机器学习基础——朴素贝叶斯做文本分类代码实战
Posted TechFlow
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习基础——朴素贝叶斯做文本分类代码实战相关的知识,希望对你有一定的参考价值。
上一篇文章当中我们介绍了朴素贝叶斯模型的基本原理。
朴素贝叶斯的核心本质是假设样本当中的变量服从某个分布,从而利用条件概率计算出样本属于某个类别的概率。一般来说一个样本往往会含有许多特征,这些特征之间很有可能是有相关性的。为了简化模型,朴素贝叶斯模型假设这些变量是独立的。这样我们就可以很简单地计算出样本的概率。
想要回顾其中细节的同学,可以点击链接回到之前的文章:
在我们学习算法的过程中,如果只看模型的原理以及理论,总有一些纸上得来终觉浅的感觉。很多时候,道理说的头头是道,可是真正要上手的时候还是会一脸懵逼。或者是勉强能够搞一搞,但是过程当中总会遇到这样或者那样各种意想不到的问题。一方面是我们动手实践的不够, 另一方面也是理解不够深入。
今天这篇文章我们实际动手实现模型,并且在真实的数据集当中运行,再看看我们模型的运行效果。
朴素贝叶斯与文本分类
一般来说,我们认为狭义的事件的结果应该是有限的,也就是说事件的结果应该是一个离散值而不是连续值。所以早期的贝叶斯模型,在引入高斯混合模型的思想之前,针对的也是离散值的样本(存疑,笔者推测)。所以我们先抛开连续特征的场景,先来看看在离散样本当中,朴素贝叶斯模型有哪些实际应用。
在机器学习广泛的应用场景当中,有一个非常经典的应用场景,它的样本一定是离散的,它就是自然语言处理(Natural Language Processing)。在语言当中,无论是什么语言,无论是一个语句或是一段文本,它的最小单位要么是一个单词,要么是一个字。这些单元都是离散的,所以天生和朴素贝叶斯模型非常契合。
我们这次做的模型针对的场景是垃圾邮件的识别,这应该是我们生活当中经常接触到的功能。现在的邮箱基本上都有识别垃圾邮件的功能,如果发现是垃圾邮件,往往会直接屏蔽,不会展示给用户。早期的垃圾邮件和垃圾短信识别的功能都是通过朴素贝叶斯实现的。
在这个实验当中,我们用的是UCI的数据集。UCI大学的机器学习数据集非常出名,许多教材和课本上都使用了他们的数据集来作为例子。我们可以直接通过网页下载他们的数据,UCI的数据集里的数据都是免费的。
https://archive.ics.uci.edu/ml/datasets/sms+spam+collection
下载完成之后,我们先挑选其中几条来看看:
ham Go until jurong point, crazy.. Available only in bugis n great world la e buffet... Cine there got amore wat...
ham Ok lar... Joking wif u oni...
spam Free entry in 2 a wkly comp to win FA Cup final tkts 21st May 2005. Text FA to 87121 to receive entry question(std txt rate)T&C's apply 08452810075over18's
ham U dun say so early hor... U c already then say...
这份数据是以txt文件类型保存,每行文本的第一个单词表示文本的类别,其中ham表示正常,spam表示是垃圾邮件。
我们首先读取文件,将文件当中的内容先读取到list当中,方便我们后续的处理。
def read_file(filename):file = open(filename, 'r')content = []for line in file.readlines():content.append(line)return content
我们查看一下前三条数据:

可以发现类别和正文之间通过\t (tab)分开了,我们可以直接通过python的split方法将类别和正文分开。其中类别也就是我们想要模型学习的结果,在有监督学习当中称为label。文本部分也就是模型做出预测的依据,称为特征。在文本分类场景当中,特征就是文本信息。
我们将label和文本分开:
labels = []data = []for i in smsTxt:row = i.split('\t')if len(row) == 2:labels.append(row[0])data.append(row[1])
过滤标点符号
将文本和label分开之后,我们就需要对文本进行处理了。在进行处理之前,我们先随便拿一条数据来查看一下,这里我们选择了第一条:
'Go until jurong point, crazy.. Available only in bugis n great world la e buffet... Cine there got amore wat...\n'
这是一条非常典型的未处理之前的文本,当中不仅大小写字母混用,并且还有一些特殊符号。所以文本处理的第一步就是把所有字母全部小写,以及去除标点符号。
说起来比较复杂,但只要使用正则表达式,我们可以很方便地实现:
import re# 只保留英文字母和数字rule = re.compile("[^a-zA-Z\d ]")for i in range(len(data)):data[i] = re.sub("[^a-zA-Z\d ]", '', data[i].lower())
最后得到的结果如下:
go until jurong point crazy available only in bugis n great world la e buffet cine there got amore wat
这里正则表达式非常简单,就是只保留英文字母和数字以及空格,其余所有的内容全部过滤。我们在传入的时候做了大小写转换,会把所有的大写字母转成小写。到这里为止,所有的特殊字符就都处理掉了,接下来就可以进行分词了。
英文的分词很简单,我们直接根据空格split即可。如果是中文分词,可以使用一些第三方库完成,之前的文章里介绍过,这里就不赘述了。
安装nltk
在接下来的文本处理当中,我们需要用到一个叫做nltk的自然语言处理的工具库。当中集成了很多非常好用的NLP工具,和之前的工具库一样,我们可以直接使用pip进行安装:
pip3 install nltk这里强烈建议使用Python3,因为Python2已经不再维护了。这步结束之后,只是装好了nltk库,nltk当中还有很多其他的资源文件需要我们下载。我们可以直接通过python进行下载:
import nltknltk.download()
调用这个代码之后会弹出一个下载窗口:
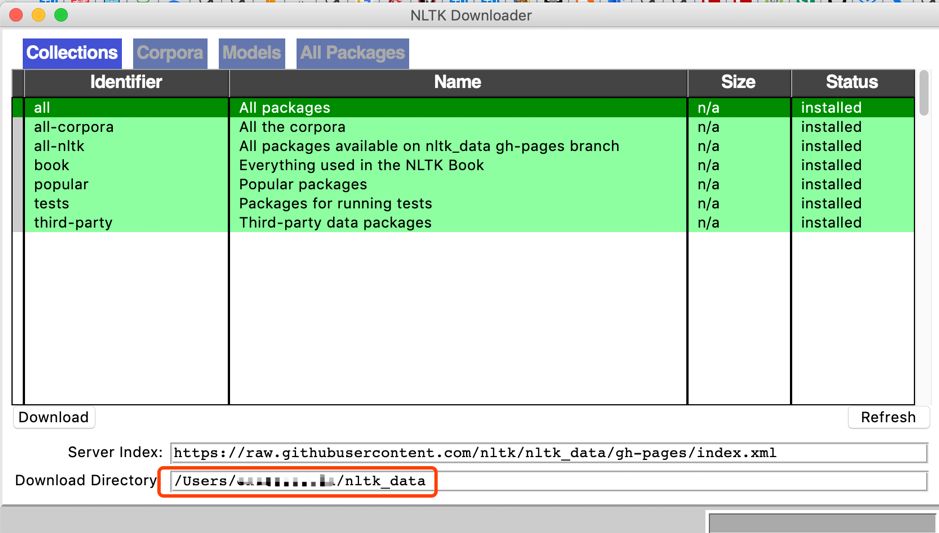
需要注意的是,必须要把数据放在指定的位置,具体的安装位置可以调用一下download方法之后查看红框中的路径。或者也可以使用清华大学的镜像源,使用命令:
pip3 install -i https://pypi.tuna.tsinghua.edu.cn/simple/nltk下载好了之后,我们在Python当中执行:
fron nltk.book import *如果出现以下结果,就说明已经安装完毕:

去除停用词
装好了nltk之后,我们要做的第一个预处理是去除停用词。
停用词英文是stop words,指的是文本当中对语义无关紧要的词汇。包含了常见的虚词、助词、介词等等。这些词语大部分只是修饰作用,对文本的语义内容起不到决定作用。因此在NLP领域当中,可以将其过滤,从而减少计算量提升模型精度。
Nltk当中为常见的主流语言提供了停用词表(不包括中文),我们传入指定的语言,将会返回一个停用词的list。我们在分词之后根据停用词表进行过滤即可。
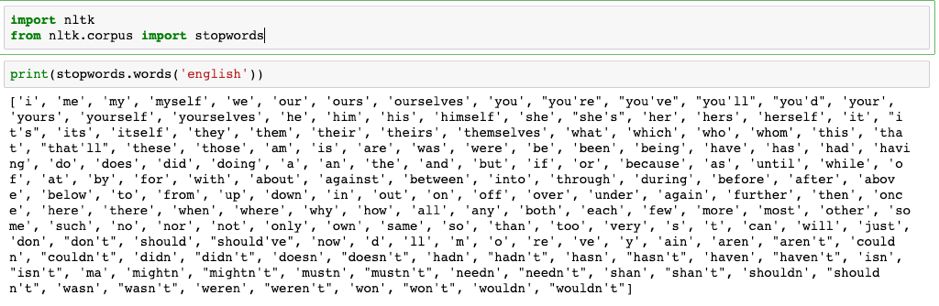
我们可以打印出所有英文的停用词看一下,大部分都是一些虚词和助词,可能出现在所有语境当中,对我们对文本进行分类几乎没有帮助。
词性归一化
众所周知,英文当中的单词有很多形态。比如名词有单复数形式,有些特殊的名词复数形式还很不一样。动词有过去、现在以及未来三种时态,再加上完成时和第三人称一般时等,又有很多变化。
举例来说,do这个动词在文本当中会衍生出许多小词来。比如does, did, done, doing等,这些单词虽然各不相同,但是表示的意思完全一样。因此,在做英文NLP模型的时候,需要将这些时态的单词都还原成最基本的时态,这被称为是词性归一化。
原本这是一项非常复杂的工作,但我们有了nltk之后,这个工作变得简单了很多。要做单词归一化,我们需要用到nltk当中的两个工具。
第一个方法叫做pos_tag, 它接收一个单词的list作为入参。返回也是一个tuple的list,每个tuple当中包含两个值,一个是单词本身,第二个参数就是我们想要的词性。
举个例子:

我们传入只有一个单词apple的list,在返回的结果当中除了apple之外,还多了一个NN,它表示apple是一个名词nouns。
关于返回的词性解释,感兴趣的可以自行查看官方文档的说明。
我们这里并不需要区分那么细,只需要区分最常用的动词、名词、形容词、副词就基本上够了。
我们可以直接根据返回结果的首字母做个简单的映射:
from nltk import word_tokenize, pos_tagfrom nltk.corpus import wordnetfrom nltk.stem import WordNetLemmatizer# 获取单词的词性def get_wordnet_pos(tag):if tag.startswith('J'):return wordnet.ADJelif tag.startswith('V'):return wordnet.VERBelif tag.startswith('N'):return wordnet.NOUNelif tag.startswith('R'):return wordnet.ADVelse:return None
通过pos_tag方法我们很容易就可以拿到单词的词性,但是这还不够,我们还需要将它还原成最基础的形态。这个时候需要用到另一个工具:WordNetLemmatizer
它的用途是根据单词以及单词的词性返回单词最一般的形态,也就是归一化的操作。
举个例子:

我们传入了box的复数形式:boxes,以及box对应的名词,它返回的结果正是我们想要的box。
我们结合刚刚实现的查询单词词性的方法,就可以完成单词的归一化了。
到这里为止,关于文本的初始化就算是差不多结束了。除了刚刚提到的内容之外,nltk还包含许多其他非常方便好用的工具库。由于篇幅的限制,我们不能一一穷尽,感兴趣的读者可以自行钻研,相信一定会很有收获。
下面,我们把刚才介绍的几种文本预处理的方法一起用上,对所有的短信进行预处理:
for i in range(len(data)):data[i] = re.sub("[^a-zA-Z ]", '', data[i].lower())tokens = data[i].split(' ') # 分词tagged_sent = pos_tag([i for i in tokens if i and not i in stopwords.words('english')]) # 获取单词词性wnl = WordNetLemmatizer()lemmas_sent = []for tag in tagged_sent:wordnet_pos = get_wordnet_pos(tag[1]) or wordnet.NOUNlemmas_sent.append(wnl.lemmatize(tag[0], pos=wordnet_pos))data[i] = lemmas_sent
通过nltk的工具库,我们只需要几行代码,就可以完成文本的分词、停用词的过滤以及词性的归一化等工作。
接下来,我们就可以进行朴素贝叶斯的模型的训练与预测了。
首先,我们需要求出背景概率。所谓的背景概率,也就是指在不考虑任何特征的情况下,这份样本中信息当中天然的垃圾短信的概率。
这个其实很简单,我们只需要分别其实正常的邮件与垃圾邮件的数量然后分别除以总数即可:
def base_prob(labels):pos, neg = 0.0, 0.0for i in labels:if i == 'ham':neg += 1else:pos += 1return pos / (pos + neg), neg / (pos + neg)
我们run一下测试一下结果:

可以看到垃圾短信的概率只占13%,大部分短信都是正常的。这也符合我们的生活经验,毕竟垃圾短信是少数。
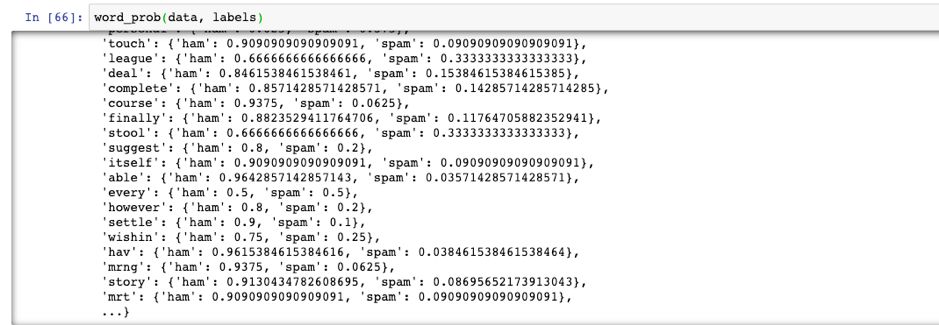
接下来我们需要求出每个单词属于各个类别的概率,也就是要求一个单词的概率表。这段代码稍微复杂一些,但是也不麻烦:
def word_prob(data, labels):n = len(data)word_dict = {}for i in range(n):lab = labels[i]dat = list(set(data[i]))for word in dat:if word not in word_dict:word_dict[word] = {'ham' : 1, 'spam': 1}word_dict[word][lab] += 1for i in word_dict:dt = word_dict[i]ham = dt['ham']spam = dt['spam']word_dict[i]['ham'] = ham / float(ham + spam)word_dict[i]['spam'] = spam / float(ham + spam)return word_dict
同样,我们运行一下测试一下结果:
这些都有了之后,就是预测的重头戏了。这里有一点需要注意,根据我们上文当中的公式,我们在预测文本的概率的时候,会用到多个概率的连乘。由于浮点数有精度限制,所以我们不能直接计算乘积,而是要将它转化成对数,这样我们就可以通过加法来代替乘法,就可以避免连乘带来的精度问题了。
import mathdef predict(samples, word_prob, base_p, base_n):ret = []for sam in samples:neg = math.log(base_n)pos = math.log(base_p)for word in sam:if word not in word_prob:continueneg += math.log(word_prob[word]['spam'])pos += math.log(word_prob[word]['ham'])ret.append('ham' if pos > neg else 'spam')return ret
预测的方法也非常简单,我们分别计算出一个文本属于spam以及ham的概率,然后选择概率较大的那个作为最终的结果即可。
我们将原始数据分隔成训练集以及预测集,调用我们刚刚编写的算法获取预测的结果:
from sklearn.model_selection import train_test_splitx_train, x_test, y_train, y_test = train_test_split(data, labels, test_size=0.25)base_p, base_n = base_prob(y_train)word_dt = word_prob(x_train, y_train)ret = predict(x_test, word_dt, base_p, base_n)
最后,我们调用一下sklearn当中的classification_report方法来获取贝叶斯模型的预测效果:
从上图当中看,贝叶斯模型的预测效果还是不错的。对于垃圾文本识别的准确率有90%,可惜的是召回率低了一点,说明有一些比较模糊的垃圾文本没有识别出来。这也是目前这个场景下问题的难点之一,但总的来说,贝叶斯模型的原理虽然简单,但是效果不错,也正因此,时至今日,它依旧还在发挥着用处。
NLP是当今机器学习领域非常复杂和困难的应用场景之一,关于文本的预处理以及模型的选择和优化都存在着大量的操作。本文当中列举的只是其中最简单也是最常用的部分。
到这里,关于朴素贝叶斯的实践就结束了。我想亲手从零开始写出一个可以用的模型,一定是一件非常让人兴奋的事情。但关于朴素贝叶斯模型其实还没有结束,它仍然有许多细节等待着大家去思考,也有很多引申的知识。模型虽然简单,但仍然值得我们用心地体会。
今天的文章就到这里,如果觉得有所收获,请顺手点个在看或者转发吧,你们的支持是我最大的动力。
以上是关于机器学习基础——朴素贝叶斯做文本分类代码实战的主要内容,如果未能解决你的问题,请参考以下文章