则。让系统有条不紊的提升。