同步自我的知乎专栏文章:https://zhuanlan.zhihu.com/p/32135185
从Slerp说起
ICLR‘2017的投稿里,有一篇很有意思但被拒掉的投稿《Sampling Generative Networks》 by Tom White。文章比较松散地讲了一些在latent space挺有用的采样和可视化技巧,其中一个重要的点是指出在GAN的latent space中,比起常用的线性插值,沿着两个采样点之间的“弧”进行插值是更合理的办法。实现的方法就是图形学里的Slerp(spherical linear interpolation)在高维空间中的延伸:
形象理解并不难,以wiki上的图为例:
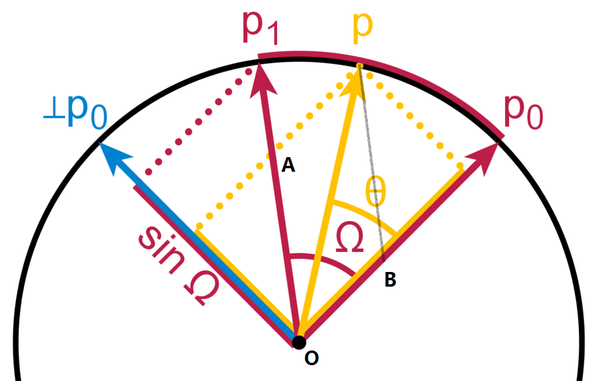
要求的是图中P点,在Wiki图的基础上我加了A、B和O三个点,O就是原点。所以P其实就是 \vec {OP}=\vec {OA} + \vec {OB} 。先考虑求
\vec {OP}=\vec {OA} + \vec {OB} 。先考虑求  \vec {OA} ,第一步引入和
\vec {OA} ,第一步引入和  \vec {OP_0} 垂直的
\vec {OP_0} 垂直的  \vec {O\perp P_0} ,也就是图中蓝色的箭头。那么
\vec {O\perp P_0} ,也就是图中蓝色的箭头。那么  \left| OA \right| 和
\left| OA \right| 和  \left| OP_1 \right| 的比值就等于他们分别投影到蓝色向量上的部分的比值,也就是蓝色箭头两侧的橙色线段比红色线段。这个比值正是
\left| OP_1 \right| 的比值就等于他们分别投影到蓝色向量上的部分的比值,也就是蓝色箭头两侧的橙色线段比红色线段。这个比值正是  \frac{\sin \theta}{\sin \Omega} ,于是 \vec {OA} 就是
\frac{\sin \theta}{\sin \Omega} ,于是 \vec {OA} 就是 %7D%7Bsin(%5COmega)%7D%20p_1) \frac{sin(\theta)}{sin(\Omega)} p_1 。很显然,同样的方法也可以用来求
\frac{sin(\theta)}{sin(\Omega)} p_1 。很显然,同样的方法也可以用来求 %7D%7Bsin(%5COmega)%7D%20p_0) \vec {OB}=\frac{sin(\Omega-\theta)}{sin(\Omega)} p_0 ,然后代入
\vec {OB}=\frac{sin(\Omega-\theta)}{sin(\Omega)} p_0 ,然后代入  \vec {OP}=\vec {OA}+\vec {OB} ,并令
\vec {OP}=\vec {OA}+\vec {OB} ,并令  \theta=t\Omega ,就得到了Slerp的公式。注意虽然推导的时候用的虽然是
\theta=t\Omega ,就得到了Slerp的公式。注意虽然推导的时候用的虽然是  P_0 和
P_0 和  P_1 在同一个(超)球面上,但是实际用的时候不同长度的 P_0 和 P_1 之间利用Slerp也是可以很自然的插值的,得到的向量长度介于二者之间且单调(非线性)增减。ICLR的Review中也讨论到了这个问题。
P_1 在同一个(超)球面上,但是实际用的时候不同长度的 P_0 和 P_1 之间利用Slerp也是可以很自然的插值的,得到的向量长度介于二者之间且单调(非线性)增减。ICLR的Review中也讨论到了这个问题。
使用Slerp比起纯线性插值的好处在哪里呢?作者原文这样解释:
"Frequently linear interpolation is used, which is easily understood and implemented. But this is often inappropriate as the latent spaces of most generative models are high dimensional (> 50 dimensions) with a Gaussian or uniform prior. In such a space, linear interpolation traverses locations that are extremely unlikely given the prior. As a concrete example, consider a 100 dimensional space with the Gaussian prior μ=0, σ=1. Here all random vectors will generally a length very close to 10 (standard deviation < 1). However, linearly interpolating between any two will usually result in a "tent-pole" effect as the magnitude of the vector decreases from roughly 10 to 7 at the midpoint, which is over 4 standard deviations away from the expected length."
就是说在高维(>50)的空间里做线性插值,会路过一些不太可能路过的位置,就好像数据都分布在帐篷布上,但是线性插值走的是帐篷杆。
要更具体理解这个现象,还要从GAN中常用的prior distribution说起。在GAN中,最常用的是uniform和Gaussian(感觉现在Gaussian居多)。不管是哪种prior,对于一个n维样本 ) \left( x_1,x_2,\dots,x_n \right) ,到中心的欧式距离为:
\left( x_1,x_2,\dots,x_n \right) ,到中心的欧式距离为:
而通常GAN的采样空间维度还算高,这个时候我们把d的平方看作是一连串n个独立同分布的随机变量  x_1^2,x_2^2,\dots,x_n^2 的和,则由中心极限定理可知d的平方近似服从正态分布(实际上是Chi-square分布):
x_1^2,x_2^2,\dots,x_n^2 的和,则由中心极限定理可知d的平方近似服从正态分布(实际上是Chi-square分布):
考虑很常见的100维标准正态分布作为prior的情况,平方之后就是k=1的Chi-square分布,均值为1,方差为2。所以每个样本到原点的距离的平方近似服从N(100, 200),标准差~14.14,如果认为  \delta =14.14/100已经足够小,使
\delta =14.14/100已经足够小,使  \sqrt{1+\delta}\approx1+\frac 1 2\delta ,则d也可以近似看作是一个高斯分布(实际上是Chi分布),均值为10,标准差为0.707,就是作者在原文中说的情况。
\sqrt{1+\delta}\approx1+\frac 1 2\delta ,则d也可以近似看作是一个高斯分布(实际上是Chi分布),均值为10,标准差为0.707,就是作者在原文中说的情况。
uniform prior的情况也类似,不过更加复杂,因为均匀分布并非各向同性。在高维空间中,一个超立方体形状如果脑补一下就是一个球周边长了很多尖刺,每个尖刺就是象限中的一个极端值。具体推导我不会,不过写个程序很容易模拟。采10万个样本得到的结果是100维,每个维度[-1, 1]的均匀分布的prior,样本到中心的距离平均值约为5.77,标准差约0.258。所以无论是哪种情况,高维空间里的样本都有一个特点:远离中心,且集中分布在均值附近。所以线性插值就会像在帐篷杆上插值一样,路过真实样本出现概率极低的区域。
原文还提到了在100维Gaussian prior的情况下,线性插值取到的点到中心的距离会从10到7,这怎么理解呢?我的数学水平脑补不了这件事,定性来看随机采两个样本,这两个样本趋于垂直的倾向会很高,因为要趋于同向或者反向需要每一维的距离都足够近或足够远,这个概率会很低。定量的话可以写个程序模拟:
import numpy from matplotlib import pyplot def dist_o2l(p1, p2): # distance from origin to the line defined by (p1, p2) p12 = p2 - p1 u12 = p12 / numpy.linalg.norm(p12) l_pp = numpy.dot(-p1, u12) pp = l_pp*u12 + p1 return numpy.linalg.norm(pp) dim = 100 N = 100000 rvs = [] dists2l = [] for i in range(N): u = numpy.random.randn(dim) v = numpy.random.randn(dim) rvs.extend([u, v]) dists2l.append(dist_o2l(u, v)) dists = [numpy.linalg.norm(x) for x in rvs] print(‘Distances to samples, mean: {}, std: {}‘.format(numpy.mean(dists), numpy.std(dists))) print(‘Distances to lines, mean: {}, std: {}‘.format(numpy.mean(dists2l), numpy.std(dists2l))) fig, (ax0, ax1) = pyplot.subplots(ncols=2, figsize=(11, 5)) ax0.hist(dists, 100, normed=1, color=‘g‘) ax1.hist(dists2l, 100, normed=1, color=‘b‘) pyplot.show()
结果如下:
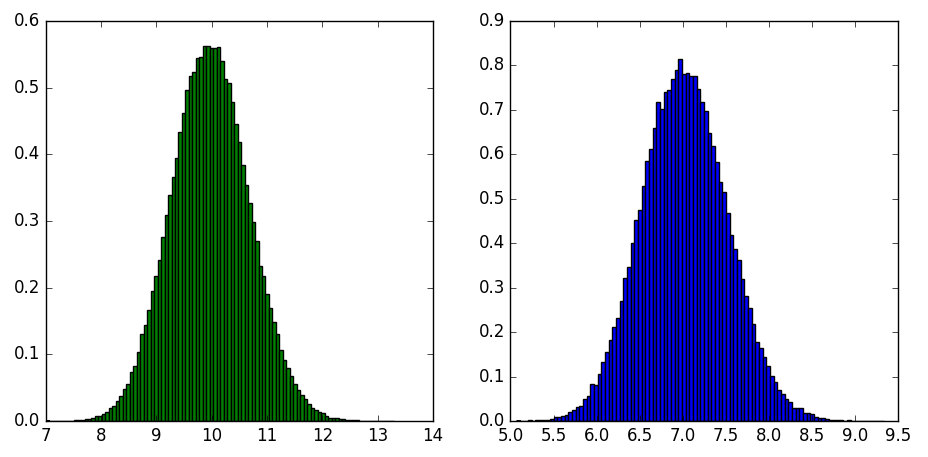
左边是在latent space里随机采样的样本到中心距离的分布,右边是原点在随机采样的两个样本所在直线上的投影点到中心距离的分布,也就是线性插值中到中心最近点的距离的分布。可以看到随机采样并进行线性插值的办法还真的是容易路过样本几乎不可能出现的区域(距原点距离5~7.5)。可是《Sampling Generative Networks》被拒的comment里有一句:"neither the reviewers nor I were convinced that spherical interpolation makes more sense than linear interpolation"。就这一点来说,感觉Tom White有些冤枉,虽然确实不是什么眼前一亮的大改进,但是有理有据。那为什么reviewer们没觉得比线性插值好多少呢?原因可能就是:
基于ReLU网络的线性
CNN在12年的时候一鸣惊人,应该说ReLU一系的激活函数扮演了一个至关重要的角色:让深层网络可训练。后续的无论是LeakyReLU、ELU还是Swish等等,大于0的部分都是非常线性的。所以虽然非线性变换(激活函数)是神经网络作为universal approximator的基础,但基于ReLU系的神经网络其实是线性程度很高的。对于常见判别式网络,Ian Goodfellow认为这种线性再加上Distributed Representation的超强表达能力是使得网络容易被对抗样本攻击的基础(详见这篇),并据此发明了Fast Gradient Sign方法快速生成对抗样本。
那么基于ReLU的CNN的线性有多强呢?先来看生成式网络,以DCGAN为例,示意图如下
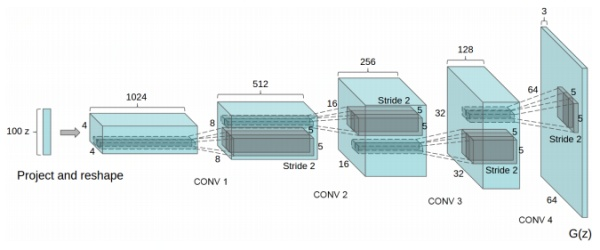
从结构上来看,DCGAN比常见的判别式网络更加线性,因为连max pooling都没了,不那么线性的部分就只有最后输出图片的Tanh。尤其是从latent space到第一组feature map这一步,常见的实现方法是把100维的噪声看成是100个channel,1x1的feature map,然后直接用没有bias的transposed convolution上采样,是一个纯线性变换!定性来看,如果整个后续的网络部分线性程度也足够高,则在latent space的任意样本,同时对所有维度进行缩放的话,得到的图像应该差不多就是同一幅图不同的对比度。
训练一个GAN的生成器就可以验证这个结论,感谢何之源在文章GAN学习指南:从原理入门到制作生成Demo中提供了一份对GAN而言高质量且好下载的动漫头像数据。基于这个数据和PyTorch的官方DCGAN例子就可以很轻松的训练出一个模型。基于训练出的模型随机采样并分别进行Slerp和线性插值,结果如下:






1、3、5行是线性插值的结果,2、4、6是Slerp结果,仔细看的话会发现线性插值结果的中间部分和Slerp相比,颜色淡了那么一点点,除此以外差别微乎其微。也难怪Reviewer会觉得Tom White的结论不令人信服,如果没有对比,线性插值的结果看起来很好。并且由于高维空间中样本远离中心的特性,所以线性插值的均匀性和Slerp也差不多。不过有了上面的分析,再回过头来看DCGAN原文中的线性插值结果,好像中间部分看起来颜色还真是有点淡……

直接对比Slerp和线性插值并不是很有说服力,我们可以做一个更暴力的实验,让样本沿着一个随机方向从原点出发一直到距离原点20的位置,结果如下:



还是挺一目了然的,随着latent sample渐渐远离原点,图像的变化基本上是对比度越来越高,直至饱和。起码就人眼来说,这是很线性的。那么实际上呢?如果去掉Tanh层,随机取一些样本和输出图像随机位置的值,画出随着latent sample距中心距离变化的趋势,大概是下面这样:
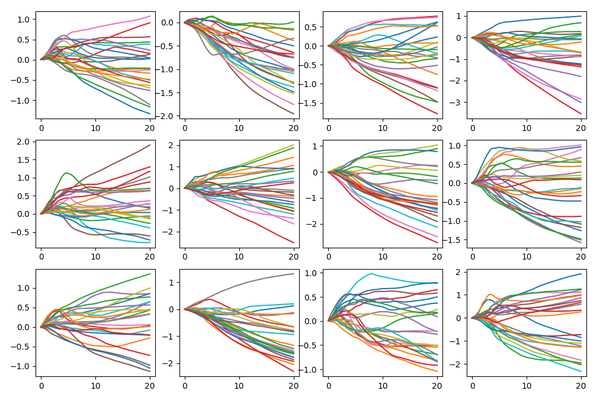
可以看到,只有在距离中心很远的时候,线性才比较明显,这和Goodfellow论文中的图性质一致。在样本最集中的10附近,线性程度一般般,甚至有些输出都不是单调的。
那么更进一步,如果latent sample只产生在超球面上呢?或是到原点距离均匀分布呢?不妨试一试,结果如下:
1) 在到原点距离为10的超球面上产生latent sample



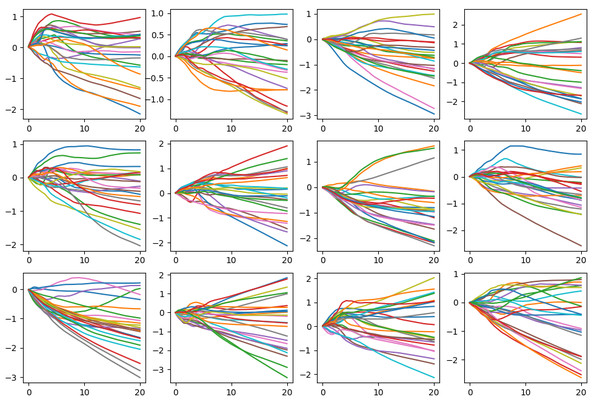
肉眼看上去还是很线性,输出曲线的结果看上去和直接Gaussian采样差别也不大。
2) latent sample到原点距离从0到10均匀分布



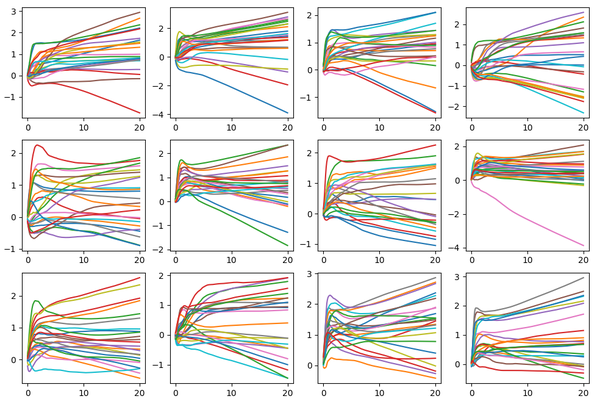
从曲线来看和前两种情况明显不一样了,生成图像质量也下降了一些。但是从产生的图片来看线性仍然较强,至少到中心距离<10的部分,图片“身份”无区分度的结论还是基本成立。
这是个很有趣的现象,无论是Gaussian采样,还是1)和2)的情况,对人眼来说,这种很粗略程度的线性已经足够让沿着某个方向上的latent sample产生从“身份”角度看上去无差别的样本了。不管怎么样,基于这个现象,得到一个粗略的推论:GAN的Latent Space只有沿着超球面的变化才是有区分力的。
在Great Circle上行走
经过一番分析,得到了一个好像也没什么用的结论。再回来看最初的问题,线性插值会路过低概率区域(虽然并没有什么影响),Slerp比线性插值也没什么视觉上的本质提高,那么有没有什么更优雅地行走在latent space的方法呢?我觉得是:Great Circle。比起Slerp,Greate Circle通常要经过多3倍的距离,虽然这和Slerp其实也没什么本质区别,但是感觉上要更屌,而且沿着great circle走起点和终点是同一个点,这感觉更屌。
产生great circle路径比Slerp要简单得多:1)根据所使用分布产生一个超球面半径r(按前面讨论,Gaussian的话就是chi分布,或者Gaussian近似);2)产生一个随机向量u和一个与u垂直的随机向量v,然后把u和v所在平面作为great circle所在平面;3)u和v等效于一个坐标系的两轴,所以great circle上任一点就用在u和v上的投影表示就可以,最后在乘上r就得到了行走在great circle上的采样。代码如下:
from __future__ import print_function import argparse import os import numpy from scipy.stats import chi import torch.utils.data from torch.autograd import Variable from networks import NetG from PIL import Image parser = argparse.ArgumentParser() parser.add_argument(‘--nz‘, type=int, default=100, help=‘size of the latent z vector‘) parser.add_argument(‘--niter‘, type=int, default=10, help=‘how many paths‘) parser.add_argument(‘--n_steps‘, type=int, default=23, help=‘steps to walk‘) parser.add_argument(‘--ngf‘, type=int, default=64) parser.add_argument(‘--ngpu‘, type=int, default=1, help=‘number of GPUs to use‘) parser.add_argument(‘--netG‘, default=‘netG_epoch_49.pth‘, help="trained params for G") opt = parser.parse_args() output_dir = ‘gcircle-walk‘ os.system(‘mkdir -p {}‘.format(output_dir)) print(opt) ngpu = int(opt.ngpu) nz = int(opt.nz) ngf = int(opt.ngf) nc = 3 netG = NetG(ngf, nz, nc, ngpu) netG.load_state_dict(torch.load(opt.netG, map_location=lambda storage, loc: storage)) netG.eval() print(netG) for j in range(opt.niter): # step 1 r = chi.rvs(df=100) # step 2 u = numpy.random.normal(0, 1, nz) w = numpy.random.normal(0, 1, nz) u /= numpy.linalg.norm(u) w /= numpy.linalg.norm(w) v = w - numpy.dot(u, w) * u v /= numpy.linalg.norm(v) ndimgs = [] for i in range(opt.n_steps): t = float(i) / float(opt.n_steps) # step 3 z = numpy.cos(t * 2 * numpy.pi) * u + numpy.sin(t * 2 * numpy.pi) * v z *= r noise_t = z.reshape((1, nz, 1, 1)) noise_t = torch.FloatTensor(noise_t) noisev = Variable(noise_t) fake = netG(noisev) timg = fake[0] timg = timg.data timg.add_(1).div_(2) ndimg = timg.mul(255).clamp(0, 255).byte().permute(1, 2, 0).numpy() ndimgs.append(ndimg) print(‘exporting {} ...‘.format(j)) ndimg = numpy.hstack(ndimgs) im = Image.fromarray(ndimg) filename = os.sep.join([output_dir, ‘gc-{:0>6d}.png‘.format(j)]) im.save(filename)
结果如下:








虽然感觉没什么用,不过万一有人想试试,代码在此:great-circle-interp