如果你现在接到一个任务,获取某某行业下的分类。
作为一个非该领域专家,没有深厚的运营经验功底,要提供一套摆的上台面且让人信服的行业分类,恐怕不那么简单。
找不到专家没有关系,我们可以爬虫。把那些专家的心血抽丝剥茧爬出来再统计即可。
确定好思路,我和即将要说的爬虫框架Gecco打了一天的交道。
Gecco简介
Gecco是一款用java语言开发的轻量化的易用的网络爬虫。Gecco整合了jsoup、httpclient、fastjson、spring、htmlunit、redission等优秀框架,让您只需要配置一些jquery风格的选择器就能很快的写出一个爬虫。Gecco框架有优秀的可扩展性,框架基于开闭原则进行设计,对修改关闭、对扩展开放。同时Gecco基于十分开放的MIT开源协议,无论你是使用者还是希望共同完善Gecco的开发者(摘自GitHub上的介绍)
主要特征
-
简单易用,使用jquery风格的选择器抽取元素
-
支持爬取规则的动态配置和加载
-
支持页面中的异步ajax请求
-
支持页面中的javascript变量抽取
-
利用Redis实现分布式抓取,参考gecco-redis
-
支持结合Spring开发业务逻辑,参考gecco-spring
-
支持htmlunit扩展,参考gecco-htmlunit
-
支持插件扩展机制
-
支持下载时UserAgent随机选取
-
支持下载代理服务器随机选取
GitHub:https://github.com/xtuhcy/gecco
中文参考手册:http://www.geccocrawler.com/
同时GitHub上也提供了使用Gecco的实例,用于抓取京东商城分类以及分类下的商品信息。看到例子的第一眼就发现Gecco特别适合抓取这种分类以及分类下详情列表的数据。
下面通过实例,边实战边说明Gecco的用法。
Gecco爬取分类数据
爬取思路
首先明确爬取的种子网站:http://news.iresearch.cn/
爬取区域如下图所示

爬取思路:先选取最上面的“互联网+”分类,然后爬取下面的各个子分类(移动互联网+电子商务+互联网+网络销售+网络游戏),再爬取各个子分类下的所有文章,最后提取所有文章的文本信息(提取文本后需要使用IKanalyzer或ansj分词,然后进行词频统计,本篇不做详述)。
编写爬虫启动入口
我新建的是maven项目,所以要使用Gecco,第一步是添加maven依赖
<dependency>
<groupId>com.geccocrawler</groupId>
<artifactId>gecco</artifactId>
<version>1.0.8</version>
</dependency>
然后编写一个main函数作为爬虫的入口
public class Main {
public static void main(String[] rags) {
System.out.println("=======start========");
HttpGetRequest startUrl = new HttpGetRequest("http://news.iresearch.cn/");
startUrl.setCharset("GBK");
GeccoEngine.create()
//Gecco搜索的包路径
.classpath("com.crawler.gecco")
//开始抓取的页面地址
.start(startUrl)
//开启几个爬虫线程
.thread(1)
//单个爬虫每次抓取完一个请求后的间隔时间
.interval(2000)
.run();
}
}
-
HttpGetRequest用于包裹种子网站,同时可以设置编码,这里设置的是“GBK”(一开始当时没有设置该参数时,爬出的文本都是乱码的)
-
classpath是一个扫描路径,类似于Spring中的component-scan,用于扫描注解的类。这里主要用于扫描注解“@Gecco”所在的类。
解析获取所有子分类
package com.crawler.gecco;
import com.geccocrawler.gecco.annotation.Gecco;
import com.geccocrawler.gecco.annotation.HtmlField;
import com.geccocrawler.gecco.annotation.Request;
import com.geccocrawler.gecco.request.HttpRequest;
import com.geccocrawler.gecco.spider.HtmlBean;
import java.util.List;
/**
* Created by jackie on 18/1/15.
*/
@Gecco(matchUrl="http://news.iresearch.cn/", pipelines={"consolePipeline", "allSortPipeline"})
public class AllSort implements HtmlBean {
private static final long serialVersionUID = 665662335318691818L;
@Request
private HttpRequest request;
// 移动互联网
@HtmlField(cssPath="#tab-list > div:nth-child(1)")
private List<Category> mobileInternet;
// 电子商务
@HtmlField(cssPath="#tab-list > div:nth-child(2)")
private List<Category> electric;
// 互联网
@HtmlField(cssPath="#tab-list > div:nth-child(3)")
private List<Category> internet;
// 网络营销
@HtmlField(cssPath="#tab-list > div:nth-child(4)")
private List<Category> netMarket;
// 网络游戏
@HtmlField(cssPath="#tab-list > div:nth-child(5)")
private List<Category> netGame;
public List<Category> getMobileInternet() {
return mobileInternet;
}
public void setMobileInternet(List<Category> mobileInternet) {
this.mobileInternet = mobileInternet;
}
public List<Category> getElectric() {
return electric;
}
public void setElectric(List<Category> electric) {
this.electric = electric;
}
public List<Category> getInternet() {
return internet;
}
public void setInternet(List<Category> internet) {
this.internet = internet;
}
public List<Category> getNetMarket() {
return netMarket;
}
public void setNetMarket(List<Category> netMarket) {
this.netMarket = netMarket;
}
public List<Category> getNetGame() {
return netGame;
}
public void setNetGame(List<Category> netGame) {
this.netGame = netGame;
}
public HttpRequest getRequest() {
return request;
}
public void setRequest(HttpRequest request) {
this.request = request;
}
}
-
虽然代码很长,但是除去set和get方法,剩下的就是获取子分类标签的代码
-
注解@Gecco告知该爬虫匹配的url格式(matchUrl)和内容抽取后的bean处理类(pipelines处理类采用管道过滤器模式,可以定义多个处理类),这里matchUrl就是http://news.iresearch.cn/,意为从这个网址对应的页面中解析
-
这里pipelines参数可以添加多个管道处理类,意为下一步该执行哪些管道类,需要说明的是consolePipeline,是专门将过程信息输出到控制台的管道类,后面会说明
-
注解@HtmlField表示抽取html中的元素,cssPath采用类似jquery的css selector选取元素
举例说明,现在需要解析“移动互联网”分类下所有的列表并将列表结果包装为一个list,供后面进一步解析列表的具体内容
// 移动互联网
@HtmlField(cssPath="#tab-list > div:nth-child(1)")
private List<Category> mobileInternet;
这里cssPath是用于指定需要解析的目标元素的css位置。
如何获取这个区块的位置,先看页面
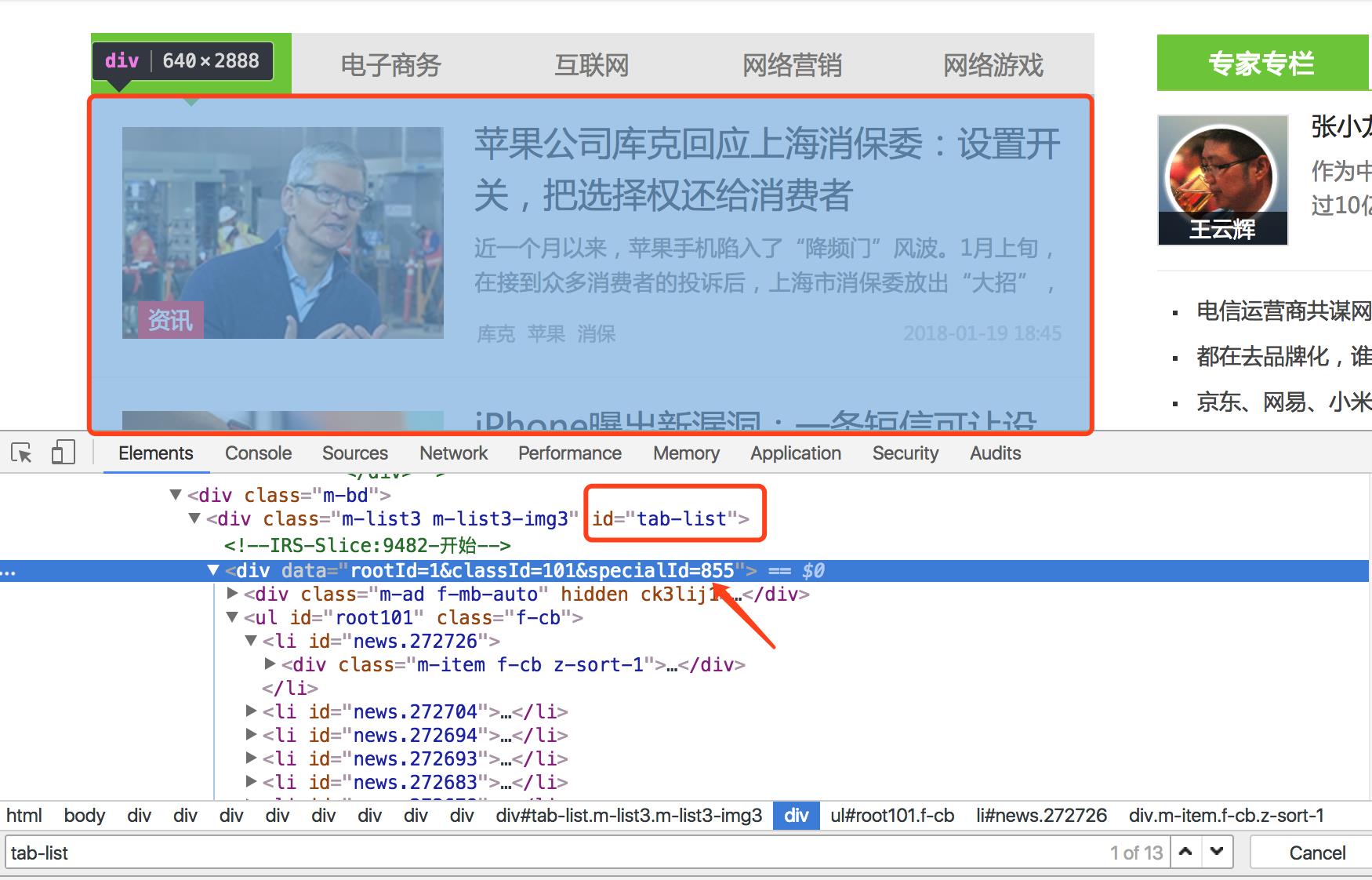
我们要获取的是“移动互联网”下的所有列表,并将其包装为一个list集合。打开Chrome开发者工具,可以看到该列表模块被div标签包裹,只要定位到该模块的位置即可。
如果通过人肉的方式获取cssPath确实有点伤眼,所以我们可以使用Chrome自带的工具获取css路径,在上图箭头所在位置右键,按照如下图所示操作,粘贴即可得到cssPath
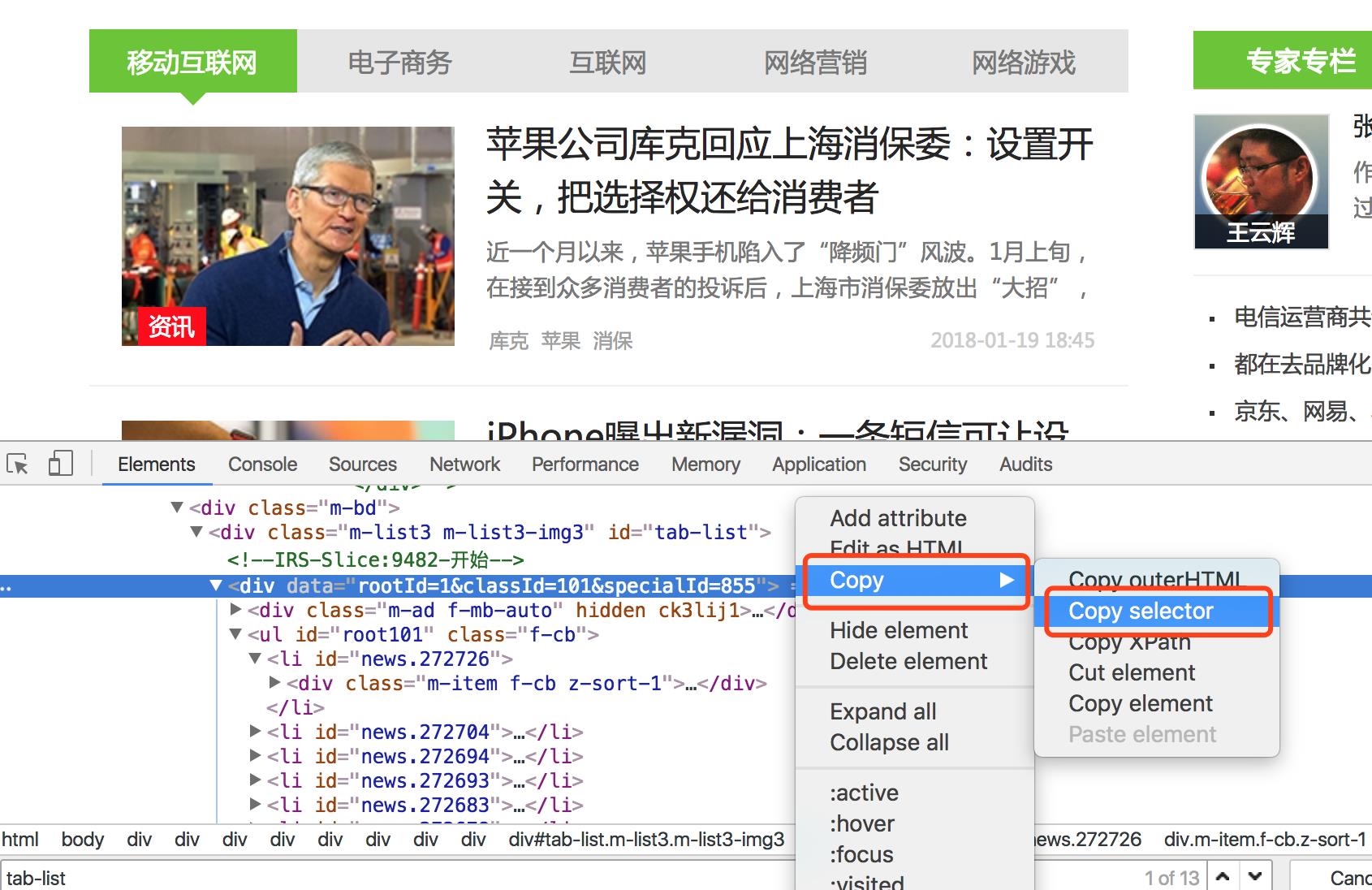
依次操作,可以获取其他四个分类的分类列表。
获取分类列表对应的url
通过上面的解析,我们得到了各个分类下的列表模块。通过Chrome开发者工具,我们可以发现每个列表项包含的信息很少,我们不应该直接抓取这些仅有的文本做分析,这样会漏掉很多文本信息。
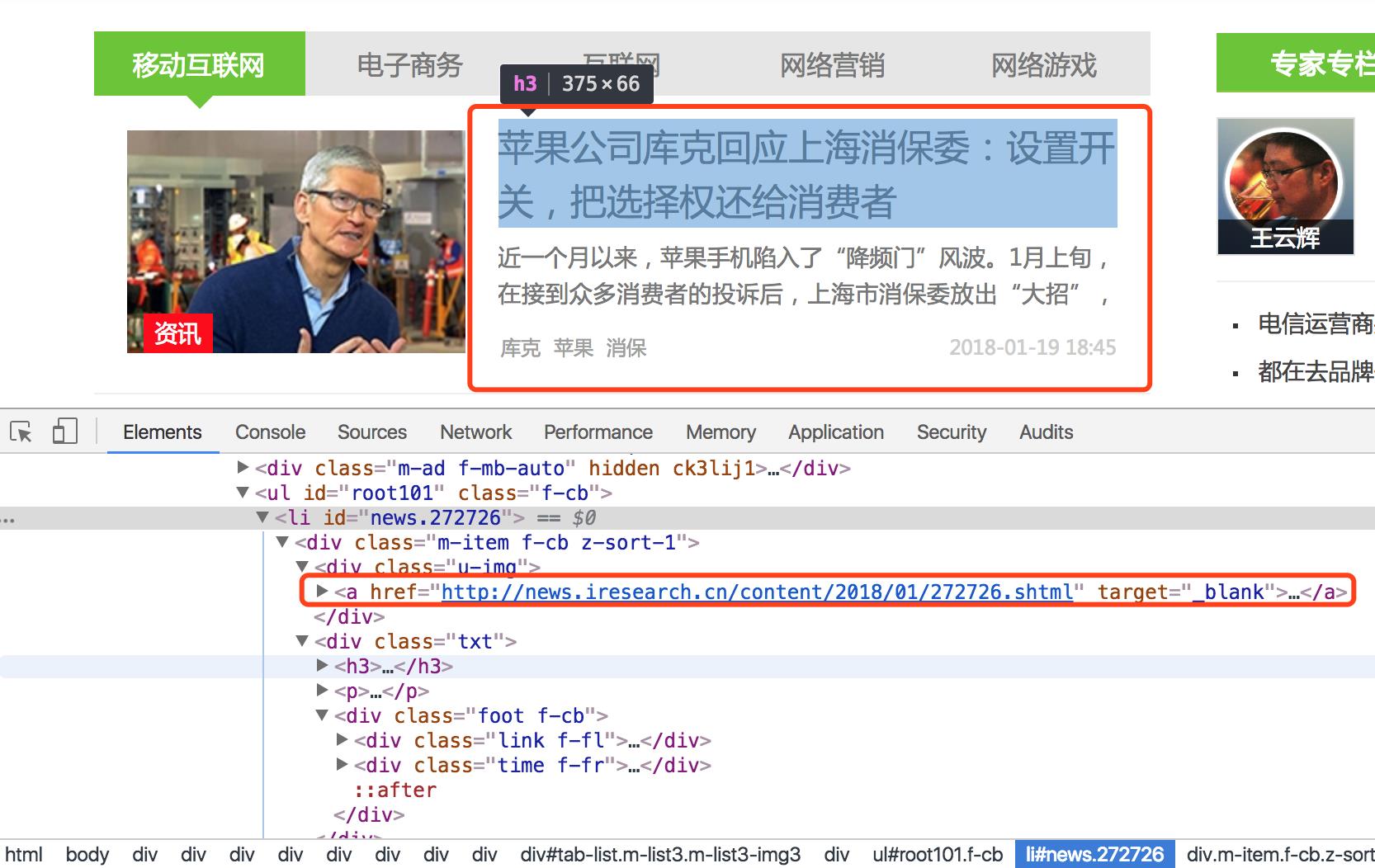
所以,我们应该先定位解析出所有的href超链接,即每个列表项对应的文章详情地址,然后解析文章详情的所有文本信息。
所以这里的Category类如下
package com.crawler.gecco;
import com.geccocrawler.gecco.annotation.HtmlField;
import com.geccocrawler.gecco.annotation.Text;
import com.geccocrawler.gecco.spider.HrefBean;
import com.geccocrawler.gecco.spider.HtmlBean;
import java.util.List;
/**
* Created by jackie on 18/1/15.
*/
public class Category implements HtmlBean {
private static final long serialVersionUID = 3018760488621382659L;
@Text
@HtmlField(cssPath="dt a")
private String parentName;
@HtmlField(cssPath="ul li")
private List<HrefBean> categorys;
public String getParentName() {
return parentName;
}
public void setParentName(String parentName) {
this.parentName = parentName;
}
public List<HrefBean> getCategorys() {
return categorys;
}
public void setCategorys(List<HrefBean> categorys) {
this.categorys = categorys;
}
}
categorys即用于手机某个分类下所有列表对应的网址
下面实现AllSortPipeline类,用于收集所有分类下的url
package com.crawler.gecco;
import com.geccocrawler.gecco.annotation.PipelineName;
import com.geccocrawler.gecco.pipeline.Pipeline;
import com.geccocrawler.gecco.request.HttpRequest;
import com.geccocrawler.gecco.scheduler.SchedulerContext;
import com.geccocrawler.gecco.spider.HrefBean;
import java.util.ArrayList;
import java.util.List;
/**
* Created by jackie on 18/1/15.
*/
@PipelineName("allSortPipeline")
public class AllSortPipeline implements Pipeline<AllSort> {
@Override
public void process(AllSort allSort) {
System.out.println("-=======-");
List<Category> categorys = new ArrayList<Category>();
categorys.addAll(allSort.getInternet());
categorys.addAll(allSort.getElectric());
categorys.addAll(allSort.getMobileInternet());
categorys.addAll(allSort.getNetGame());
categorys.addAll(allSort.getNetMarket());
for(Category category : categorys) {
List<HrefBean> hrefs = category.getCategorys();
for(HrefBean href : hrefs) {
System.out.println("title: " + href.getTitle() + " url: " + href.getUrl());
String url = href.getUrl();
HttpRequest currRequest = allSort.getRequest();
SchedulerContext.into(currRequest.subRequest(url));
}
}
}
}
-
categorys集合用于添加所有分类下的列表
-
通过遍历的方式获取具体的url和每个url对应的title
-
将url信息存储到SchedulerContext上下文中,用于后面爬虫
到此为止,我们获取了所有的分类列表对应的url信息,并将url存储到上下文中,用于后续爬虫匹配。下面编写用于解析详情也的处理类。
解析文章详情
新建注解类ProductDetail,用于匹配上边得到的url
package com.crawler.gecco;
import com.geccocrawler.gecco.annotation.*;
import com.geccocrawler.gecco.spider.HtmlBean;
/**
* Created by jackie on 18/1/15.
*/
@Gecco(matchUrl="http://news.iresearch.cn/content/{yeary}/{month}/{code}.shtml", pipelines={"consolePipeline", "productDetailPipeline"})
public class ProductDetail implements HtmlBean {
private static final long serialVersionUID = -377053120283382723L;
/**
* 文本内容
*/
// @Text
@HtmlField(cssPath="body > div.g-content > div.g-bd.f-mt-auto > div > div.g-mn > div > div.g-article > div.m-article")
private String content;
@RequestParameter
private String code;
@RequestParameter
private String year;
@RequestParameter
private String month;
/**
* 标题
*/
@Text
@HtmlField(cssPath="body > div.g-content > div.g-main.f-mt-auto > div > div > div.title > h1")
private String title;
public String getContent() {
return content;
}
public void setContent(String content) {
this.content = content;
}
public String getCode() {
return code;
}
public void setCode(String code) {
this.code = code;
}
public String getTitle() {
return title;
}
public void setTitle(String title) {
this.title = title;
}
public String getYear() {
return year;
}
public void setYear(String year) {
this.year = year;
}
public String getMonth() {
return month;
}
public void setMonth(String month) {
this.month = month;
}
}
-
matchUrl是每个文章的url格式,year、month和code是注入的参数
-
同理,我们定位到title所在的cssPath和 content所在的cssPath,用于解析得到具体的title和content值
下面实现ProductDetailPipeline类,用于解析每篇文章的文本信息,并通过正则抽取所有的中文文本存储到result.txt中
package com.crawler.gecco;
import com.geccocrawler.gecco.annotation.*;
import com.geccocrawler.gecco.pipeline.Pipeline;
import java.io.File;
import java.io.FileWriter;
import java.io.IOException;
/**
* Created by jackie on 18/1/15.
*/
@PipelineName("productDetailPipeline")
public class ProductDetailPipeline implements Pipeline<ProductDetail> {
@Override
public void process(ProductDetail productDetail) {
System.out.println("~~~~~~~~~productDetailPipeline~~~~~~~~~~~");
File resultFile = new File("result.txt");
if (!resultFile.exists()) {
try {
resultFile.createNewFile();
} catch (IOException e) {
System.out.println("create result file failed: " + e);
}
}
FileWriter fileWriter = null;
try {
fileWriter = new FileWriter("result.txt", true);
} catch (IOException e) {
System.out.println("IOException");
}
try {
fileWriter.write(RegrexUtil.match(productDetail.getContent()));
fileWriter.flush();
} catch (IOException e) {
System.out.println("fileWriter.write failed: " + e);
} finally {
try {
fileWriter.close();
} catch (IOException e) {
System.out.println("fileWriter.close failed");
}
}
}
}
至此,我们通过Gecco获取到了互联网行业各分类下的所有文章,并提取到所有的文本信息。
结果如下
项目地址:https://github.com/DMinerJackie/tour-project
如有问题,可以下方留言
如果您觉得阅读本文对您有帮助,请点一下“推荐”按钮,您的“推荐”将是我最大的写作动力!如果您想持续关注我的文章,请扫描二维码,关注JackieZheng的微信公众号,我会将我的文章推送给您,并和您一起分享我日常阅读过的优质文章。
