朴素贝叶斯文本分类简单介绍
Posted hapjin
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了朴素贝叶斯文本分类简单介绍相关的知识,希望对你有一定的参考价值。
本文介绍朴素贝叶斯算法如何对文本进行分类。比如,每个用户的购物评论就是一篇文本,识别出这篇文本属于正向评论还是负面评论 就是分类的过程,而类别就是:{正面评论,负面评论}。正面评论为Positive,用标识符\'+\'表示;负面评论为Negative,用标识符\'-\'表示。
一,分类目标
寻找文本的某些特征,然后根据这些特征将文本归为某个类。
The goal of classification is to take a single observation, extract some useful
features, and thereby classify the observation into one of a set of discrete classes.
使用监督式机器学习方法对文本进行分类:首先假设已经有分好类的N篇文档:(d1,c1)、(d2,c2)、(d3,c3)……(dn,cn)
di表示第i篇文档,ci表示第i个类别。目标是:寻找一个分类器,这个分类器能够:当丢给它一篇新文档d,它就输出d (最有可能)属于哪个类别c
二,分类器的介绍
①Generative classifier
朴素贝叶斯分类器属于Generative classifier。
②Discriminative classifier
逻辑回归属于Discriminative classifier。
Generative classifiers like naive Bayes build a model of each class. Given an observation,they return the class most likely to have generated the observation.
Discriminative classifiers like logistic regression instead learn what features from the input are most useful to discriminate between the different possible classes.
三,词袋模型(Bag Of Words)
前面提到,文本分类需要寻找文本的特征。而词袋模型就是表示文本特征的一种方式。给定一篇文档,它会有很多特征,比如文档中每个单词出现的次数、某些单词出现的位置、单词的长度、单词出现的频率……而词袋模型只考虑一篇文档中单词出现的频率(次数),用每个单词出现的频率作为文档的特征(或者说用单词出现的频率来代表该文档)。词袋模型的示意图如下:
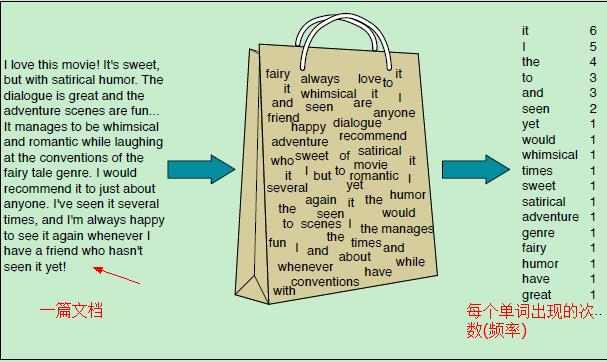
We represent a text document as if it were a bag-of-words,
that is, an unordered set of words with their position ignored, keeping only their frequency in the document.
四,朴素贝叶斯分类器
朴素贝叶斯分类器是一个概率分类器。假设现有的类别C={c1,c2,……cm}。给定一篇文档d,文档d最有可能属于哪个类呢?这个问题用数学公式表示如下:
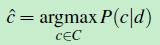 (公式一)
(公式一)
c^ 就是:在所有的类别C={c1,c2,……cm} 中,使得:条件概率P(c|d)取最大值的类别。使用贝叶斯公式,将(公式一)转换成如下形式:
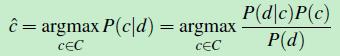 (公式二)
(公式二)
对类别C中的每个类型,计算 [p(d|c)*p(c)]/p(d) 的值,然后选取最大值对应的那个类型ci ,该ci就是最优解c^,因此,可以忽略掉分母 p(d),(公式二)变成如下形式:
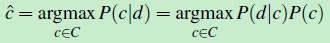 (公式三)
(公式三)
这个公式由两部分组成,前面那部分P(d|c) 称为似然函数,后面那部分P(c) 称为先验概率。
前面提到使用词袋模型来表示 文档d,文档d的每个特征表示为:d={f1,f2,f3……fn},那么这里的特征fi 其实就是单词wi 出现的频率(次数),公式三转化成如下形式:
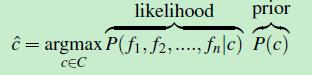 (公式四)
(公式四)
对文档d 做个假设:假设各个特征之间是相互独立的。那么p(f1,f2……fn|c)=p(f1|c)*p(f2|c)*……*p(fn|c),公式四转化成如下形式:
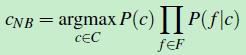 (公式五)
(公式五)
由于每个概率值很小(比如0.0001)若干个很小的概率值直接相乘,得到的结果会越来越小。为了避免计算过程出现下溢(underflower),引入对数函数Log,在 log space中进行计算。然后使用词袋模型的每个单词wi 出现频率作为特征,得到如下公式
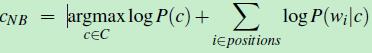 (公式六)
(公式六)
五,训练朴素贝叶斯分类器
训练朴素贝叶斯的过程其实就是计算先验概率和似然函数的过程。
①先验概率P(c)的计算
P(c)的意思是:在所有的文档中,类别为c的文档出现的概率有多大?假设训练数据中一共有Ndoc篇文档,只要数一下类别c的文档有多少个就能计算p(c)了,类别c的文档共有Nc篇,先验概率的计算公式如下:
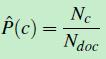 (公式七)
(公式七)
【先验概率 其实就是 准备干一件事情时,目前已经掌握了哪些信息了】关于先验信息理解,可参考:这篇文章。
For the document prior P(c) we ask what percentage of the documents in our training set are in each class c.
Let Nc be the number of documents in our training data with
class c and Ndoc be the total number of documents
②似然函数P(wi|c)的计算
由于是用词袋模型表示一篇文档d,对于文档d中的每个单词wi,找到训练数据集中所有类别为c的文档,数一数 单词wi在这些文档(类别为c)中出现的次数:count(wi,c)
然后,再数一数训练数据集中类别为c的文档一共有多少个单词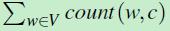 。计算 二者之间的比值,就是似然函数的值。似然函数计算公式如下:
。计算 二者之间的比值,就是似然函数的值。似然函数计算公式如下:
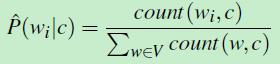 (公式八)
(公式八)
其中V,就是词库。(有些单词在词库中,但是不属于类别C,那么 count(w,c)=0)
Here the vocabulary V consists of the union of all the word types in all classes, not just the words in one class c.
从上面计算似然函数的过程来看,其实相当于一个发掘(统计)潜藏规律的过程。
六,unknow words的情形
假设只考虑文本二分类:将文档分成 positve类别,或者negative类别,C={positive, negative}
在训练数据集中,类别为positive的所有文档 都没有 包含 单词wi = fantastic(fantastic可能出现在类别为negative的文档中)
那么 count(wi=fantastic,ci=positive)=0 。那么:
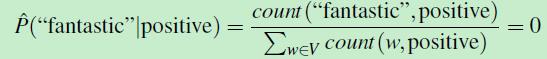
而注意到前面公式五中的累乘,整篇文档的似然函数值为0,也就是说:如果文档d中有个单词fantastic在类别为c的训练数据集文档中从未出现过,那文档d被分类到类别c的概率为0,尽管文档d中还有一些其他单词(特征),而这些单词所代表的特征认为文档d应该被分类 到 类别c中
But since naive Bayes naively multiplies all the feature likelihoods together, zero
probabilities in the likelihood term for any class will cause the probability of the
class to be zero, no matter the other evidence!
解决方案就是 add-one smoothing。(不介绍了),其实就是将“出现次数加1”。似然函数公式变成如下形式:
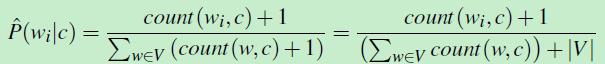 (公式九)
(公式九)
其中|V|是词库中所有单词的个数。
七,朴素贝叶斯分类示例
假设训练数据集有五篇文档,其中Negative类别的文档有三篇,用符号 \'-\' 标识;Positive类别的文档有二篇,用符号 \'+\' 标识,它们的内容如下:
- just plain boring
- entirely predictable and lacks energy
- no surprises and very few laughs
+ very powerful
+ the most fun film of the summer
测试数据集T 有一篇文档dt,内容如下:
predictable with no fun
朴素贝叶斯分类器会把“predictable with no fun”归为哪个类呢?根据第五节“训练朴素贝叶斯分类器”,需要计算先验概率和似然函数。
由于训练数据集中一共有5篇文档,其中类别 \'+\' 的文档有2篇,类别为 \'-\' 的文档有3篇,因此先验概率:P(c)=P(\'-\')=Nc/Ndoc=3/5=0.6
类别为\'+\' 的文档有2篇,故 P(c)=P(\'+\')=Nc/Ndoc=2/5=0.4
对测试数据集文档dt中的每个单词,似然函数采用“add-one smoothing”处理,计算相应的似然概率:
首先单词 predictable 在训练数据集中 类别为\'-\'的文档中只出现了1次,类别为\'-\'的文档一共有14个单词,训练数据集中两种类型的文档加起来一共有23个单词,但是有三个单词(and、
very、the)重复出现了两次,故词库V的大小为 20。因此单词predictable对应的似然概率如下:
p(predictable|\'-\')=(1+1)/(14+20)=2/34
同理:p(predictable|\'+\')=(0+1)/(9+20)=1/29 (predictable没有在类别为\'+\'的训练数据集中出现过)
类似地:p(no|\'-\')=(1+1)/(14+20) p(no|\'+\')=(0+1)/(9+20)
p(fun|\'-\')=(0+1)/(14+20) p(fun|\'+\')=(1+1)/(9+20)
因此,测试集中的文档d归类为 \'-\' 的概率为:0.6 * (2*2*1)/343 = 6.1*10-5
测试集中的文档d归类为 \'+\' 的概率为:0.4*(1*1*2)/293 =3.2*10-5
比较上面两个概率的大小,就可以知道将“predictable with no fun”归为 \'-\' 类别。
八,参考资料
CS 124: From Languages to Information
机器学习中的贝叶斯方法---先验概率、似然函数、后验概率的理解及如何使用贝叶斯进行模型预测(1)
机器学习中的贝叶斯方法---先验概率、似然函数、后验概率的理解及如何使用贝叶斯进行模型预测(2)
以上是关于朴素贝叶斯文本分类简单介绍的主要内容,如果未能解决你的问题,请参考以下文章