grep命令及正则表达式
Posted 追阳
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了grep命令及正则表达式相关的知识,希望对你有一定的参考价值。
grep:global search regular expression(RE) and print out the line
文本搜索工具,根据用户指定的文本模式对目标文件进行逐行搜索,显示能够被模式所匹配到的行。
基本语法
grep [option] \'PATTERN\' file, ...
正则表达式:是一类字符所书写出的模式(pattern)
元字符:不表示字符本身的意义,用于额外功能性的描述
此处表达式分为基本正则表达式和扩展正则表达式。
基本正则表达式的元字符:
字符匹配:.
. : 任意单个字符
grep --color=auto Boot /etc/rc.d/rc.sysinit grep --color=auto \'B..t\' /etc/rc.d/rc.sysinit grep --color=auto \'r..t\' /etc/passwd
[]: 指定范围内的任意单个字符
[^]: 指定范围外的任意单个字符
[0-9], [[:digit:]] 数字
[a-z], [[:lower:]] 小写字母
[A-Z], [[:upper:]] 大写字母
[[:alpha:]] 字母
[[:alnum:]] 字母和数字
[[:space:]] 空格
[[:punct:]] 标点符号
alias cgrep=\'grep --color=auto\' cgrep \'[Rr]..[Tt]\' /etc/passwd cgrep \'[Rr].*[Tt]\' /etc/passwd cgrep \'[Rr][^[:punct:]]*[Tt]\' /etc/passwd
次数匹配:用来指定匹配其前面的字符次数
* : 任意次
例子:x*y, xxy, xy, y
.* : 匹配任意长度的任意次
\\?: 0次或1次
x\\?y, xy, y, xxy
贪婪模式:尽可能长的去匹配字符
\\{m\\}: 匹配其前面字符m次
\\{m,n\\}: 匹配其前面字符至少m次,最多n次
\\{m,\\}: 匹配其前面字符至少m次,最多不限
\\{0,n\\}: 匹配其前面字符最多n次
位置锚定:用于指定字符出现的位置
^: 锚定行首
^char
cgrep \'^[Rr][^[:punct:]]*[Tt]\' /etc/passwd
$:锚定行尾
char$
cgrep \'bash$\' /etc/passwd
^$: 空白行
\\<char, \\bchar :锚定词首
char\\>, char\\b :锚定词尾
分组:
\\(\\)
\\(ab\\)*xy :把ab当成一个部分
引用:
\\1: 后向引用,引用前面的第一个左括号以及与之对应的右括号中的模式所匹配到的内容
\\2 --前面匹配到的内容,后面还要继续再出现一次
...
\\(a.b\\)xy\\1:
a6bxy 不能匹配
a6bxya7b 能匹配到
下面演示一下分组的具体用法:
cat grep.txt He like his lover. She love her liker. He love his lover. she like her liker.
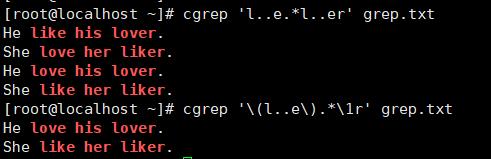
grep 常用的选项:
-v: 反向,显示不能被模式所匹配到的行
-o: 仅显示被模式匹配到的字串,而非整行
-i: 不区分字符大小写,ignore-case
-E: 支持扩展的正则表达式
-A # : 显示匹配到的行及下#行
-B # : 显示匹配到的行及上#行
-C # : 显示匹配到的行及上下各#行
1、显示/proc/meminfo文件中以大小写s开头的行
grep "^[sS]" /proc/meminfo grep -i "^s" /proc/meminfo
2、取出默认shell为非bash用户
grep \'[^bash]$\' /etc/passwd | cut -d: -f1 grep -v \'^bash$\' /etc/passwd | cut -d: -f1
3、取出默认shell为bash的且其ID号最大的用户
grep "bash$" /etc/passwd | sort -n -t: -k3 | tail -1 | cut -d: -f1
4、显示/etc/rc.d/rc.local文件中,以#开头,后面跟至少一个空白字符,而后又有至少一个非空白字符的行
grep "^#[[:space:]]\\{1,\\}[^[:space:]]\\{1,\\}" /etc/rc.d/rc.local
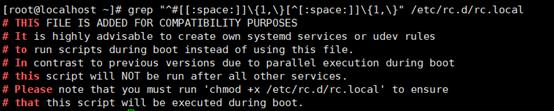
5、显示/boot/grub2/grub.cfg中以至少一个空白字符开头的行
grep "^[[:space:]]\\{1,\\}" /boot/grub2/grub.cfg 这个包含空白行 grep "^[[:space:]]\\{1,\\}[^[:space:]]\\{1,\\}" /boot/grub2/grub.cfg 把空白行除外
6、找出/etc/passwd文件中一位数或两位数
grep --color=auto "\\b[[:digit:]]\\{1,2\\}\\b" /etc/passwd grep --color=auto "\\<[0-9]\\{1,2\\}\\>" /etc/passwd
7、找出ifconfig命令结果中的1到255之间的整数
ifconfig | egrep --color=auto "\\<([1-9]|[1-9][0-9]|1[0-9]{2}|2[0-4][0-9]|25[0-5])\\>"

8、查看当前系统上root用户的所有信息
grep "^root\\>" /etc/passwd
9、找出当前系统上其用户名和默认shell相同的用户
grep --color=auto "^\\([[:alnum:]]\\{1,\\}\\)\\>.*\\1$" /etc/passwd
10、找出netstat -tan命令执行的结果中以"LISTEN"或"ESTABLISHED"结尾的行
netstat -tan | egrep --color=auto "(LISTEN|ESTABLISHED)[[:space:]]*"
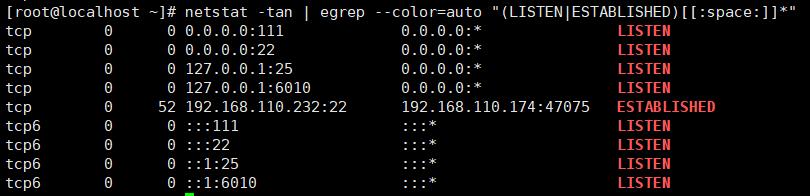
11、取出当前系统上所有用户的shell,要求:每种shell只显示一次,且按升序显示
cut -d: -f7 /etc/passwd | sort -u
12、写一个模式,能匹配真正意义上的IP地址:(1.0.0.1--223.255.255.254)
ifconfig | egrep --color=auto "\\<([1-9]|[1-9][0-9]|1[0-9]{2}|2[0-1][0-9]|22[0-3])\\.([0-9]|[1-9][0-9]|1[0-9]{2}|2[0-4][0-9]|25[0-5])\\.([0-9]|[1-9][0-9]|1[0-9]{2}|2[0-4][0-9]|25[0-5])\\.([1-9]|[1-9][0-9]|1[0-9]{2}|2[0-4][0-9]|25[0-4])\\>" 或者 ifconfig | egrep --color=auto "\\<([1-9]|[1-9][0-9]|1[0-9]{2}|2[0-1][0-9]|22[0-3])\\.(([0-9]|[1-9][0-9]|1[0-9]{2}|2[0-4][0-9]|25[0-5])\\.){2}([1-9]|[1-9][0-9]|1[0-9]{2}|2[0-4][0-9]|25[0-4])\\>"

cut 行剪切命令
-d 指定分隔符
-f 指定显示第几段
cut -d: -f1 以:为分隔符,显示第一段
sort 排序命令
-n 以数值大小排序
-t: 指定分隔符为:
-k3 指定排序的数值在第3列
-u 去重
sort命令默认是升序
grep家族
grep, egrep, fgrep
egrep: 使用扩展正则表达式来构建模式,相当于 grep -E
对于扩展正则表达式元字符可以查看http://www.cnblogs.com/chengtai/p/6618263.html
fgrep: fast,不解析正则表达式,给什么字符就找什么字符。给的内容一律当字符串查找。
以上是关于grep命令及正则表达式的主要内容,如果未能解决你的问题,请参考以下文章