教您使用java爬虫gecco抓取JD全部商品信息
Posted 魔流剑●风之痕
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了教您使用java爬虫gecco抓取JD全部商品信息相关的知识,希望对你有一定的参考价值。
gecco爬虫
如果对gecco还没有了解可以参看一下gecco的github首页。gecco爬虫十分的简单易用,JD全部商品信息的抓取9个类就能搞定。
JD网站的分析
要抓取JD网站的全部商品信息,我们要先分析一下网站,京东网站可以大体分为三级,首页上通过分类跳转到商品列表页,商品列表页对每个商品有详情页。那么我们通过找到所有分类就能逐个分类抓取商品信息。
入口地址
http://www.jd.com/allSort.aspx,这个地址是JD全部商品的分类列表,我们以该页面作为开始页面,抓取JD的全部商品信息
新建开始页面的htmlBean类AllSort
1 @Gecco(matchUrl="http://www.jd.com/allSort.aspx", pipelines={"consolePipeline", "allSortPipeline"}) 2 public class AllSort implements HtmlBean{ 3 4 private static final long serialVersionUID = 665662335318691818L; 5 6 @Request 7 private HttpRequest request; 8 9 //手机 10 @HtmlField(cssPath=".category-items > div:nth-child(1) > div:nth-child(2) > div.mc > div.items > dl") 11 private List<Category> mobile; 12 13 //家用电器 14 @HtmlField(cssPath=".category-items > div:nth-child(1) > div:nth-child(3) > div.mc > div.items > dl") 15 private List<Category> domestic; 16 17 public List<Category> getMobile(){ 18 return mobile; 19 } 20 21 public void setMobile(List<Category> mobile){ 22 this.mobile = mobile; 23 } 24 25 public List<Category> getDomestic(){ 26 return domestic; 27 } 28 29 public void setDomestic(List<Category> domestic){ 30 this.domestic = domestic; 31 } 32 33 public HttpRequest getRequest(){ 34 return request; 35 } 36 37 public void setRequest(HttpRequest request){ 38 this.request = request; 39 } 40 }
可以看到,这里以抓取手机和家用电器两个大类的商品信息为例,可以看到每个大类都包含若干个子分类,用List<Category>表示。gecco支持Bean的嵌套,可以很好的表达html页面结构。Category表示子分类信息内容,HrefBean是共用的链接Bean。
public class Category implements HtmlBean{ private static final long serialVersionUID = 3018760488621382659L; @Text @HtmlField(cssPath="dt a") private String parentName; @HtmlField(cssPath="dd a") private List<HrefBean> categorys; public String getParentName(){ return parentName; } public void setParentName(String parentName){ this.parentName = parentName; } public List<HrefBean> getCategorys(){ return categorys; } public void setCategorys(List<HrefBean> categorys){ this.categorys = categorys; } }
获取页面元素cssPath的小技巧
上面两个类难点就在cssPath的获取上,这里介绍一些cssPath获取的小技巧。用Chrome浏览器打开需要抓取的网页,按F12进入发者模式。选择你要获取的元素,如图:
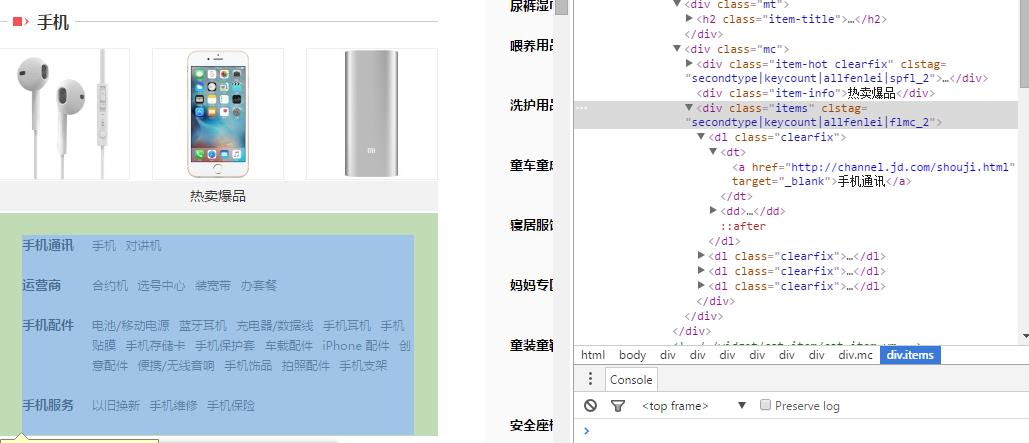
在浏览器右侧选中该元素,鼠标右键选择Copy--Copy selector,即可获得该元素的cssPath
body > div:nth-child(5) > div.main-classify > div.list > div.category-items.clearfix > div:nth-child(1) > div:nth-child(2) > div.mc > div.items
如果你对jquery的selector有了解,另外我们只希望获得dl元素,因此即可简化为:
.category-items > div:nth-child(1) > div:nth-child(2) > div.mc > div.items > dl
编写AllSort的业务处理类
完成对AllSort的注入后,我们需要对AllSort进行业务处理,这里我们不做分类信息持久化等处理,只对分类链接进行提取,进一步抓取商品列表信息。看代码:
1 @PipelineName("allSortPipeline") 2 public classAllSortPipelineimplementsPipeline<AllSort> { 3 4 @Override 5 public void process(AllSort allSort) { 6 List<Category> categorys = allSort.getMobile(); 7 for(Category category : categorys) { 8 List<HrefBean> hrefs = category.getCategorys(); 9 for(HrefBean href : hrefs) { 10 String url = href.getUrl()+"&delivery=1&page=1&JL=4_10_0&go=0"; 11 HttpRequest currRequest = allSort.getRequest(); 12 SchedulerContext.into(currRequest.subRequest(url)); 13 } 14 } 15 } 16 17 }
@PipelinName定义该pipeline的名称,在AllSort的@Gecco注解里进行关联,这样,gecco在抓取完并注入Bean后就会逐个调用@Gecco定义的pipeline了。为每个子链接增加"&delivery=1&page=1&JL=4_10_0&go=0"的目的是只抓取京东自营并且有货的商品。SchedulerContext.into()方法是将待抓取的链接放入队列中等待进一步抓取。
以上是关于教您使用java爬虫gecco抓取JD全部商品信息的主要内容,如果未能解决你的问题,请参考以下文章