什么是机器学习
定义:
利用计算机从历史数据中找出规律,并把这些规律用到对未来不确定场景的决策。
从数据中寻找规律
寻找规律:概率学 统计学
统计学方法:抽样 -> 统计 -> 假设检验
随着计算机处理能力增强 -> 不需要采样
数据增加 -> 维度增加 -> 无法可视化 -> 只能数学方式表示
我们进行机器学习的一个目的就是从大量的数据中归纳出一个合适的数学模型
机器学习发展的原动力
大数据概念的出现
用数据代替专家
经济驱动,数据变现
业务系统发展的历史
基于专家经验(头脑风暴。然后交给程序员写一些判断语句)
基于统计-分纬度统计(依靠业务报表,数据仓库,olap统计)
机器学习-在线学习(实时的数据流,实时调整)
典型应用-关联规则
购物篮分析:关联规则 (一种数据挖掘算法)
联想连接 找出规律
购买物品同时买了其他什么物品。
纸尿布和啤酒的故事
经济学,捆绑销售;更大的利益
典型应用-聚类
用户细分的典型案例,全球通精准营销
把用户消费的数据利用聚类算法,可以根据用户信息,自动对用户进行分类
典型应用-朴素贝叶斯和决策树
朴素贝叶斯——垃圾邮件的识别
决策树——银行在放贷时对用户的还款能力评估
典型应用-ctr预估和协同过滤
互联网广告:ctr预估(线性逻辑回归)--用户点击率预估,百度搜索结果排序
推荐系统:协同过滤(类似购物车分析---关联规则)
典型应用自然语言处理和图像识别
自然语言处理
情感分析:根据用户的评论,分析出来该用户是我们的积极用户还是消极用户....
实体识别:将一篇文章中,主干比如人名,时间,地名提取出来
深度学习
图片识别:给一张照片,自动识别出来,是猫啊还是兔子。
更多应用:
语音识别
智慧机器人
个性化医疗
私人虚拟助理
情感分析
手势控制
人脸识别
视频内容自动识别
自动驾驶
机器实时翻译......
数据分析和机器学习的区别
数据分析:交易数据、少量数据、采样分析。对数据一致性要求严格,使用关系型数据库sql serve、mysql、oracle。
机器学习:行为数据、海量数据、全量分析。需要保证数据吞吐量,数据一致性可以打折扣,所以用NoSQL数据库
数据分析(OLAP,联机分析)-用户(数据分析师)驱动,交互式分析。
机器学习-数据+算法驱动,自动进行识别。


机器学习常见算法和分类
按数据情况:Y有没有确定
有监督学习---已知分类(标签)---分类,回归
无监督学习---未知分类(无标签)---聚类
半监督学习---强化学习,随着样本数据量上升,分类标准清晰
按算法的本质
生成模型---给出属于A/B/C类的概率,类似陪审团;
判别模型---通过给定函数判断Y/N,类似大法官裁决;
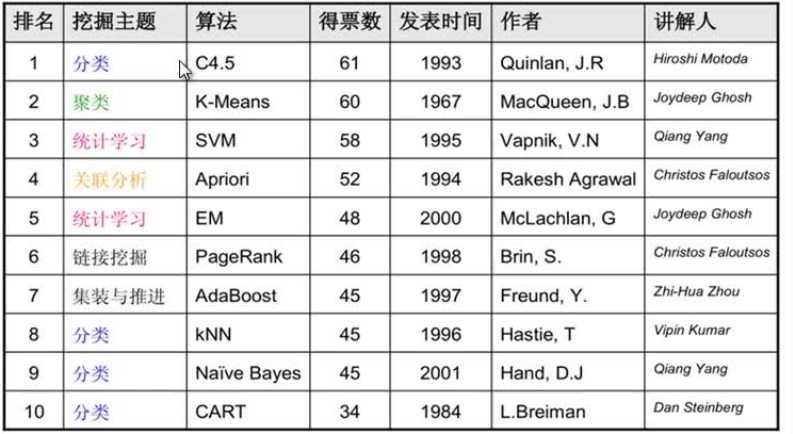
(1)ICDM
1.分类---C4.5使用决策树算法,可以解决【分类】&【回归】问题;
2.聚类---K-Means算法,属于无监督方法,解决电信用户分类问题;
3.统计学习---SVM(支持向量机)可以解决分类(主)和回归问题,有很好的表现和深厚的数学理论支撑,曾经被认为是最好的分类算法。现在光芒被【深度学习】掩盖了。有一定的数学门槛,面试中经常被问。
4.关联分析---Apriori应用于“尿片和纸尿裤”案例,最早解决了频繁项集问题。由于需要频繁访问数据库,已被淘汰。取代它的是华人开的【FP-Growth】算法。应用:电商的推荐系统,但目前有更好的替代方法。
5.统计分析---EM算法是一个算法框架,用于解决一系列问题。
6.连接挖掘---PageRank。Google使用的网页排序算法,很著名。
7.集装与推进---AdaBoosts算法,应用于人脸识别,本质为改进的决策树算法,属于有监督的分类算法。
8.分类---kNN。相对简单的分类算法,有监督。
9.分类---Naive Bayes朴素贝叶斯算法,用于识别垃圾邮件。
目前不常用的算法:Apriori和CART。
(2)著名算法
1.FP-Growth---关联分析方法Apriori的改进。
2.逻辑回归---应用非常多,多用于百度、Google搜索结果的排序。
3.RF(随机森林)、GBDT---和AdaBoost类似,都属于决策树算法。
4.推荐算法---电商标配
5.LDA---用于文本分析、自然语言处理。有一定的难度。
6.Word2Vector---google出品,耳熟能详,用于文本挖掘。
7.HMM(隐马尔科夫)、CRF(条件分析)---文本挖掘。
8.深度学习---目前最火的算法
机器学习解决问题
机器学习,预测问题(类别-离散 ,数值 -连续),聚类问题
确定目标:业务需求,数据,特征工程(数据预处理,提取特征 70%-数据的提取非常重要),数据可以直接就喂给算法,数据对模型的影响非常大,数据决定了最终的预测结果
机器学习解决问题的框架
训练模型:定义模型-产生公式(根据具体要解决的问题)、定义损失函数(预测的结果与真实的结果之间的偏差最小的函数)、优化算法(使损失函数取极小值)
模型评估:交叉验证、效果评估