HBase详细概述
Posted 小丸子的西瓜梦
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了HBase详细概述相关的知识,希望对你有一定的参考价值。
本文首先简单介绍了HBase,然后重点讲述了HBase的高并发和实时处理数据 、HBase数据模型、HBase物理存储、HBase系统架构,HBase调优、HBase Shell访问等。
不过在此之前,你可以先了解 Hadoop生态系统 ,若想运行HBase,则需要先搭建好Hadoop集群环境,可以参考此文搭建5个节点的hadoop集群环境(CDH5) 。
好了,让我们来学习HBase吧!
HBase简介
HBase的发展史
2006年底由PowerSet 的Chad Walters和Jim Kellerman 发起,2008年成为Apache Hadoop的一个子项目。现已作为产品在多家企业被使用,如:
- WorldLingo
- Streamy.com
- OpenPlaces
- Yahoo!
- Adobe
- 淘宝
Hbase是什么
Hbaseshiyizho构建在一个HDFS之上的分布式、面向存储列的存储系统。在需要实时读写、随机访问超大规模访问数据采集的时候,可以使用HBase。
尽管现在已经有很多数据存储和访问的策略和实现方法。但是事实上大多数解决方案。特别是一些关系类型的,在构建时并没有考虑超大规模和分布式的特点。许多商家通过复制和分区的方法来扩充数据库使其突破单个节点的界限,但这些功能通常都是事后增加的,安装和维护都和复杂。同时,也会影响RDBMS的特定功能,例如联接、复杂的查询、触发器、视图和外键约束这些操作在大型的RDBMS上的代价相当高,甚至根本无法实现。
HBase从另一个角度处理伸缩性的问题。它通过线性方式从下到上增加节点来进行扩展。HBase不是关系型数据库,也不支持SQL,但是他有自己的特长,这是RDBMS不能处理的,HBase巧妙的将稀疏的表放在商用的服务器的集群上。
HBase 是Google Bigtable 的开源实现,与Google Bigtable利用GFS作为文件存储系统类似,HBase利用Hadoop HDFS 作为文件存储系统,Google 运行MapReduce 来处理Bigtable中的海量数据,HBase 同样利用Hadoop MapReduce来处理HBase的海量数据,Google Bigtable 利用Chubby作为协同服务。HBase利用Zookepper作为对应。
HBase的特点
- 大:一个表可以有上亿行,上百万列。
- 面向列:面向列表(簇)的存储和权限控制,列(簇)独立检索。
- 稀疏:对于为空(NULL)的列,并不占用存储空间,因此,表可以设计的非常稀疏。
- 无模式:每一行都有一个可以排序的主键和任意多的列,列可以根据需要动态增加,同一张表中不同的行可以有截然不同的列。
- 数据多版本:每个单元中的数据可以有多个版本,默认情况下,版本号自动分配,版本号就是单元格插入时的时间戳。
- 数据类型单一:HBase中的数据都是字符串,没有类型。
HBase的高并发和实时处理数据
hadoop是一个高容错,高延时的文件分布式系统和高并发的批处理系统,不适用实时计算。HBase是可以提供实时计算的分布式数据库。数据被保存到HDFS分布式文件系统上。由HDFS保证期高容错性。但是在生产环境中。HBase是如何基于hadoop提供实时性呢? HBase上的数据是以StoreFile(HFile)二进制流的形式存储在HDFS上block块儿中;但是HDFS并不知道hbase存入的是什么,它只把存储文件是为二进制文件,也就是说。hbase的存储数据对于HDFS文件系统是透明的。hbase的存储数据对于HDFS文件系统是透明的。
HBase HRegion servers集群中的所有的region的数据在服务器启动时都是被打开的,并且在内冲初始化一些memstore,相应的这就在一定的程度上加快的系统的响应。而Hadoop中的block中的数据文件默认是关闭的,只有在需要的时候打开。处理完数据后就关闭。这在一定的程度上就增加了响应时间。

从根本上来说。HBase能提供实时计算的服务的主要原因是由架构和底层数据结构决定的。即由LSM-Tree + HTable(region分区) + Cache决定——客户端可以直接定位到要查数据所在的HRegion server服务器,然后直接在服务器的一个region上查找要匹配的数据,并且这些数据部分是经过cache缓存的。具体查询流程如下图所示: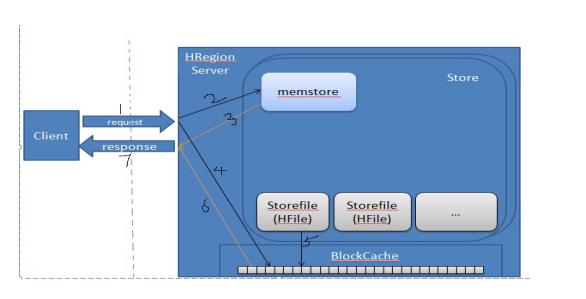
具体数据访问流程如下:
1.Client会通过内部缓存的相关的-ROOT-中的信息和.META.中的信息直接连接与请求数据匹配的HRegion server;
2.然后直接定位到该服务器上与客户请求对应的Region,客户请求首先会查询该Region在内存中的缓存——Memstore(Memstore是一个按key排序的树形结构的缓冲区);
3.如果在Memstore中查到结果则直接将结果返回给Client;
4.在Memstore中没有查到匹配的数据,接下来会读已持久化的StoreFile文件中的数据。前面的章节已经讲过,StoreFile也是按 key排序的树形结构的文件——并且是特别为范围查询或block查询优化过的,;另外HBase读取磁盘文件是按其基本I/O单元(即 HBase Block)读数据的。
具体就是过程就是:
如果在BlockCache中能查到要造的数据则这届返回结果,否则就读去相应的StoreFile文件中读取一block的数据,如果还没有读到要查的 数据,就将该数据block放到HRegion Server的blockcache中,然后接着读下一block块儿的数据,一直到这样循环的block数据直到找到要请求的数据并返回结果;如果将该 Region中的数据都没有查到要找的数据,最后接直接返回null,表示没有找的匹配的数据。当然blockcache会在其大小大于一的阀值(heapsize * hfile.block.cache.size * 0.85)后启动基于LRU算法的淘汰机制,将最老最不常用的block删除。
HBase数据模型
HBase 以表的形式存储数据。表由行和列组成。列划分为若干个列族(row family),如下图所示。

HBase的逻辑数据模型:
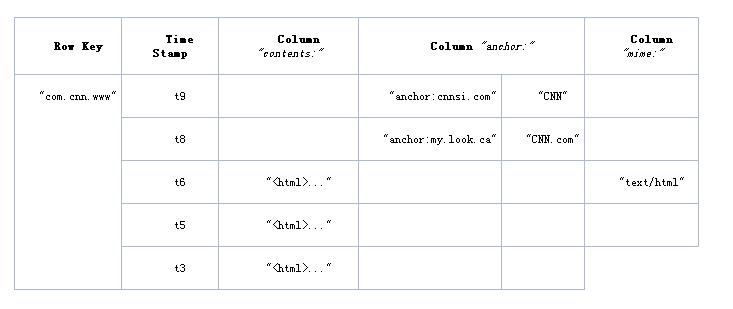
HBase的物理数据模型(实际存储的数据模型):

逻辑数据模型中空白cell在物理上是不存储的,因为根本没有必要存储,因此若一个请求为要获取t8时间的contents:html,他的结果就是空。相似的,若请求为获取t9时间的anchor:my.look.ca,结果也是空。但是,如果不指明时间,将会返回最新时间的行,每个最新的都会返回
Row Key
与 NoSQL 数据库一样,Row Key 是用来检索记录的主键。访问 HBase table 中的行,只有三种方式:
1)通过单个 Row Key 访问。
2)通过 Row Key 的 range 全表扫描。
3)Row Key 可以使任意字符串(最大长度是64KB,实际应用中长度一般为 10 ~ 100bytes),在HBase 内部,Row Key 保存为字节数组。
在存储时,数据按照* Row Key 的字典序(byte order)排序存储*。设计 Key 时,要充分排序存储这个特性,将经常一起读取的行存储到一起(位置相关性)。
注意 字典序对 int 排序的结果是 1,10,100,11,12,13,14,15,16,17,18,19,20,21,…, 9,91,92,93,94,95,96,97,98,99。要保存整形的自然序,Row Key 必须用 0 进行左填充。
行的一次读写是原子操作(不论一次读写多少列)。这个设计决策能够使用户很容易理解程序在对同一个行进行并发更新操作时的行为。
列族
HBase 表中的每个列都归属于某个列族。列族是表的 Schema 的一部分(而列不是),必须在使用表之前定义。列名都以列族作为前缀,例如 courses:history、courses:math 都属于 courses 这个列族。
访问控制、磁盘和内存的使用统计都是在列族层面进行的。在实际应用中,列族上的控制权限能帮助我们管理不同类型的应用, 例如,允许一些应用可以添加新的基本数据、一些应用可以读取基本数据并创建继承的列族、
一些应用则只允许浏览数据(甚至可能因为隐私的原因不能浏览所有数据)。
时间戳
HBase 中通过 Row 和 Columns 确定的一个存储单元称为 Cell。每个 Cell 都保存着同一份数据的多个版本。 版本通过时间戳来索引,时间戳的类型是 64 位整型。时间戳可以由HBase(在数据写入时自动)赋值,
此时时间戳是精确到毫秒的当前系统时间。时间戳也 可以由客户显示赋值。如果应用程序要避免数据版本冲突,就必须自己生成具有唯一性的时间戳。每个 Cell 中,不同版本的数据按照时间倒序排序,即最新的数据排在最前面。
为了避免数据存在过多版本造成的管理(包括存储和索引)负担,HBase 提供了两种数据版本回收方式。 一是保存数据的最后 n 个版本,二是保存最近一段时间内的版本(比如最近七天)。用户可以针对每个列族进行设置。
Cell
Cell 是由 {row key,column(=< family> + < label>),version} 唯一确定的单元。Cell 中的数据是没有类型的,全部是字节码形式存储。
HBase物理存储
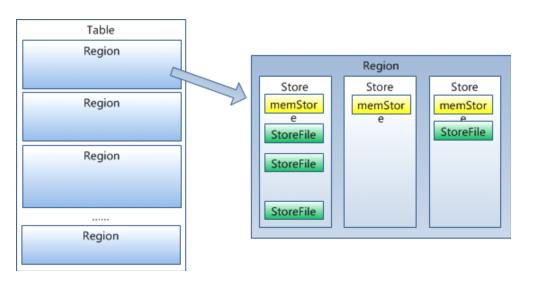
Table 在行的方向上分割为多个HRegion,每个HRegion分散在不同的RegionServer中。

每个HRegion由多个Store构成,每个Store由一个memStore和0或多个StoreFile组成,每个Store保存一个Columns Family
以上是关于HBase详细概述的主要内容,如果未能解决你的问题,请参考以下文章