awk命令使用经验
Posted 慢慢来
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了awk命令使用经验相关的知识,希望对你有一定的参考价值。
1.为什么要使用awk
举一个简单的例子,作为一个java开发人员,在查看日志服务器(即时保存所有线上环境的日志)上的日志的时候,由于部署了服务的服务器不止一台,当想要查找某一个特定信息的时候,由于不清楚该特定信息在那台服务器上,所以一般都是全量的搜的
比如
grep \'specialInfo\' /project/myApplication/10.*/log/info.log
或者想要追踪是否某一台服务器才产生某信息时
tail -f /project/myApplication/10.*/log/info.log |grep \'specialInfo\'
好的,现在我们能找到具体的这个信息出现时的日志了。
但是,这个日志是在哪个ip的服务器上啊....
简单的命令这时候好像不能满足这个需求。而产生线上问题的时候,往往时间都很宝贵,需要迅速定位问题的原因以及问题的影响
所以我觉得掌握一些能够快速筛选日志的手段还是很有必要的
而awk则是对日志这个具有规则的文本进行筛选的一个很好的手段
2.awk基础
awk 支持以制定的分隔符将一行文本切成多段 默认是使用空格作为分隔符 也可以通过-f命令来进行替换 例如awk -f, 则以逗号作为分隔符
分隔后的文本可以用符号来表示 $0 表示整行 $1表示分割后的第一段文本 $2表示第二段 依次类推,
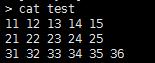
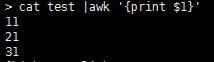
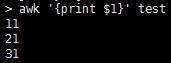
NF是代表该行的数量 那么用NF-1就能取到倒数第二列
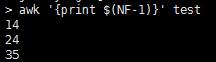
以上是最基础的,那么接下来我们想找一下第二列大于15的行的第三列 两种方式都可以起到过滤的作用
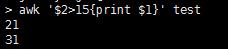

awk中 如果用BEGIN{命令1}{命令2}{命令3}End{命令4}的话 1会首先执行,2和3 会对每行输入执行,4则会最会执行
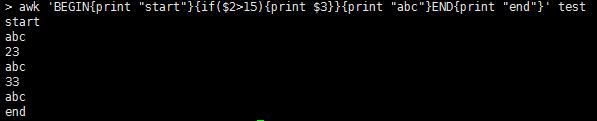
命令是以花括号来分隔的,可以进行嵌套 下面的 BEGIN{{命令1}{命令2}}

再来一个比较有用的 awk -v 可以设置变量 下面就是当第二列大于15的时候 i会增加1 每行都打印

正则表达式
~ \\regex\\ ~! \\regex\\


~是包含 ~! 是不包含
再来个统计
sum 下面利用sum数组 统计第一列都有哪几种,出现了几次

awk还有很多其他的功能,以后用到了再在这个补充,基础部分我就简单写这么一点
3.awk实际应用
有了上面的基础,解决1中的问题就很简单了
1、tail -f 多个文件时查看文件的具体路径
tail -f 多个文件时,在切换文件的时候会首先打印 ==> fileName<==
那么就利用这一点
tail -f ../project/myApp/10.*/log/cron.log |awk \'$1 ~/==>/{i=$2} {print $0"--------"i}\'
上面这行命令就是在输出中定义一个变量 i 然后当行里面有==>时,将文件路径保存在i中, 然后打印每一行的内容,后缀加上文件名,这样每当切换文件的时候i就会更新,就能够实现功能
2、cat 多个文件的时候查看文件的路径 和上面的类似,直接读内联变量FILENAME 就可以了,grep继续查找要找的内容
awk \'{i=FILENAME} {print $0"--------"i}\' ../project/facrm.ms.netease.com/10.*/log/*.log |grep find
3、查找某个文件中包含某个字符串 且不包含某个字符串 并统计这种的数量
判断第一列包含1然后所有行不包含6 统计整列出现的次数
awk \'{if($1 ~/1/){if($0 ~! /6/){sum[$0]++}}}END{for(i in sum){print i,sum[i]}}\' test
这种感觉存着比较好,之后稍微改改直接用,之后有业务场景了在补充啦
以上是关于awk命令使用经验的主要内容,如果未能解决你的问题,请参考以下文章