被ICLR拒,字节跳动今获最佳论文
Posted 人工智能博士
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了被ICLR拒,字节跳动今获最佳论文相关的知识,希望对你有一定的参考价值。
点上方人工智能算法与Python大数据获取更多干货
在右上方 ··· 设为星标 ★,第一时间获取资源
仅做学术分享,如有侵权,联系删除
转载于 :机器之心
被顶会拒稿请不要灰心,说不定你的论文会成为另一个顶会的最佳。
昨日,NLP 领域国际顶会 ACL 2021 公布获奖论文信息:来自字节跳动火山翻译的一篇神经机器翻译工作被评为最佳论文。此外,最佳主题论文、杰出论文也揭晓。
ACL,是计算语言学和自然语言处理领域的顶级国际会议,由国际计算语言学协会组织,每年举办一次。
一直以来,ACL 在 NLP 领域的学术影响力都位列第一,它也是 CCF-A 类推荐会议。

今年的 ACL 大会已是第 59 届,计划于 8 月 1-6 日在泰国曼谷举行。
不久之前,ACL 2021 官方发布了关于本届大会接收结果:本届 ACL 共计收到 3350 篇论文投稿,最终有 21.3% 的论文录用到主会(Main Conference),并额外接收了 14.9% 的论文到 Findings 子刊,综合录用率为 36.2%。我们可以从被接收的论文作者与机构中发现,有大量的国内论文被接收。
除了接收论文之外,今年的 ACL 的组织成员里面也有大量的华人面孔,特别是今年的年会主席是中科院自动化研究所的宗成庆老师,程序主席包括华盛顿大学的 Fei Xia 教授、香港理工大学 Wenjie Li 教授。
昨天,大家最为关注的 ACL 2021 获奖论文公布,令人惊喜的是这些获奖论文里面也包含多篇国内研究成果:如来自字节跳动火山翻译的机器翻译研究获得最佳论文,来自港中文、腾讯 AI Lab 合作的论文也入选杰出论文。
最佳论文:字节跳动火山翻译
ACL 2021 的最佳论文来自字节跳动火山翻译团队,该研究提出了一种新的词表学习方案 VOLT,在多种翻译任务上取得了优秀的结果。

标题:Vocabulary Learning via Optimal Transport for Neural Machine Translation
作者:许晶晶、周浩、甘纯、郑在翔、李磊
论文地址:https://arxiv.org/pdf/2012.15671.pdf
代码地址:https://github.com/Jingjing-NLP/VOLT
对于从业者来说,大家无时无刻不在使用词表对语言进行向量化表示。在深度学习时代,词表构建基本上是所有自然语言处理任务的第一步工作。尽管现今也有了一些比较通用的词表处理方法,但是仍然没有办法回答最基础的问题:什么是最优词表,如何生成最优词表?
为了回答该问题,本论文尝试提出一种无需训练的词表评价指标和针对该评价指标的词表学习方案 VOLT。该方案在常用的英德翻译、英法翻译、低资源翻译、多语言翻译上都取得了相比传统词表解决方案更好的结果。

表 1:使用 VOLT 与广泛使用的 BPE 词表进行词汇搜索的结果比较。VOLT 得到了更高的 BLEU 分数,同时大大减少了词汇量。此处采用的是 X-En 设置下的词汇量。
使用 VOLT 生成词汇,简单的基线方法就能够实现 SOTA 结果。该研究在 En-De 数据集上测试了 VOLT 和其他几种方法的性能,结果如表 5 所示。与其他方法相比,VOLT 以更少的词汇量实现了几乎最佳的性能。这些结果表明,简单的基线方法使用定义明确的词表就能够获得良好的结果。
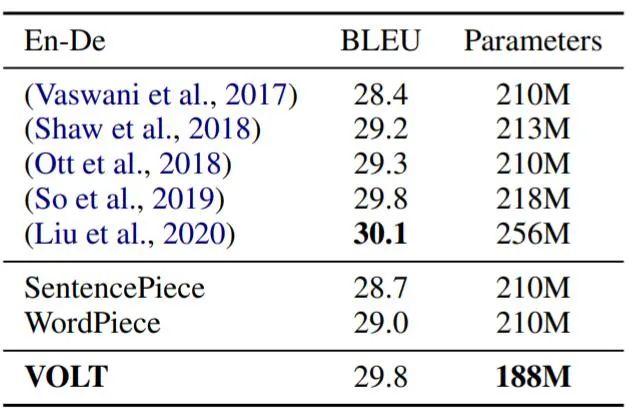
表 5:VOLT 和强基准之间的比较结果。VOLT 在词汇量较少的情况下取得了几乎最好的表现。
值得一提的是,该研究修改前的版本曾投至另一个机器学习顶会 ICLR 2021。在 Openreview 网站上现在还能看到该论文及匿名评审的结果。当时四名评审给出的意见是 3、3、4、4——未达到接收标准,作者做了rebuttal之后撤稿投了ACL。
论文作者之一的周浩在社交网络中表示:「关于从 ICLR 到 ACL 的转投当时情况是这样的,我们在投 ICLR 的时候花了太多时间在实验上,在 writing 上花的时间很不够,整个 paper 显地平铺直叙,Intuition 没有说出来,且有部分重要的实验没有补充。结果大家也看到了,我觉得这是一个重要的 lesson,也欢迎大家对比我们两个版本的论文。」
论文一作许晶晶则总结了经验与教训:「我学到的最重要教训是一定要把东西写清楚。虽然写作不是最重要的,idea 才是,但是写清楚是让评审评价工作的前提。其实 ICLR 的评审和 ACL 的评委都对我们的 Idea 做了肯定,新颖性和有趣性都是被承认的,我们给出的基于最大边际效应的解释,和把词表学习建模成一个最优运输问题都是全新的一套想法。ICLR 对 idea 没有太多问题,问题主要是在写作上,后来我们把写作改进之后,能拿到高分虽然意料之外,倒也在情理之中。有一说一,我们 ICLR 那篇工作确实写的不好。评审的反馈主要在以下几个方面:实验做的不够充分,方法介绍的不够清楚,动机也缺乏直接证据。后来的这几点,我们在 ACL 版本都做了大量的改进。我们补充了很多后续实验,写作也推倒重来,一遍遍推敲逻辑是否合理,实验是不是严谨和充分等等,整个过程是很痛苦的。所以后来我们得到 ACL 的评审认可的时候非常激动,毕竟投入了很多心血的工作终于得到了回报。」
这篇论文在一番改进之后获得了另一个顶会的最佳奖项,过程可谓大起大落。
最佳主题论文:CMU
今年的最佳主题论文(Best theme paper)研究来自卡耐基梅隆大学、巴伊兰大学、加劳德特大学与艾伦人工智能研究所等机构。第一作者殷绮妤(Kayo Yin)本科毕业于巴黎综合理工学院,目前是卡耐基梅隆大学的在读研究生。

标题:Including Signed Languages in Natural Language Processing
作者:Kayo Yin、Amit Moryossef、Julie Hochgesang、Yoav Goldberg、Malihe Alikhani
机构:CMU、巴伊兰大学、加劳德特大学、艾伦人工智能研究所、匹兹堡大学
链接:https://arxiv.org/abs/2105.05222
论文摘要:手语是许多聋哑人和重听人交流的主要手段。由于手语表现了自然语言的所有基本语言特性,该研究认为自然语言处理的工具和理论对其建模至关重要。然而,现有的手语处理 (SLP) 研究很少尝试探索和利用手语的语言结构组织。该研究呼吁 NLP 社区将手语作为具有高度社会和科学影响的研究领域。该研究首先讨论了手语在建模过程中要考虑的语言属性;然后回顾了当前 SLP 模型的局限性,并确定了将 NLP 扩展到手语的开放挑战;最后,该研究建议以下几点 (1) 采用一种有效的 tokenization 方法 (2) 语言信息模型的发展 (3) 真实世界的手语数据的收集(4) 将当地手语社区纳入到积极而主导话语权研究方向中。
六篇杰出论文
除最佳论文以外,今年的 ACL 还评出了六篇杰出论文(Outstanding papers),其中包括港中文、腾讯 AI Lab、斯坦福大学(李飞飞、曼宁等人团队)的研究。
论文 1:All That’s ‘Human’ Is Not Gold: Evaluating Human Evaluation of Generated Text

作者:Elizabeth Clark、Tal August、Sofia Serrano、Nikita Haduong、Suchin Gururangan、Noah A. Smith
机构:华盛顿大学、艾伦人工智能研究所
论文地址:https://arxiv.org/abs/2107.00061
论文摘要:人类评估通常被认为是自然语言生成的黄金标准,但随着模型流畅程度的提升,评估者能够检测、判断出机器生成的文本吗?在这项研究中,研究者评估了非专家在故事、新闻、食谱三个领域中区分人工与机器(GPT-2、GPT-3)撰写文本的能力。他们发现,未经过训练的评估者区分 GPT-3 与人类生成文本的概率是随机的。研究者探索了三种快速训练评估者的方法以更好地识别 GPT-3 生成的文本(详细说明、附加注释的例子和配对例子) ,并发现其准确率提高了 55%,但在上面提到的三个领域仍然没有显著改善。考虑到文本域的结果不一致,以及评估者给出的判断常常相互矛盾,研究者检验了未经训练的人类评估者在自然语言生成评估中所起的作用,并为自然语言生成的研究者们提供了改进人类评估文本生成结果的最新模型建议。
论文 2:Intrinsic Dimensionality Explains the Effectiveness of Language Model Fine-Tuning

作者:Armen Aghajanyan、Sonal Gupta、Luke Zettlemoyer
机构:Facebook
论文地址:https://arxiv.org/abs/2012.13255
论文摘要:尽管可以通过对预训练语言模型进行微调,来为广泛的语言理解任务产生 SOTA 结果,但该过程的具体原理还没有得到很好的解释,尤其是在低数据范围内。为什么使用相对普通的梯度下降算法(例如不包含强大的正则化)就能在只有数百或数千个标记样本的数据集上调整具有数亿个参数的模型?在该论文中,研究者认为从内在维度的角度分析微调,能够得到解释上述现象的实验和理论依据。该研究通过实验表明,常见的预训练模型具有非常低的内在维度;换句话说,存在与完全参数空间一样有效的微调低维重参数化。例如,通过仅优化随机投射回完全空间的 200 个可训练参数,研究者可以调整 RoBERTa 模型以在 MRPC 上实现 90% 的完全参数性能水平。此外,该研究通过实验表明,预训练隐式地最小化了内在维度,也许令人惊讶的是,经过一定数量的预训练更新,较大的模型往往具有较低的内在维度,这在一定程度上解释了它们的极端有效性。最后,研究者将内在维度与低维任务表征和基于压缩的泛化边界联系起来,以提供基于内在维度的,与完全参数数量无关的泛化边界。
论文 3:Mind Your Outliers! Investigating the Negative Impact of Outliers on Active Learning for Visual Question Answering

作者:Siddharth Karamcheti、Ranjay Krishna、Li Fei-Fei、Christopher Manning
机构:斯坦福大学
目前,这篇论文的 PDF 和网站还未公开,之后将持续关注。
论文 4:Neural Machine Translation with Monolingual Translation Memory

作者:Deng Cai、Yan Wang、Huayang Li、Wai Lam、Lemao Liu
机构:香港中文大学、腾讯 AI Lab
论文地址:https://arxiv.org/pdf/2105.11269.pdf
论文摘要:先前的研究证明翻译记忆 (TM) 可以提高神经机器翻译 (NMT) 的性能。与使用双语语料库作为 TM 并采用源端相似性搜索进行记忆检索的现有工作相比,该研究提出了一种新框架,该框架使用单语记忆并以跨语言方式执行可学习的记忆检索,该框架具有独特的优势。首先,跨语言记忆检索器允许大量的单语数据成为 TM。第二,记忆检索器和 NMT 模型可以为最终的翻译目标进行联合优化。实验表明,该方法得到了显著的改进。值得注意的是,它甚至优于使用双语 TM 的「TM-augmented NMT」基线方法。由于能够利用单语数据,该研究还证明了所提模型在低资源和领域适应场景中的有效性。
论文 5:Scientific Credibility of Machine Translation Research: A Meta-Evaluation of 769 Papers

作者:Benjamin Marie、Atsushi Fujita、Raphael Rubino
机构:NICT(日本)
论文地址:https://arxiv.org/pdf/2106.15195.pdf
论文摘要:本文提出了首个大规模机器翻译 (MT) 元评估(metaevaluation)。该研究对 2010 年至 2020 年发表的 769 篇研究论文进行了机器翻译评估。研究表明,MT 自动评估的实践在过去的十年中发生了巨大的变化,并遵循相关的趋势。越来越多的 MT 评估仅依靠 BLEU 得分之间的差异得出结论,而不进行任何统计意义测试或人为评价,而至少有 108 个指标声称优于 BLEU。在最近的论文中,MT 评估倾向于复制和比较以前工作中的自动度量得分,以声称一种方法或算法的优越性,而没有确认使用过完全相同的训练、验证和测试数据,度量得分不具有可比性。此外,报告标准化度量得分的工具还远未被 MT 社区广泛采用。在展示了这些缺陷累积导致可疑的评估后,该研究提出了一个准则,以鼓励更好的自动 MT 评估以及一个简单的元评估得分方法来评估其可信度。
论文 6:UnNatural Language Inference

作者:Koustuv Sinha、Prasanna Parthasarathi、Joelle Pineau、Adina Williams
机构:麦吉尔大学、MILA、FAIR
论文地址:https://arxiv.org/pdf/2101.00010.pdf
GitHub 地址:https://github.com/facebookresearch/unlu
论文摘要:近期基于 Transformer 的自然语言理解研究表明,这些大规模预训练 SOTA 模型似乎能够在某种程度上理解类人的语法。在这篇论文中,研究者提供了一些新的证据,从更复杂的维度阐释了这一问题。他们发现当前的自然语言推理 SOTA 模型能够给重新排列的示例打上与此前相同的标签,也就是说,它们在很大程度上对随机的词序排列具有不变性。为了度量这个问题的严重性,研究者提出了一套度量方法,并研究了特定排列中的哪些特质使得模型具备词序不变性。例如在 MNLI 数据集中,研究者发现几乎所有 (98.7%) 的示例都至少包含一个引发黄金标签的序列。模型有时候甚至能为它们最初未能正确预测的序列分配黄金标签。在进行了全面的实验评估以后,结果表明这个问题存在于 Transformer 和基于 pre-Transformer 架构的编码器,在跨多种语言时也会出现。
ACL 获奖论文完整列表:https://2021.aclweb.org/program/accept/
参考内容:
https://www.zhihu.com/question/470224094
---------♥---------
声明:本内容来源网络,版权属于原作者
图片来源网络,不代表本公众号立场。如有侵权,联系删除
AI博士私人微信,还有少量空位


点个在看支持一下吧

以上是关于被ICLR拒,字节跳动今获最佳论文的主要内容,如果未能解决你的问题,请参考以下文章