慕课网实战Spark Streaming实时流处理项目实战笔记三之铭文升级版
Posted 集技术与颜值于一身
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了慕课网实战Spark Streaming实时流处理项目实战笔记三之铭文升级版相关的知识,希望对你有一定的参考价值。
铭文一级:
Flume概述
Flume is a distributed, reliable,
and available service for efficiently collecting(收集),
aggregating(聚合), and moving(移动) large amounts of log data
webserver(源端) ===> flume ===> hdfs(目的地)
设计目标:
可靠性
扩展性
管理性
业界同类产品的对比
(***)Flume: Cloudera/Apache Java
Scribe: Facebook C/C++ 不再维护
Chukwa: Yahoo/Apache Java 不再维护
Kafka:
Fluentd: Ruby
(***)Logstash: ELK(ElasticSearch,Kibana)
Flume发展史
Cloudera 0.9.2 Flume-OG
flume-728 Flume-NG ==> Apache
2012.7 1.0
2015.5 1.6 (*** + )
~ 1.7
Flume架构及核心组件
1) Source 收集
2) Channel 聚集
3) Sink 输出
Flume安装前置条件
Java Runtime Environment - Java 1.7 or later
Memory - Sufficient memory for configurations used by sources, channels or sinks
Disk Space - Sufficient disk space for configurations used by channels or sinks
Directory Permissions - Read/Write permissions for directories used by agent
安装jdk
下载
解压到~/app
将java配置系统环境变量中: ~/.bash_profile
export JAVA_HOME=/home/hadoop/app/jdk1.8.0_144
export PATH=$JAVA_HOME/bin:$PATH
source下让其配置生效
检测: java -version
安装Flume
下载
解压到~/app
将java配置系统环境变量中: ~/.bash_profile
export FLUME_HOME=/home/hadoop/app/apache-flume-1.6.0-cdh5.7.0-bin
export PATH=$FLUME_HOME/bin:$PATH
source下让其配置生效
flume-env.sh的配置:export JAVA_HOME=/home/hadoop/app/jdk1.8.0_144
检测: flume-ng version
example.conf: A single-node Flume configuration
使用Flume的关键就是写配置文件
A) 配置Source
B) 配置Channel
C) 配置Sink
D) 把以上三个组件串起来
a1: agent名称
r1: source的名称
k1: sink的名称
c1: channel的名称
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = netcat
a1.sources.r1.bind = hadoop000
a1.sources.r1.port = 44444
# Describe the sink
a1.sinks.k1.type = logger
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
启动agent
flume-ng agent \\
--name a1 \\
--conf $FLUME_HOME/conf \\
--conf-file $FLUME_HOME/conf/example.conf \\
-Dflume.root.logger=INFO,console
使用telnet进行测试: telnet hadoop000 44444
Event: { headers:{} body: 68 65 6C 6C 6F 0D hello. }
Event是FLume数据传输的基本单元
Event = 可选的header + byte array
铭文二级:
Flume设计目标:可靠性,扩展性,管理性
官网:flume.apache.org -> Documentation(左栏目) -> Flume User Guide
左栏为目录,较常用的有:
Flume Sources:avro、exec、kafka、netcat
Flume Channels:memory、file、kafka
Flume Sinks:HDFS、Hive、logger、avro、ElasticSearch、Hbase、kafka
注意:每个source、channel、sink都有custom自定义类型
Setting multi-agent flow

Consolidation
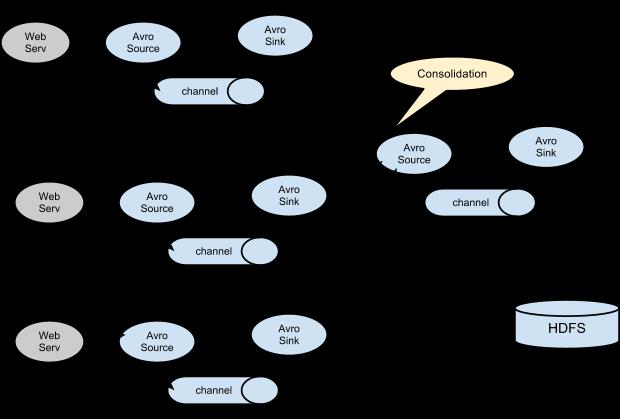
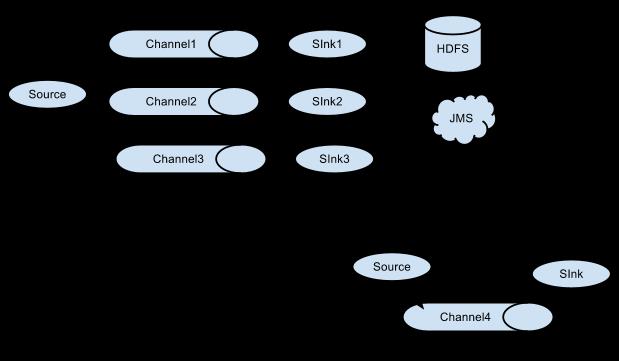
Multiplexing the flow
实战准备=>
1.前置要求为以上铭文一4点,Flume的下载可以在cdh5里wget下来
wget http://archive.cloudera.com/cdh5/cdh/5/flume-ng-1.6.0-cdh5.5.0.tar.gz
2.安装jdk,指令:tar -zxvf * -C ~/app/ ,最后勿忘:source ~/.bash_profile
配置cp flume-env.sh.template flume-env.sh ,export JAVA_HOME=/home/hadoop/app/jdk1.8.0_144
3.检测是否安装成功:flume-ng version
实战步骤=>
实战需求:从指定的网络端口采集数据输出到控制台
配置文件(创建example.conf于conf文件夹中,主要是看官网!):
1、a1.后面的source、channel、sink、均有"s"
2、后面连接是,sources后面的channel有"s",sink后面的chanel无"s"
启动agent=>
flume-ng agent \\
--name a1 \\
--conf $FLUME_HOME/conf \\
--conf-file $FLUME_HOME/conf/example.conf \\
-Dflume.root.logger=INFO,console
启动另一终端ssh上,使用telnet进行监听: telnet hadoop000 44444
原本的终端输入内容,可以在此终端接受到
以上是关于慕课网实战Spark Streaming实时流处理项目实战笔记三之铭文升级版的主要内容,如果未能解决你的问题,请参考以下文章