条件随机场介绍—— An Introduction to Conditional Random Fields
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了条件随机场介绍—— An Introduction to Conditional Random Fields相关的知识,希望对你有一定的参考价值。
4. 推断
高效的推断算法对条件随机场的训练和序列预测都非常重要。主要有两个推断问题:第一,模型训练之后,为新的输入\\(\\mathbf{x}\\)确定最可能的标记\\(\\mathbf{y}^* = \\arg \\max_{\\mathbf{y}} p(\\mathbf{y}|\\mathbf{x})\\);第二,如第5部分所述,参数估计常要求计算标记子集上的边缘分布,例如节点的的边缘分布\\(p(y_t|\\mathbf{x})\\)和边上的边缘分布\\(p(y_t,y_{t-1}|\\mathbf{x})\\)。这两个推断问题可被看作同一基本问题上的两个不同的操作过程[1]。也就是说,若要将求边缘分布问题转化为最大化问题,仅需要将求和换作求最大化即可。
对于离散的变量,边缘分布可以通过暴力求和来计算,但是计算量会随着\\(Y\\)的增大指数增长。实际上,两个推断问题在任意图结构上都不容易,因为任何命题的可满足性问题(propositional satisfiability problem)都可以很容易地表示为一个因子图。
在线性链条件随机场中,两种推断问题都有高效、精确的动态规划方法(仅需对HMM中的动态规划方法稍作变动)。我们首先介绍这些方法——计算边缘分布的前向后向算法和计算输出序列的维特比算法(4.1节)。这两个算法是树结构图模型中信念传播算法(belief propagation algorithm)的特例。对于更复杂的模型,则需要使用近似推断。
从某种意义上来说,条件随机场的推断问题也其他图模型没什么不同,因此可以使用任何图模型的推断算法,如文献[57,79]。不过,在条件随机场中,需要记住两个问题。第一个问题,推断子程序在参数估计过程中会被重复调用(原因见5.1.1节),其计算量是指数级的,因此我们需要在计算精度和效率之间进行权衡。第二个问题,如果使用了近似推断,推断过程和参数估计过程可能会产生复杂的相互影响作用。我们在第5部分中介绍参数估计时再讨论这个问题,但是在这里也需要注意它,因为它会严重影响对推断算法的选择。
4.1 线性链条件随机场
本节,我们简要回顾HMM的标准推断算法,前向-后向算法和维特比算法,并且讨论它们在条件随机场中的应用。关于HMM中的这些算法参见综述文献Rabiner[111]。这两个算法都是4.2.2节中的信念传播算法的特例。我们对线性链算法进行深入分析,一方面使得下文的分析更具体,另一方面它们在实际中的确非常有用。
首先,我们介绍简化前向-后向迭代算法中所用的符号。HMM可被看作一个因子图\\(p(\\mathbf{y},\\mathbf{x})=\\prod_t \\Psi_t(y_t,y_{t-1},x_t)\\),其中\\(Z=1\\),因子定义为:
\\[
\\Psi_t(j,i,x)\\overset{\\text{def}}{=}p(y_t=j | y_{t-1}=i)p(x_t=x|y_t=j).
\\tag{4.1}
\\]
如果HMM被看作加权有限状态机(weighted finite state machine),那么\\(\\Psi_t(j,i,x)\\)为当前观测为\\(x\\)时状态\\(i\\)向状态\\(j\\)转移的权值。
现在我们回顾HMM的前向算法,用于计算观测概率\\(p(\\mathbf{x})\\)。前向-后向算法背后的思想是首先利用下面的分配律重写朴素假设\\(p(\\mathbf{x})=\\sum_{\\mathbf{y}}p(\\mathbf{x},\\mathbf{y})\\):
\\[
\\begin{align}
p(\\mathbf{x})&=\\sum_{\\mathbf{y}}\\prod_{t=1}^T \\Psi_t(y_t,y_{t-1},x_t) \\tag{4.2} \\&= \\sum_{y_T}\\left\\{ \\sum_{y_{T-1}} \\left\\{ \\Psi_T(y_T, y_{T-1}, x_T) \\sum_{y_{T-2}}\\left\\{ \\Psi_{T-1}(y_{T-1},y_{T-2},x_{T-1}) \\sum_{y_{T-3}} \\cdots \\right\\}\\right\\}\\right\\} \\tag{4.3}
\\end{align}
\\]
原文式中没有花括号
观察上式,可知式中的每个求和都会被外部的求和使用多次,因此若能将内部求和结果保存下来将能够节省指数级的计算量。
于是,定义前向变量\\(\\alpha_t\\)为长度为\\(M\\)的向量(\\(M\\)为状态的数量),用于表示式(4.3)内部的求和。定义为:
\\[
\\begin{align}
\\alpha_t(j) & \\overset{\\text{def}}{=} p(\\mathbf{x}_{\\langle 1 \\dots t \\rangle}, y_t = j) \\tag{4.4} \\&= \\sum_{\\mathbf{y}_{\\langle 1 \\dots t-1\\rangle}} \\Psi_t(j,y_{t-1}, x_t) \\prod_{t‘=1}^{t-1}\\Psi_{t‘}(y_{t‘}, y_{t‘-1}, x_{t‘}), \\tag{4.5}
\\end{align}
\\]
其中,\\(\\mathbf{y}_{\\langle 1\\dots t-1 \\rangle}\\)上的求和范围为随机变量\\(y_1,y_2,\\dots,y_{t-1}\\)上的所有取值。\\(\\alpha\\)的值可以用迭代方式求解
\\[
\\alpha_t(j)=\\sum_{i\\in S} \\Psi_t(j,i,x_t)\\alpha_{t-1}(i),
\\tag{4.6}
\\]
初始值为\\(\\alpha_1(j)=\\Psi_1(j,y_0,x_1)\\)。(回想式(2.10),\\(y_0\\)为HMM中的初始状态)。于是,\\(p(\\mathbf{x})=\\sum_{y_T} \\alpha_T(y_T)\\)。将式(4.6)代入并递归替换,可得到式(4.3)。数学归纳法可给出严格的证明。
反向递归过程基本一样,区别在于按相反的顺序处理式(4.3)中的求和。定义
\\[
\\begin{align}
\\beta_t(i) &\\overset{\\text{def}}{=}p(\\mathbf{x}_{\\langle t+1 \\dots T\\rangle}|y_t=i) \\tag{4.7}\\&= \\sum_{\\mathbf{y}_{\\langle t+1\\dots T\\rangle}} \\prod_{t‘=t+1}^T \\Psi_{t‘}(y_{t‘}, y_{t‘-1}, x_{t‘}), \\tag{4.8}
\\end{align}
\\]
迭代公式
\\[
\\beta_t(i)=\\sum_{j \\in S} \\Psi_{t+1}(j,i,x_{t+1})\\beta_{t+1}(j),
\\tag{4.9}
\\]
其中初始值\\(\\beta_T(i)=1\\)。与前向过程类似,也可以利用后向变量计算\\(p(\\mathbf{x})=\\beta_0(y_0)\\overset{\\text{def}}{=}\\sum_{y_1}\\Psi_1(y_1,y_0,x_1)\\beta_1(y_1)\\)。
为了计算边缘分布\\(p(y_{t-1},y_t|\\mathbf{x})\\)(在参数估计中有重要应用),需要将前向迭代和后向迭代相结合。可以从概率的视角去分析,也可以从因子分解的角度去分析。首先,从概率的角度
\\[
\\begin{align}
p(y_{t-1},y_t|\\mathbf{x}) & = \\frac{ p(\\mathbf{x}|y_{t-1},y_t)p(y_{t-1},y_t) }{p(\\mathbf{x})} \\tag{4.10} \\&= \\frac{p(\\mathbf{x}_{\\langle 1 \\dots t-1 \\rangle}, y_{t-1}) p(y_t|y_{t-1}) p(x_t|y_t) p(\\mathbf{x}_{\\langle t+1 \\dots T \\rangle} | y_t) }{p(\\mathbf{x})} \\tag{4.11} \\&= \\frac{1}{p(\\mathbf{x})} \\alpha_{t-1}(y_{t-1}) \\Psi_t(y_t, y_{t-1},x_t)\\beta_t(y_t), \\tag{4.12}
\\end{align}
\\]
其中,第二行利用了在给定\\(y_{t-1}, y_t\\)的条件下, \\(\\mathbf{x}_{\\langle 1 \\dots t-1 \\rangle}\\)与\\(\\mathbf{x}_{\\langle t+1 \\dots T \\rangle}\\)以及\\(x_t\\)相互独立的事实。
注:$p(\\mathbf{x}|y_{t-1},y_t) =p(\\mathbf{x}{\\langle 1 \\dots t-1 \\rangle}|y{t-1},y_t)p(x_t|y_{t-1},y_t)p(\\mathbf{x}{\\langle t+1 \\dots T \\rangle}|y{t-1},y_t) $,由于马尔可夫假设及输出仅依赖于当前状态的假设,于是有如下三式成立:
\\[ \\begin{align} p(\\mathbf{x}_{\\langle 1 \\dots t-1 \\rangle}|y_{t-1},y_t)&=p(\\mathbf{x}_{\\langle 1 \\dots t-1 \\rangle}|y_{t-1}) = p(\\mathbf{x}_{\\langle 1 \\dots t-1 \\rangle},y_{t-1})\\frac{1}{p(y_{t-1})} \\p(x_t|y_{t-1},y_t)&=p(x_t|y_t) \\p(\\mathbf{x}_{\\langle t+1 \\dots T \\rangle}|y_{t-1},y_t) &=p(\\mathbf{x}_{\\langle t+1 \\dots T\\rangle}|y_t) \\end{align} \\]
代入式(4.10)即可得到式(4.11)。
等价地,从因子分解的角度,应用分配率,可得
\\[
\\begin{align}
p(y_{t-1},y_t|\\mathbf{x}) = & \\frac{1}{p(\\mathbf{x})} \\Psi_t(y_t,y_{t-1},x_t) \\times
\\left( \\sum_{\\mathbf{y}_{\\langle 1 \\dots t-2 \\rangle}} \\prod_{t‘=1}^{t-1} \\Psi_{t‘}(y_{t‘}, y_{t‘-1},x_{t‘}) \\right) \\& \\times \\left( \\sum_{\\mathbf{y}_{\\langle t+1 \\dots T \\rangle}} \\prod_{t‘=t+1}^T \\Psi_{t‘}(y_{t‘}, y_{t‘-1},x_{t‘}) \\right).
\\end{align}
\\tag{4.13}
\\]
利用\\(\\alpha\\)和\\(\\beta\\)的定义替换,可以得到同样的结果,即
\\[
p(y_{t-1},y_t|\\mathbf{x})=\\frac{1}{p(\\mathbf{x})} \\alpha_{t-1}(y_{t-1}) \\Psi_t(y_t, y_{t-1},x_t)\\beta_t(y_t).
\\tag{4.14}
\\]
因子\\(1/p(\\mathbf{x})\\)为分布的归一化常量。可以利用\\(p(\\mathbf{x})=\\beta_0(y_0)\\)或者\\(p(\\mathbf{x})=\\sum_{i\\in S}\\alpha_T(i)\\)求得。
综合上述分析,前向-后向算法过程为:首先利用式(4.6)计算\\(\\alpha_t\\),然后利用式(4.9)计算\\(\\beta_t\\),接下来利用式(4.14)计算边缘分布。
最后,为了确定最可能的状态序列\\(\\mathbf{y}^*=\\arg \\max_{\\mathbf{y}}p(\\mathbf{y}|\\mathbf{x})\\),我们将式(4.3)中所有的求和换为求最大值。于是,很容易理解,在式(4.3)中利用的技巧依旧有效。这就是维特比迭代。类假于前向变量\\(\\alpha\\),定义
\\[
\\delta_t(j) \\overset{\\text{def}}{=} \\underset{\\mathbf{y}_{\\langle 1\\dots t-1\\rangle}}{\\max} \\Psi_t(j, y_{t-1}, x_t) \\prod _{t‘=1}^{t-1} \\Psi_{t‘}(y_{t‘}, y_{t‘-1},x_{t‘}).
\\tag{4.15}
\\]
同样,也可以采用迭代方法计算
\\[
\\delta_t(j) =\\max_{i\\in S} \\Psi_t(j,i,x_t) \\delta_{t-1}(i).
\\tag{4.16}
\\]
一旦所有的\\(\\delta\\)都计算完毕,最可能的状态序列通过回溯来确定
\\[
\\begin{align}
y_T^* &=\\arg \\max_{i\\in S} \\delta_T(i) \\y_t^* &=\\arg \\max_{i \\in S} \\Psi_t(y_{t+1}^*, i, x_{t+1}) \\delta_t(i) \\qquad \\text{for} \\ t < T
\\end{align}
\\]
\\(\\delta_t\\)和\\(y_t^*\\)的迭代过程,称为__维特比算法__。
前向-后向算法和维特比算法可以直接推广至线性链条件随机场,与HMM基本一致,仅转移权重\\(\\Psi_t(j,i,x_t)\\)的定义不同。式(2.18)的条件随机场可写为:
\\[
p(\\mathbf{y}|\\mathbf{x})=\\frac{1}{Z(\\mathbf{x})} \\prod_{t=1}^T \\Psi_t(y_t,y_{t-1},\\mathbf{x}_t),
\\tag{4.17}
\\]
其中,
\\[
\\Psi_t(y_t,y_{t-1},\\mathbf{x}_t) =\\exp \\left\\{ \\sum_k \\theta_k f_k(y_t,y_{t-1}, \\mathbf{x}_t)\\right\\}.
\\tag{4.18}
\\]
利用该定义,前向迭代(4.6)、后代迭代(4.9),以及维特比迭代(4.16)可以不加改变直接用于线性链条件随机场。只是其含义解释起来稍有区别。在条件随机场中,\\(\\alpha_t(j)=p(\\mathbf{x}_{\\langle 1\\dots t \\rangle}, y_t=j)\\)不再有HMM中那样的概率解释。需要从因子分解的角度来定义变量\\(\\alpha\\)、\\(\\beta\\)和\\(\\delta\\),即式(4.5)、式(4.8)和式(4.15)。此外,前向-后向迭代中的\\(p(\\mathbf{x})\\)需替换为\\(Z(\\mathbf{x})\\),即\\(Z(\\mathbf{x})=\\beta_0(y_0)\\), \\(Z(\\mathbf{x})=\\sum_{i \\in S} \\alpha_T(i)\\) 。
对于边缘分布,将式(4.14)中的\\(p(\\mathbf{x})\\)替换为\\(Z(\\mathbf{x})\\)依旧成立
\\[
\\begin{align}
p(y_{t-1},y_t|\\mathbf{x})&=\\frac{1}{Z({\\mathbf{x})}} \\alpha_{t-1}(y_{t-1}) \\Psi_t(y_t,y_{t-1},\\mathbf{x}_t) \\beta_t(y_t). \\tag{4.19} \\p(y_t|\\mathbf{x}) &= \\frac{1}{Z(\\mathbf{x})} \\alpha_t(y_t) \\beta_t(y_t). \\tag{4.20}
\\end{align}
\\]
另外还有三个特殊的推断任务也可以通过直接推广HMM的算法完成。第一,从后验概率\\(p(\\mathbf{y}|\\mathbf{x})\\)中独立对\\(\\mathbf{y}\\)取样,可以利用前向算法与后向取样相结合,与HMM完全一样。第二,找到前\\(k\\)个最可能的序列而不仅是可能性最大的序列\\(\\arg \\max_{\\mathbf{y}} p(\\mathbf{y}|\\mathbf{x})\\),也可以利用HMM的算法[129]。第三,有时候需要计算下标为\\(S \\subset [1,2,\\dots, T]\\)的节点集合(可能不连续)上的边缘概率\\(p(\\mathbf{y}_S|\\mathbf{x})\\)。例如,要度量模型根据输入片段预测相应标记的信度。该边缘概率可以直接利用前向后向相结合的方法高效计算,详细内容参见Culotta和McCallum[30]。
4.2 图模型上的推断
对于任意结构图模型,有多种精确推断算法。尽管这些算法在最差情况下计算量是指数级的,但是在实际应用中大部分情况下还是比较有效的。最著名的精确算法是连接树算法(junction tree algorithm),它不断将变量分组直到图变成一颗树。一旦构建好一个等价树,其边缘分布即可使用针对树的精确算法来计算。不过,对某些复杂的图,连接树算法会需形成很大的簇,这也是最坏情况下其计算量为指数级的原因。精确推断的详细内容参见Koller和Friedman[57]。
由于精确推断的比较复杂,因此很多研究关注近似推断算法。其中有两类近似推断算法获得了比较多的关注:蒙特卡罗算法(Monte Carlo Algorithms)和__变分算法__(Variational Algorithms)。蒙特卡罗算法是一种随机算法,它试图从目标分布中近似地生成样本。变分算法通过寻找一个与复杂边缘分布非常接近的较简单的近似分布,将推断问题转换成一个寻找该近似分布的优化问题。一般情况下,蒙特卡罗法在取样时间足够长的情况下是无偏的。而变分算法尽管速度要快得多,但却是有偏的。原因是近似过程中产生的固有的误差源,而且其影响也很难通过增加计算时间降低。尽管如此,变分算法对条件随机场来说非常有用,因为参数估计过程中要求大量运行推断算法,快速推断过程对高效的训练至关重要。关于MCMC(马尔可夫链蒙特卡罗)的详细内容请参考Robert和Casella[116],关于变分方法请参考Wainwright和Jordan[150]。
本部分内容不仅能用于条件随机场,而且能用于任意可根据因子图进行因子分解的分布,无论是联合分布\\(p(\\mathbf{y})\\)还是条件分布\\(p(\\mathbf{y}|\\mathbf{x})\\)(如条件随机场)。为了强调这一点,同时简化符号标记,在下面的分析中我们暂时忽略对\\(\\mathbf{x}\\)的依赖,仅讨论因子图\\(G=(V,F)\\)对应的联合分布\\(p(\\mathbf{y})\\)的推断,即
\\[
p(\\mathbf{y})=Z^{-1}\\prod_{a\\in F} \\Psi_a(\\mathbf{y}_a).
\\]
若要推广至条件随机场,仅需简单地将上式中的\\(\\Psi_a(\\mathbf{y}_a)\\)替换为\\(\\Psi_a(\\mathbf{y}_a,\\mathbf{x}_a)\\),并且将\\(Z\\)和\\(p(\\mathbf{y})\\)修改为依赖于\\(\\mathbf{x}\\)的条件概率形式。这种改变不仅从符号表示上有效,而且在实现设计上也是行得通的。推断算法可以实现为能够处理一般因子图的形式,推断过程不用关心它所处理的是无向的联合分布\\(p(\\mathbf{y})\\)、条件随机场\\(p(\\mathbf{y}|\\mathbf{x})\\),乃至有向图模型。
本节其余的部分中给出两个近似算法:蒙特卡罗算法和变分算法。关于近似算法有非常多的研究,由于空间所限不能在这里一一介绍。相反,我们的目的是突出条件随机场近似算法的共性问题。本节我们仅关注于推断算法本身,第5部分将会讨论它们在条件随机场中的应用。
4.2.1 马尔可夫链蒙特卡罗
目前,复杂模型中最常用的蒙特卡罗法是马尔可夫链蒙特卡罗(Markov Chain Monte Carlo, MCMC)[116]。MCMC并不直接估计边缘分布\\(p(y_s)\\),而是从联合分布\\(p(\\mathbf{y})\\)中生成近似样本。MCMC方法的核心是要构建一个马尔可夫链,其状态空间与\\(Y\\)相同。当该马尔可夫链仿真运行的时间足够长时,其状态的分布接近\\(p(y_s)\\)。假设我们要近似求得函数\\(f(\\mathbf{y})\\)在分布\\(p(\\mathbf{y})\\)上的期望。给定MCMC方法中马尔可夫链的采样\\(\\mathbf{y}^1, \\mathbf{y}^2, \\dots, \\mathbf{y}^M\\),可以通过下式近似求得该期望:
\\[
\\sum_{\\mathbf{y}}p(\\mathbf{y})f(\\mathbf{y}) \\approx \\frac{1}{M}\\sum_{j=1}^M f(\\mathbf{y}^j).
\\tag{4.21}
\\]
在第5部分中,我们会使用这种方法在CRF训练过程中计算期望值。
吉布斯采样是MCMC方法的一种。在算法的每次迭代中,样本的每个变量都在保持其他变量不变的情况下独立地重新采样。假设在第\\(j\\)次迭代中得到的样本为\\(\\mathbf{y}^j\\)。接下来生成下一个样本\\(\\mathbf{y}^{j+1}\\),
- (1)令\\(\\mathbf{y}^{j+1} \\leftarrow \\mathbf{y}^j\\).
- (2)对于每个\\(s\\in V\\),对\\(Y_s\\)重新采样。从分布\\(p(y_s|\\mathbf{y}_{\\backslash s},\\mathbf{x})\\)中采样得到\\(\\mathbf{y}_s^{j+1}\\).
- (3)返回结果\\(\\mathbf{y}_s^{j+1}\\)。
注意,\\(\\mathbf{y}_{\\backslash s}\\)为\\(\\mathbf{y}\\)中除\\(y_s\\)之外其余所有分量所构成的向量。而在2.1.1节中,求和符号\\(\\sum_{\\mathbf{y}\\backslash y_s}\\)的含义是,对变量\\(Y_s\\)的值等于\\(y_s\\)的所有\\(\\mathbf{y}\\)求和,注意不要混淆。
上述采样过程定义了一个马尔可夫链,可以用于近似求解式(4.21)的期望。在一般因子图中,条件概率由下式计算
\\[
p(y_s|\\mathbf{y}_{\\backslash s}) = \\kappa \\prod_{a\\in F}\\Psi_a(\\mathbf{y}_a),
\\tag{4.22}
\\]
其中,\\(\\kappa\\)为归一化常量。(在下文中,\\(\\kappa\\)表示一般归一化常量,它在不同式子中形式可能不同)。式(4.22)中归一化常量\\(\\kappa\\)的计算要比联合分布\\(p(\\mathbf{y}|\\mathbf{x})\\)中要容易得多,因为计算\\(\\kappa\\)仅需对所有\\(y_s\\)的可能取值求和,而不必对整个向量\\(\\mathbf{y}\\)求和。
吉布斯采样主要的优点是实现简单。实际上,像BUGS这样的软件包就可以输入一个图模型自动地生成相应的吉布斯采样[78]样本。它的主要缺点,是\\(p(\\mathbf{y})\\)中有强依赖关系的情况下性能较差,而序列数据正是这种情况。这里,“性能较差”是指马尔可夫链需要迭代很多次才能到达稳定的分布\\(p(\\mathbf{y})\\)。
关于MCMC算法的文献很多。Robert和Casella[116]的书对其进行了综述。然而,MCMC算法在条件随机场中使用不多。或许是因为我们在前边提到的缺点。在利用极大似然估计法进行参数估计时,边缘分布计算的进行次数很多。最直接的情况下,梯度下降算法过程中访问的每个参数配置中的每个训练实例都需要运行MCMC算法。由于MCMC链需要数千次迭代才能收敛,以致于计算量大到无法接受。不过,也有办法解决这个问题,比如不必要求MCMC链一直运行到收敛(参见5.4.3节)。
4.2.2 信念传播
本部分介绍一种重要的变分推断算法——信念传播(Belief Propagation, BP)算法。BP算法是线性链条件随机场中精确推断算法的直接推广,这点很有意思。
假设因子图\\(G=(V,F)\\)是树状结构的,需要计算其中的变量\\(Y_s\\)的边缘分布。BP算法的思想是,\\(Y_s\\)相邻的因子以__消息__(message)乘积的形式对其边缘分布产生作用。由于因子图为树状结构,因此每个消息都可以独立地计算。更正式地,对于每个下标为\\(a \\in N(s)\\)的因子,记\\(G_a=(V_a,F_a)\\)为包含\\(Y_s\\)、\\(\\Psi_a\\)以及\\(G\\)中\\(\\Psi_a\\)的全部上游节点(upstream)所组成的子图。这里,上游节点(upstream)的含义是\\(V_a\\)包含了被\\(\\Psi_a\\)从\\(Y_s\\)分割下来的所有节点,\\(F_a\\)则包含了被\\(\\Psi_a\\)从\\(Y_s\\)分割下来的所有因子,如图4.1所示。由于\\(G\\)是树状结构的,因此所有集合\\(V_a \\backslash Y_s \\ \\big(a\\in N(s)\\big)\\)之间没有交集,因子集合\\(F_a\\)之间同样也没有交集。这意味着,可以将求解边缘分布的求和运算分解为多个独立子问题之积:
\\[
\\begin{align}
p(y_s) & \\propto \\sum_{\\mathbf{y}\\backslash y_s} \\prod_{a\\in F} \\Psi_a(\\mathbf{y}_a) \\tag{4.23} \\&= \\sum_{\\mathbf{y}\\backslash y_s} \\prod_{a\\in N(s)} \\prod_{\\Psi_b \\in F_a} \\Psi_b(\\mathbf{y}_b) \\tag{4.24} \\&= \\prod_{a\\in N(s)} \\sum_{\\mathbf{y}_{V_a} \\backslash y_s} \\prod_{\\Psi_b \\in F_a} \\Psi_b(\\mathbf{y}_b) \\tag{4.25}
\\end{align}
\\]
注意:上式中,求和符号都是为了求相应变量\\(Y_s\\)的边缘分布。其核心思想是,将各待求和部分的公因子提取到求和符号之外。
尽管式中的符号没有明确标出,但要注意变量\\(y_s\\)包含在所有的\\(y_a\\)中,式(4.25)的两侧都包含了\\(y_s\\)。
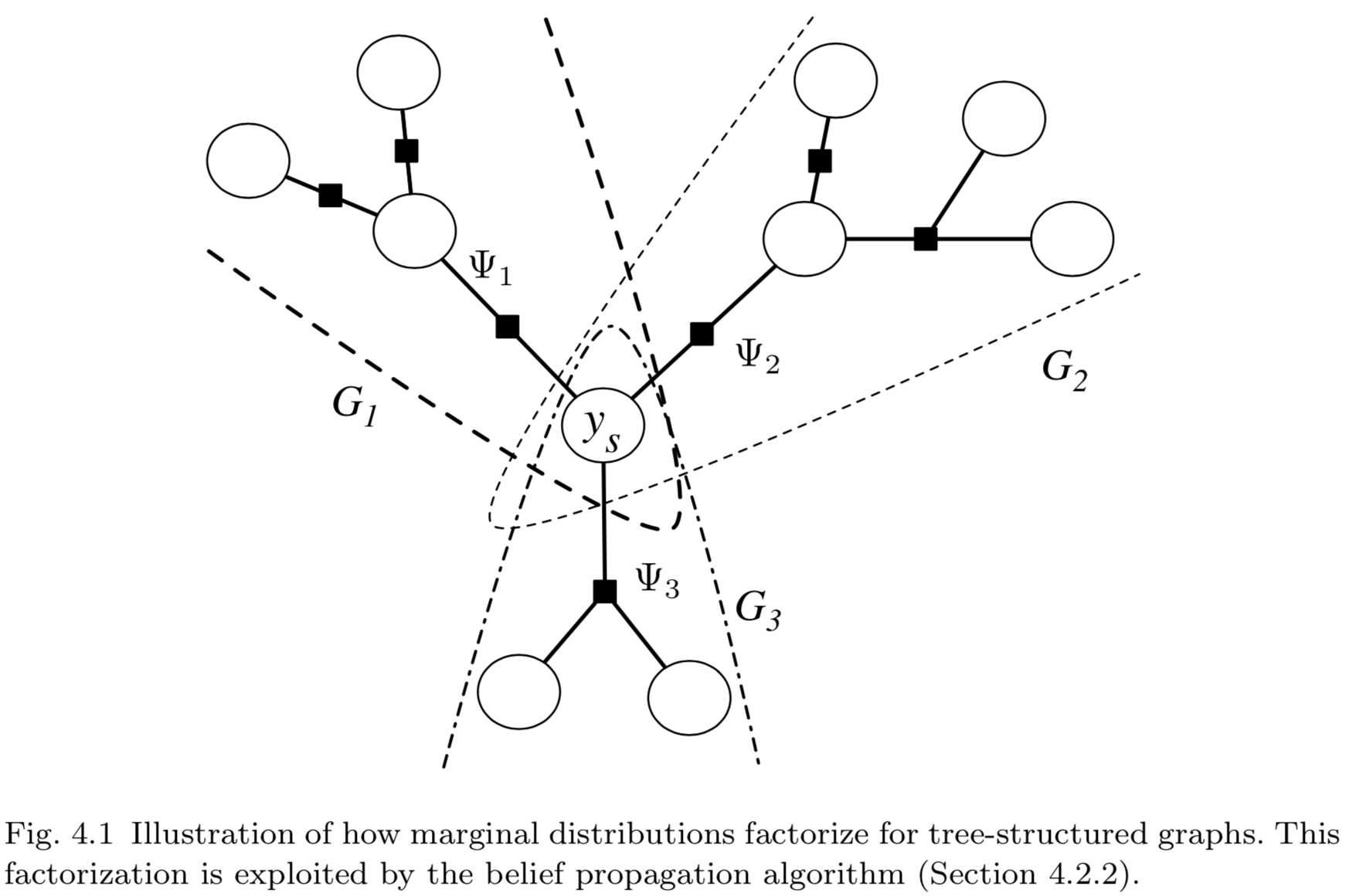
将式(4.25)中的每个成分记为\\(m_{as}\\),
\\[
m_{as}(y_s)=\\sum_{\\mathbf{y}_{V_a}\\backslash y_s} \\prod_{\\Psi_b\\in F_a} \\Psi_b(\\mathbf{y}_b).
\\tag{4.26}
\\]
每个\\(m_{as}\\)只是变量\\(y_s\\)在子图\\(G_a\\)中的边缘分布。在整个图\\(G\\)中,变量\\(y_s\\)的边缘分布为所有子图中边缘分布的乘积。我们可以将每个\\(m_{as}(y_s)\\)比喻为因子\\(a\\)发给变量\\(Y_s\\)的消息(message),该消息反应了\\(a\\)的上游(变量和因子)对变量\\(Y_s\\)边缘分布的影响。类似地,我们可也可以将变量发送至因子的消息定义为
\\[
m_{sa}(y_s)=\\sum_{\\mathbf{y}_{V_s}} \\prod_{\\Psi_b\\in F_s} \\Psi_b(\\mathbf{y}_b).
\\tag{4.27}
\\]
于是,根据式(4.25),可知边缘分布\\(p(y_s)\\)与\\(Y_s\\)接收到的消息之积成正比。类似地,因子的边缘分布为
\\[
p(\\mathbf{y}_a) \\propto \\Phi_a(\\mathbf{y}_a) \\prod_{s\\in N(a)}m_{sa}(\\mathbf{y}_a).
\\tag{4.28}
\\]
若仅根据式(4.26)计算网络中的消息是不可行的,因为还需要对所有的\\(y_{V_a}\\)求和,而\\(V_a\\)也可能非常大。幸运地,消息可以通过对局部求和进行迭代递归的方式计算。迭代公式为
\\[
\\begin{align}
m_{as}(y_s)&=\\sum_{\\mathbf{y}_a \\backslash y_s} \\Psi_a(\\mathbf{y}_a)\\prod_{t\\in a \\backslash s}m_{ta}(y_t)\\m_{sa}(y_s)&=\\prod_{b\\in N(s)\\backslash a} m_{bs}(y_s).
\\end{align}
\\tag{4.29}
\\]
通过不断的重复替换可看出,这个递归过程与\\(m\\)的显式定义一致,可以用归纳法来证明。在树状网络中,通过合理的安排,首先从根结点开始发送消息,将前项消息的计算总是放在依赖于它们的消息计算之前。这就是信念传播算法[103]。
除了计算单个变量的边缘分布,有时候我们还需要计算因子的边缘分布\\(p(\\mathbf{y}_a)\\),以及给定取值\\(\\mathbf{y}\\)的联合概率\\(p(\\mathbf{y})\\)。(回想前文所述,后者的计算很困难,因为要计算配分函数\\(\\log Z\\))。首先,为了计算因子的边缘分布,我们可以利用与单变量边缘分布同样的分解方法,可得到
\\[
p(\\mathbf{y}_a)=\\kappa \\Psi_a(\\mathbf{y}_a)\\prod_{s\\in N(a)} m_{sa}(y_s),
\\tag{4.30}
\\]
其中\\(\\kappa\\)为归一化常数。实际上,可以利用类似的方法计算任意相连接的变量集(可能不属于同一因子)的边缘分布。不过如果变量集合过大,对\\(\\kappa\\)的计算依旧会非常困难。
BP也可以用于计算规范化常量\\(Z\\)。可以直接利用传播算法,以一种4.1节介绍的前向-后向算法的扩展的形式进行。另一方法仅从算法最终得到的近似边缘分布中计算\\(Z\\)。在树状结构的分布\\(p(\\mathbf{y})\\)中,联合分布可分解为
\\[
p(\\mathbf{y})=\\prod_{s\\in V}p(y_s) \\prod_a \\frac{p(\\mathbf{y}_a)}{ \\prod_{t\\in a} p(y_t) }.
\\tag{4.31}
\\]
上式按图4.1展开,或者将图4.1中各节点和因子编号代入上式,即可明白
在线性链结构中
\\[
p(\\mathbf{y})=\\prod_{t=1}^T p(y_t)\\prod_{t=1}^T\\frac{p(y_t,y_{t-1})}{p(y_t)p(y_{t-1})},
\\tag{4.32}
\\]
上式通过调整,即为我们熟悉的形式\\(p(\\mathbf{y})=\\prod_t p(y_t|y_{t-1})\\)。利用这个特点,可以根据每个变量和每个因子的边缘分布,计算任意取值下的\\(p(\\mathbf{y})\\)。同时也求得\\(Z=p(\\mathbf{y})^{-1} \\prod_{a\\in F}\\Psi_a (\\mathbf{y}_a)\\)。
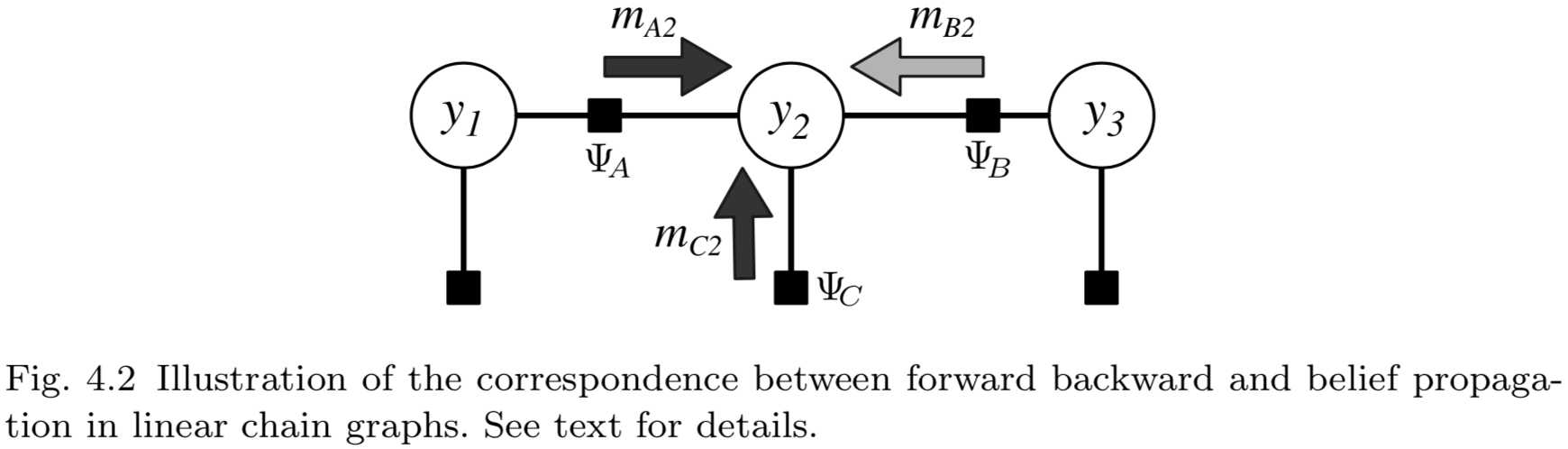
如果图\\(G\\)是树状结构的,信念传播算法能够精确的计算边缘分布。实际上,若\\(G\\)是一个线性链,BP算法退化为前向-后向算法(4.1节)。要理解这点,参考图4.2。该图是三节点线性链上BP消息的传递。为了看出其与前向-后向算法的一致性,4.1节中定义的前向变量\\(\\alpha_2\\)等价于消息\\(m_{A2}\\)与\\(m_{C2}\\)之积(图中的深灰色箭头)。后向变量\\(\\beta_2\\)等价于消息\\(m_{B2}\\)(浅灰色箭头)。实际上,边缘分布\\(p(\\mathbf{y}_a)\\)的分解(式4.30)是线性链情况下(式4.14)的扩展。
若\\(G\\)不是树状结构,式(4.29)的消息更新不能保证得到精确的边缘分布,甚至连算法的收敛性也不能保证。但是,依旧可以通过迭代以达到一个固定点(a fixed point)。该过程称为环路信念传播(loopy belief propagation)算法。为了强调该过程的近似性本质,我们将环路信念传播算法得到的近似边缘分布称为信念(beliefs)而不是边缘分布,标记为\\(q(y_s)\\)。
另一个问题是,在消息更新的迭代过程中如何调度计算顺序。在树状结构中,何意的调度都能收敛至正确的边缘分布,但是网络中存在环路的情况下不再如此:计算顺序不但影响环路信念传播算法的结果,而且还影响算法的收敛性。实际中表现良好的一种简单的办法是对消息更新进行随机的迭代。例如,按随机的顺序计算每个因子,通过式(4.29)接收并发送消息。不过,文献[35,135,152]提出了其他巧妙、有效的方法。
令人惊讶的是,环路BP可被看作是一种变分推断方法。其含义是,存在一个关于信念的目标函数,BP迭代过程使得该目标函数实现近似最小化。下面我们对这种解释进行简要的介绍,更详细的内容请参考[150,158]。
变分算法的一般思想为:
- (1)定义一个容易处理的近似分布族\\(\\mathcal{Q}\\),以及目标函数\\(\\mathcal{O}(q)\\ (\\text{for}\\ q\\in\\mathcal{Q} )\\)。其中的每个\\(q\\),要么是边缘分布容易计算的分布(如树状结构的分布),要么是一个近似边缘分布集合。如果是后者,这些近似边缘分布称为伪边缘分布(pseudomarginals),因为它们不必与任何\\(\\mathbf{y}\\)上的边缘分布相一致。目标函数\\(\\mathcal{O}\\)衡量\\(q\\in \\mathcal{Q}\\)对\\(p\\)的近似程度。
- (2)找到“最接近”的近似\\(q^*=\\min_{q\\in \\mathcal{Q}}\\mathcal{O}(q)\\)。
- (3)利用\\(q^*\\)作为边缘分布\\(p\\)的近似。
例如,假设\\(\\mathcal{Q}\\)为\\(\\mathbf{y}\\)上所有可能分布的集合,目标函数为
\\[
\\begin{align}
\\mathcal{O}(q) &=\\text{KL} (q||p) -\\log Z \\tag{4.33}\\&= -H(q)-\\sum_a \\sum_{\\mathbf{y}_a}q(\\mathbf{y}_a)\\log \\Psi_a(\\mathbf{y}_a), \\tag{4.34}
\\end{align}
\\]
一旦通过最小化目标函数得到了\\(q\\)的最优解\\(q^*\\),我们可以利用\\(q^*\\)的边缘分布来近似\\(p\\)的边缘分布。实际上,该变分问题在\\(q^*=q\\)时的最优值为\\(\\mathcal{O}(q^*)=-\\log Z\\)。因此,求解该变分公式等价于精确推断。若要进行近似推断,可以改变集合\\(\\mathcal{Q}\\)(例如,要求\\(q\\)是完全因子分解的),或者对目标函数\\(\\mathcal{O}\\)进行修改。例如,平均场方法添加了\\(q\\)完全因子分解的条件,即对特定\\(q_s\\)的选择【简单地讲,将\\(y_s\\)根据因子分组】,有\\(q(\\mathbf{y})=\\prod_s q_s(y_s)\\),然后找到使式(4.34)最小化的\\(q\\)。
下面,我们分析如何在变化法的背景下理解信念传播算法。在变分推断中需要做出两种近似。第一种近似,是对式(4.34)中表示熵的项\\(H(q)\\)的近似,因为使用标准方法计算\\(H(q)\\)非常困难。如果\\(q\\)为树状结构的分布,熵可以精确的写为
\\[
H_{BETHE}(q)=-\\sum_{a}\\sum_{\\mathbf{y}_a}q(\\mathbf{y}_a)\\log q(\\mathbf{y}_a) + \\sum_i \\sum_{y_i}(d_i -1)q(y_i)\\log q(y_i),
\\tag{4.35}
\\]
其中,\\(d_i\\)为\\(i\\)的度,也就是依赖于\\(y_i\\)的因子的数量。接下来,将式(4.31)所示的树状结构因子分解的联合分布代入熵的定义之中。如果\\(q\\)不是树,我们依旧将\\(H_{\\text{BETHE}}\\)作为\\(H\\)的近似来计算变分目标函数\\(\\mathcal{O}\\)。于是得到Bethe自由能(Bethe free energy):
\\[
\\mathcal{O}_\\text{BETHE}(q)=-H_\\text{BETHE}(q)-\\sum_a\\sum_{\\mathbf{y}_a}q(\\mathbf{y}_a)\\log\\Psi_a(\\mathbf{y}_a)
\\tag{4.36}
\\]
目标函数\\(\\mathcal{O}_\\text{BETHE}(q)\\)仅通过其边缘分布依赖于\\(q\\),因此我们可以在所有边缘向量的空间上优化,而不是在整个概率分布\\(q\\)上优化。具体地,每个分布\\(q\\)有一个对应的信念向量(belief vector)\\(\\mathbf{q}\\),其元素为\\(q_{a;y_a}\\)(所有的因子\\(a\\)和变量取值\\(y_a\\))和\\(q_{i;y_i}\\)(所有变量\\(i\\)及取值\\(y_i\\))。所有可能信念向量的空间称为边缘多胞形(marginal polytope)[150]。不过,对于难以处理的模型,边缘多胞形具有极其复杂的结构。这就引出了第二种利用环路BP的近似,即目标函数\\(\\mathcal{O}_\\text{BETHE}\\)在一个放松了的边缘多胞形上进行优化。这种放松要求信念仅需局部一致(locally consistent),即
\\[
\\sum_{\\mathbf{y}_a \\backslash y_i } q_a(\\mathbf{y}_a)=q_i(y_i) \\ \\ \\forall a,i \\in a.
\\tag{4.37}
\\]
作为一个技术点(technial point),如果一个假定的边缘分布集满足式(4.37),并不意味着它们是全局一致的,也就是说存在单一联合分布\\(q(\\mathbf{y})\\)满足这些边缘分布。由于同样的原因,分布\\(q_a(\\mathbf{y}_a)\\)也称为伪边缘分布。
Yedidia等[157]的研究表明,约束(4.37)下\\(\\mathcal{O}_\\text{BETHE}\\)的受限静止点是环路BP的固定点。因此,我们也可以将Bethe能\\(\\mathcal{O}_\\text{BETHE}\\)看作环路BP的固定点所要优化的目标函数。
变分角度的解释与从消息传递的角度解释相比,有着更深理解深度。从中得到的要点之一是,它展示了如何利用环路BP来近似\\(\\log Z\\)。因为我们将\\(\\min_q\\mathcal{Q}_\\text{BETHE}(q)\\)作为\\(\\min_q\\mathcal{O}(q)\\)的近似,而且已知\\(\\min_q\\mathcal{O}(q)=\\log Z\\),因此定义\\(\\log Z_\\text{BETHE}=\\min_q\\mathcal{O}_\\text{BETHE}(q)\\)为\\(\\log Z\\)的近似看来是合理的。这在5.4.2节中讨论利用BP估计条件随机场参数时很重要。
4.3 实现问题
本节讨论条件随机场实现过程中的两个重要技术问题:稀疏性和数值下溢。
第一,通常可以利用模型中的稀疏性提高推断的效率。主要涉及到两种类型的稀疏性:因子取值的稀疏性和特征的稀疏性。首先讨论因子取值,回忆在线性链情况下,每个前向更新(式4.6)和向后更新(式4.9)的计算时间复杂度为\\(O(M^2)\\),\\(M\\)为标记的数量。类似地,在任意结构条随机场中,环路BP中一对因子的更新时间复杂度也为\\(O(M^2)\\)。然而,在某些模型中可以更有效的进行推断,原因在于并非所有\\((y_t,y_{t-1})\\)上的因子都有取值,或者说因子\\(\\Psi_t(y_t,y_{t+1,\\mathbf{x}_t})\\)的取值常常是0。这种情况下,消息传递算法中可以利用稀疏矩阵运算大大降低计算量。
特征向量上取值的稀疏性也能达到提高远算效率的目的。回忆式(2.26),计算因子\\(\\Psi_c(\\mathbf{x}_c, \\mathbf{y}_c)\\)的过程中需要计算参数向量\\(\\theta_p\\)和特征向量\\(\\mathbf{f}_c=\\{f_{pk}(y_c, \\mathbf{x}_c)| \\forall p, \\forall k\\}\\)的点积。而向量\\(\\mathbf{f}_c\\)中的取值常常为0。例如,自然语言应用中常使用二值特征标识一个词。这种情况下,因子\\(\\Psi_c\\)的计算量可以利用稀疏向量大大的降低。同样,我们也可以利用稀疏性提高似然梯度(likelihood gradient)的计算效率,如第5部分所示。
相关的另一个提高前向后向计算效率的技巧,是将特定转移子集的参数绑定[24]。其作用是降低模型转移矩阵的有效大小,从而降低对标记集大小的二次依赖性(quadratic dependence)。
第二个推断算法实现的问题是如何避免数值下溢。前向-后向算法和信念传播算法中的概率,即\\(\\alpha_t\\)和\\(m_{sa}\\),取值常常非常之小,以至于计算机中数值精度不能表示(在HMM中\\(\\alpha_t\\)会随时间\\(t\\)以指数速度向0减小)。有两种标准的方法来解决这个问题。一种方法是将向量\\(\\alpha_t\\)的求和有及向量\\(\\beta_t\\)的求和调整至1(归一化),使较小的值放大。这种调整不会影响\\(Z(\\mathbf{x})\\)的计算,因为\\(Z(\\mathbf{x})=p(\\mathbf{y}‘|\\mathbf{x}‘)^{-1}\\prod_t\\big(\\Psi_t(y_t‘,y_{t+1}‘,\\mathbf{x}_t) \\big)\\)(对任意\\(\\mathbf{y}‘\\)),其中\\(p(\\mathbf{y}‘|\\mathbf{x})^{-1}\\)利用式(4.31)基于边缘分布计算。不过,Rabiner[111]提出了一种更有效的方法,该方法涉及到保存每个局部标度因子。在任何情况下,标度技巧都可被用于前向-后向算法或环路BP算法,并且不会影响最终的结果。
另一种避免数值下溢的方法是在对数域计算,即式(4.6)的前向迭代变为
\\[
\\log \\alpha_t(j)=\\bigoplus_{i\\in S} \\big( \\log \\Psi_t(j,i,x_t) + \\log \\alpha_{t-1}(i)\\big),
\\tag{4.38}
\\]
其中\\(\\oplus\\)的运算\\(a \\oplus b = \\log(e^a +e^b)\\)。最初看不出这种方法的作用,因为数值精度在计算\\(e^a\\)和\\(e^b\\)时丢失了。但\\(\\oplus\\)可用下式计算
\\[
a \\oplus b = a + \\log(1+ e^{b-a}) = b + \\log(1+e^{a-b}),
\\tag{4.39}
\\]
如果我们用较小的指数来选取恒等式的话,上式的数值稳定会更好。
初看起来归一化方法要优于对数方法,原因在于后者中\\(\\log\\)和\\(\\exp\\)的计算量达到\\(O(TM^2)\\),这带来了很大的计算开销。这种情况在HMM中的确如此,但是在条件随机场中并非如此。在条件随机场中,即便是归一化方法依旧要求调用\\(\\exp\\)函数来计算式(4.18)的\\(\\Psi_t(y_t,y_{t+1},\\mathbf{x}_t)\\)。因此无法避免对指数函数的调用。在最坏的情况下,\\(\\Psi_t\\)的计算次数达\\(TM^2\\),与归一化方法对指数的调用次数类似。不过,有些特殊情况下,归一化方法可以带来速度的提升,例如当转移特征不依赖观测时,仅有\\(M^2\\)个不同的\\(\\Psi_t\\)取值。
以上是关于条件随机场介绍—— An Introduction to Conditional Random Fields的主要内容,如果未能解决你的问题,请参考以下文章
条件随机场介绍—— An Introduction to Conditional Random Fields
条件随机场介绍—— An Introduction to Conditional Random Fields
条件随机场介绍—— An Introduction to Conditional Random Fields