使用awk命令循环查找并修改后输出。
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了使用awk命令循环查找并修改后输出。相关的知识,希望对你有一定的参考价值。
文件1.dat中保存如下数据
farfaef=ferAB.CD
fefhui=fgyijiAB.CD
ferhi=AB.CD
farfaef=ferFRE.CD
fefhui=fgyijiFF.CE
ferhi=FF.CO
文件2.dat中保存了如下数据
AB.CD
FRE.CD
FF.CE
FF.CO
1.dat的这些数据中要把“=”与2.dat中间的数据全部删除了,并且在3.dat输出结果如下。
farfaef=AB.CD
fefhui=AB.CD
ferhi=AB.CD
farfaef=FRE.CD
fefhui=FF.CE
ferhi=FF.CO
(注:元素数据一列,AB.CD数据一列)
个人理解是拿2.dat的每一行,去遍历1.dat,遇到哪一行有2.dat的数据就修改后输出到3.dat
问一下,是去掉的部分都是小写字母,而保留的2.dat中的都是大写字母和"."的组合吗;如果是的话,用下面的命令去掉等号后的非大写字母和非“.”的字符就可以了,如下:
awk 'gsub(/=[^A-Z.]*/,"=");print' 1.dat > 3.dat要是还是必须用题目上说的要求,再追问吧~
按照题目的要求的话,可以用以下命令实现:
awk -F '=' 'NR==FNRa[$0]NR!=FNRfor(i in a)if(match($2,i))print $1"="i;nextprint $0' 2.dat 1.dat > 3.dat上面的命令遇到1.dat中的后面部分没有在2.dat中出现的情况则会输出1.dat中原来的内容。如果不需要输出这些没有被替换的内容,则去掉最后的print即可。
追问无法输出3.dat
追答我运行的结果,是可以的,1.dat在最后一行加入了不命中的,最后结果会输入到3.dat,运行结果如下所示:
test$ cat 1.datfarfaef=ferAB.CD
fefhui=fgyijiAB.CD
ferhi=AB.CD
farfaef=ferFRE.CD
fefhui=fgyijiFF.CE
ferhi=FF.CO
ferhi=awdkwAB.BB
test$ cat 2.dat
AB.CD
FRE.CD
FF.CE
FF.CO
test$ awk -F '=' 'NR==FNRa[$0]NR!=FNRfor(i in a)if(match($2,i))print $1"="i;nextprint' 2.dat 1.dat > 3.dat
test$ cat 3.dat
farfaef=AB.CD
fefhui=AB.CD
ferhi=AB.CD
farfaef=FRE.CD
fefhui=FF.CE
ferhi=FF.CO
ferhi=awdkwAB.BB
test$ 参考技术A awk -F"=" 'NR==FNRa[$0]=$0NR>FNRfor(i in a)if($2 ~ i)print $1"="i' 2.dat 1.dat追问
能否把没有命中2.dat任何一行的数据也一起输出呢?
追答你给我的文本中,好像都命中了吧?
追问1中有一些注释什么的,都一起被删除了,我一开始忘了写明
追答其实上边那个人写的已经符合你的需求了,我俩思路是一样的。
awk -F"=" 'NR==FNRa[$0]=$0NR>FNRfor(i in a)if($2~i)print $1"="i;nextprint'awk查找指定行指定列的数据 并输出到文件
1、打开一个文件,如下图所示。
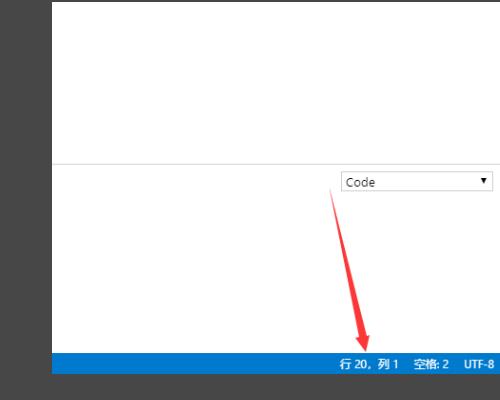
2、然后点击右下角的行,列,如下图所示。
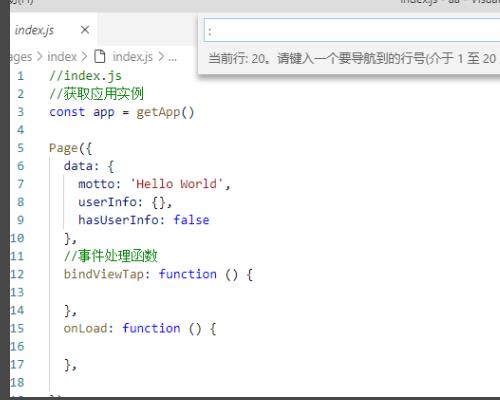
3、接下来会弹出一个界面,如下图所示。
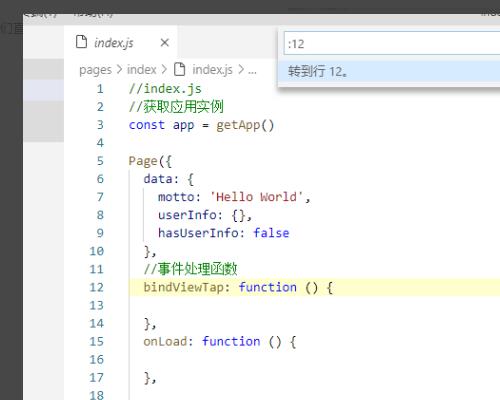
4、我们直接输入数字就可以了,如下图所示。
5、接着光标就跳转到指定的数字行了。
6、最后底下也变了,如下图所示。
1、首先awk截取指定域,在日志的处理和监控中,经常会截取指定的字符来进行后续处理。
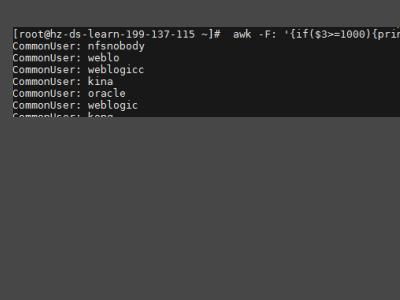
2、awk中的判断输出,awk -F: 'if($3>=1000)print "CommonUser:",$1' /etc/passwd如果uid大于等于1000,输出用户名,否者不输出,-F后边跟字符的分隔符,不加-F默认空格分隔。
3、NR 表示文件中的行号,表示当前是第几行,NF 表示文件中的当前行列的个数。
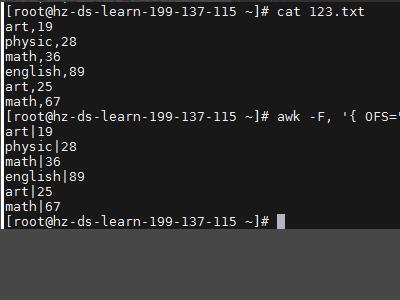
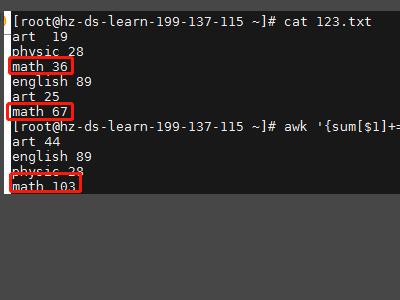
4、在 awk 中使用数学运算,经常会遇到需要统计相同key的value总和。
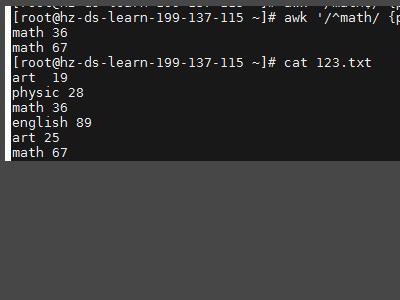
5、最后在 awk 中使用正则表达式 //中是要匹配的字符,awk '/^math/ print ' 123.txt--------匹配以math开头的行。
上面的命令中,双引号中是一个tab键,代表将指定的列用制表符隔开。input.txt是输入文件,output.txt是输出文件。上面的命令就表示将input.txt中的第1,2,5列提取出来放入output文件中。 参考技术C 获取1.txt中第二行第三列的数据,输出到2.txt。
# cat 1.txt
1 2 3
4 5 6
7 8 9
# cat 1.txt|awk 'NR==2print $3' > 2.txt
# cat 2.txt
6 参考技术D cat a.log
1 2 3
1 2 3
cat a.log | awk 'print $2' >b.log
cat b.log
2
2
以上是关于使用awk命令循环查找并修改后输出。的主要内容,如果未能解决你的问题,请参考以下文章