慕课网实战Spark Streaming实时流处理项目实战笔记八之铭文升级版
Posted 集技术与颜值于一身
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了慕课网实战Spark Streaming实时流处理项目实战笔记八之铭文升级版相关的知识,希望对你有一定的参考价值。
铭文一级:
Spark Streaming is an extension of the core Spark API that enables scalable,
high-throughput,
fault-tolerant
stream processing of live data streams.
Spark Streaming个人的定义:
将不同的数据源的数据经过Spark Streaming处理之后将结果输出到外部文件系统
特点
低延时
能从错误中高效的恢复:fault-tolerant
能够运行在成百上千的节点
能够将批处理、机器学习、图计算等子框架和Spark Streaming综合起来使用
Spark Streaming是否需要独立安装?
One stack to rule them all : 一栈式
GitHub
https://github.com/apache/spark
spark-submit的使用
使用spark-submit来提交我们的spark应用程序运行的脚本(生产)
./spark-submit --master local[2] \\
--class org.apache.spark.examples.streaming.NetworkWordCount \\
--name NetworkWordCount \\
/home/hadoop/app/spark-2.2.0-bin-2.6.0-cdh5.7.0/examples/jars/spark-examples_2.11-2.2.0.jar hadoop000 9999
如何使用spark-shell来提交(测试)
./spark-shell --master local[2]
import org.apache.spark.streaming.{Seconds, StreamingContext}
val ssc = new StreamingContext(sc, Seconds(1))
val lines = ssc.socketTextStream("hadoop000", 9999)
val words = lines.flatMap(_.split(" "))
val wordCounts = words.map(x => (x, 1)).reduceByKey(_ + _)
wordCounts.print()
ssc.start()
ssc.awaitTermination()
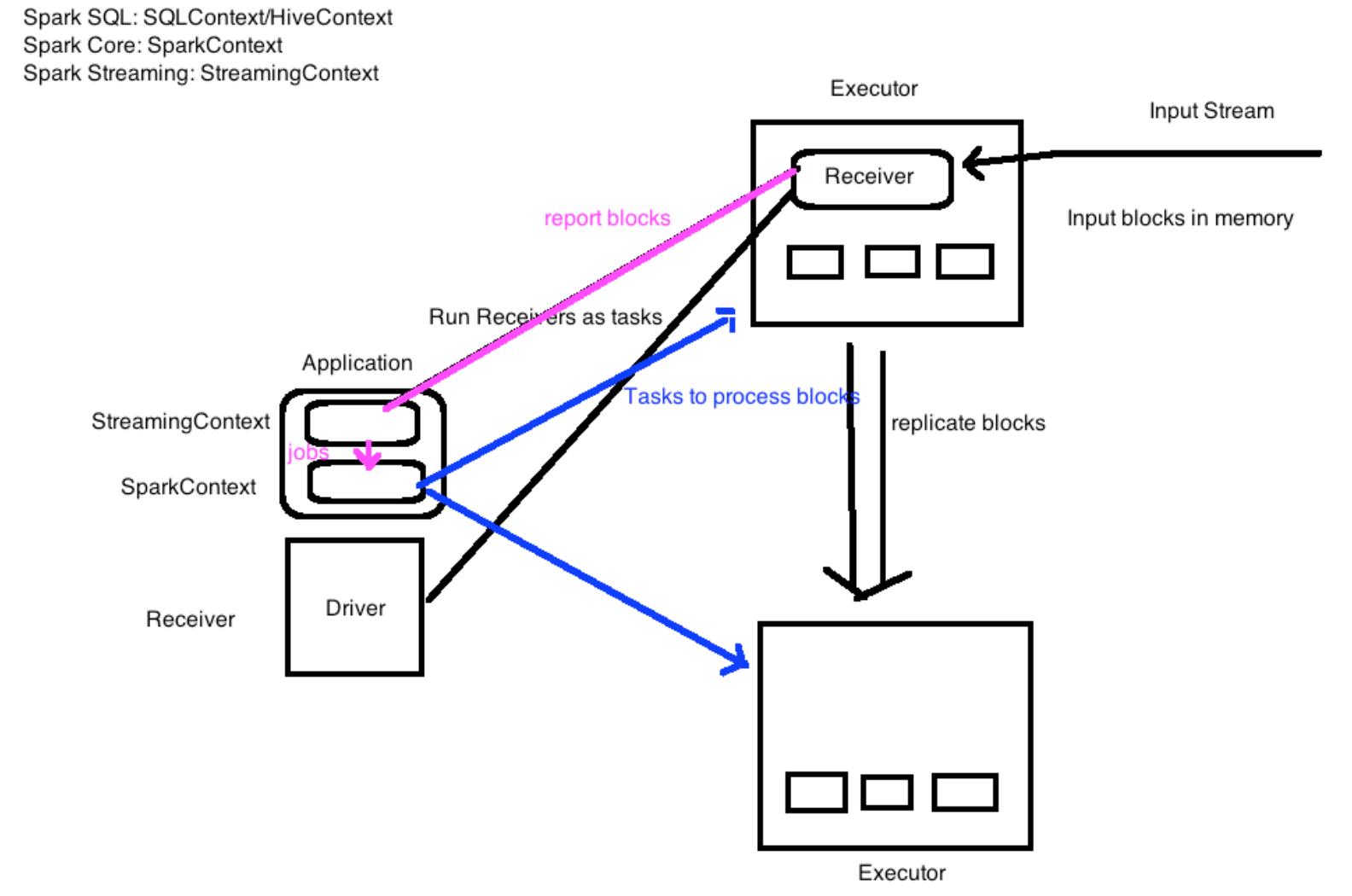
工作原理:粗粒度
Spark Streaming接收到实时数据流,把数据按照指定的时间段切成一片片小的数据块,
然后把小的数据块传给Spark Engine处理。
铭文二级:
Spark Streaming功能特点:可扩展、高吞吐、容错性
与Spark生态的其他环境的整合:
1、file与RDD 2、与MLib 3、RDD->SQL
有些时候要了解一下发展史,面试可能会问
比如说DataSet、DataFrame是哪个版本提出来的
词频统计实例=>
从github上(https://github.com/apache/spark/blob/master/examples/)可以看源码:
注意两个参数:hostname、port
用spark-submit方式运行(主要用于生产)
进入Spark Streaming的bin目录下:
[运行rm *.cmd删除window上才能运行的脚本使更简洁咯]
步骤一=>
启动终端二运行:nc -lk 9999
步骤二=>
终端一运行指令为:./spark-submit --master local[2] \\
--class org.apache.spark.examples.streaming.NetworkWordCount \\
在examples/jars里面的jar包 hadoop000 9999
复制指令去bin目录下执行
步骤三=>
去终端二输入测试数据:
a a a c c d e
在终端一可以观察到统计结果
用spark-shell方式运行(主要用于测试)
1、执行 ./spark-shell --master local[2]
2、修改官网的代码
A.删去SparkConf申明语句,因为spark-shell运行时已自动创建
B.StreamingContext的第一个参数sparkConf改为sc
C.修改socketTextStream第一第二个参数为实际情况,删除第三参数
D.添加类的导入语句
import org.apache.spark.streaming.{Seconds, StreamingContext}
3、拷贝本段代码,粘贴去终端运行,方法同spark-submit
粗粒度:按时间段切成小段
细粒度:
以上是关于慕课网实战Spark Streaming实时流处理项目实战笔记八之铭文升级版的主要内容,如果未能解决你的问题,请参考以下文章
慕课网实战Spark Streaming实时流处理项目实战笔记十之铭文升级版
慕课网实战Spark Streaming实时流处理项目实战笔记三之铭文升级版
慕课网实战Spark Streaming实时流处理项目实战笔记七之铭文升级版
慕课网实战Spark Streaming实时流处理项目实战笔记五之铭文升级版