重定向和管道
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了重定向和管道相关的知识,希望对你有一定的参考价值。
1.1 重定向符号
> 输出重定向到一个文件或设备 覆盖原来的文件
>! 输出重定向到一个文件或设备 强制覆盖原来的文件
>> 输出重定向到一个文件或设备 追加原来的文件
< 输入重定向到一个程序
1.2标准错误重定向符号
2> 将一个标准错误输出重定向到一个文件或设备 覆盖原来的文件 b-shell
2>> 将一个标准错误输出重定向到一个文件或设备 追加到原来的文件
2>&1 将一个标准错误输出重定向到标准输出 注释:1 可能就是代表 标准输出
>& 将一个标准错误输出重定向到一个文件或设备 覆盖原来的文件 c-shell
|& 将一个标准错误 管道 输送 到另一个命令作为输入
1.3命令重导向示例
在 bash 命令执行的过程中,主要有三种输出入的状况,分别是:
1. 标准输入;代码为 0 ;或称为 stdin ;使用的方式为 <
2. 标准输出:代码为 1 ;或称为 stdout;使用的方式为 1> (1可省略)
3. 错误输出:代码为 2 ;或称为 stderr;使用的方式为 2>
1.4为何要使用命令输出重导向
当屏幕输出的信息很重要,而且我们需要将他存下来的时候;
背景执行中的程序,不希望他干扰屏幕正常的输出结果时;
一些系统的例行命令(例如写在 /etc/crontab 中的文件)的执行结果,希望他可以存下来时;
一些执行命令,我们已经知道他可能的错误讯息,所以想以『 2> /dev/null 』将他丢掉时;
错误讯息与正确讯息需要分别输出时。
注:也支持多条命令重定向:
(cmd1;cmd2)> f
[[email protected]~]# ls he
ls: cannot access he: No such file or directory
[[email protected]~]# cat acc
张三|000001
李四|000002
[[email protected]~]# (ls he;cat acc) > f1 2>f2 #标准输出重定向到f1 标准错误重定向f2
[[email protected]~]# cat f1
张三|000001
李四|000002
[[email protected]~]# cat f2
ls: cannot access he: No such file or directory
[[email protected]~]# (ls he;cat acc) &> f3
[[email protected]~]# cat f3
ls: cannot access he: No such file or directory
张三|000001
李四|000002
[[email protected] ld.so.conf.d]#echo "alias cdrpm='cd /media/CentOS_6.9_Final/Packages'">>/root/.bashrc
[[email protected] ld.so.conf.d]#. /root/.bashrc
[[email protected] ld.so.conf.d]#cdrpm
把对的和错的都重定向到一个文件里的三种方法:
[[email protected] ~]#ls /app /err >f2 2>&1 ---比较老的写法 相当与2==1 2等同于1
[[email protected] ~]#cat f2
ls: cannot access /err: No such file or directory
/app:
fa
fb
[[email protected] ~]#ls /app /err &> f2 --常用的写法
[[email protected] ~]#cat f2
ls: cannot access /err: No such file or directory
/app:
fa
fb
[[email protected] ~]#ls /app /err >&f2
[[email protected] ~]#cat f2
ls: cannot access /err: No such file or directory
/app:
fa
fb
基本重定向示例
[test @test test]# ls -al > list.txt
#将显示的结果输出到 list.txt 文件中,若该文件以存在则予以取代!
[test @test test]# ls -al >> list.txt
#将显示的结果累加到 list.txt 文件中,该文件为累加的,旧数据保留!
[test @test test]# ls -al 1> list.txt 2> list.err
#将显示的数据,正确的输出到 list.txt 错误的数据输出到 list.err
[test @test test]# ls -al 1> list.txt 2> &1
#将显示的数据,不论正确或错误均输出到 list.txt 当中!错误与正确文件输出到同一个文件中,则必须以上面的方法来写!不能写成其它格式!
[test @test test]# ls -al 1> list.txt 2> /dev/null
#将显示的数据,正确的输出到 list.txt 错误的数据则予以丢弃! /dev/null ,可以说成是黑洞装置。为空,即不保存。
2.链接文件
【硬连接】
ln 源文件 目标文件
link 源文件 目标文件
硬连接指通过索引节点来进行连接。在Linux的文件系统中,保存在磁盘分区中的文件不管是什么类型都给它分配一个编号,称为索引节点号(Inode Index)。在Linux中,多个文件名指向同一索引节点是存在的。一般这种连接就是硬连接。硬连接的作用是允许一个文件拥有多个有效路径名,这样用户就可以建立硬连接到重要文件,以防止“误删”的功能。其原因如上所述,因为对应该目录的索引节点有一个以上的连接。只删除一个连接并不影响索引节点本身和其它的连接,只有当最后一个连接被删除后,文件的数据块及目录的连接才会被释放。也就是说,文件真正删除的条件是与之相关的所有硬连接文件均被删除。
【软连接】
另外一种连接称之为符号连接(Symbolic Link),也叫软连接。软链接文件有类似于Windows的快捷方式。它实际上是一个特殊的文件。在符号连接中,文件实际上是一个文本文件,其中包含的有另一文件的位置信息。
具体用法是:ln -s 源文件 目标文件
当 我们需要在不同的目录,用到相同的文件时,我们不需要在每一个需要的目录下都放一个必须相同的文件,我们只要在某个固定的目录,放上该文件,然后在其它的 目录下用ln命令链接(link)它就可以,不必重复的占用磁盘空间。
例如:ln -s /bin/less /usr/local/bin/less
通过实验加深理解
清单 1. 移动或重命名文件
# stat /home/harris/source/glibc-2.16.0.tar.xz
File: `/home/harris/source/glibc-2.16.0.tar.xz'
Size: 9990512 Blocks: 19520 IO Block: 4096 regular file
Device: 807h/2055d Inode: 2485677 Links: 1
Access: (0600/-rw-------) Uid: ( 1000/ harris) Gid: ( 1000/ harris)
...
...
# mv /home/harris/source/glibc-2.16.0.tar.xz /home/harris/Desktop/glibc.tar.xz
# ls -i -F /home/harris/Desktop/glibc.tar.xz
2485677 /home/harris/Desktop/glibc.tar.xz
在 Linux 系统中查看 inode 号可使用命令 stat 或者ls -i
清单 1.中使用命令 mv 移动并重命名文件 glibc-2.16.0.tar.xz,其结果不影响文件的用户数据及 inode 号,文件移动前后 inode 号均为:2485677。
为解决文件的共享使用,Linux 系统引入了两种链接:硬链接 (hard link) 与软链接(又称符号链接,即 soft link 或 symbolic link)。链接为 Linux 系统解决了文件的共享使用,还带来了隐藏文件路径、增加权限安全及节省存储等好处。若一个 inode 号对应多个文件名,则称这些文件为硬链接。换言之,硬链接就是同一个文件使用了多个别名(见 图 2.hard link 就是 file 的一个别名,他们有共同的 inode)。硬链接可由命令 link 或 ln 创建。如下是对文件 oldfile 创建硬链接。link 或者ln 命令
link oldfile newfile
ln oldfile newfile
清单 2. 软链接硬链接文件对别
[[email protected]]$ vi test.log #创建一个测试文件f1
[[email protected]]$ ln test.log test1.log #创建f1的一个硬连接文件test1.log
[[email protected]]$ ln -s test.log test2.log #创建f1的一个符号连接文件test2.log
[[email protected]]$ ls -li # -i参数显示文件的inode节点信息
908700 -rw-r--r--. 2 root root 6 Oct 7 04:11 test1.log
908700 -rw-r--r--. 2 root root 6 Oct 7 04:11 test.log
# 硬链接节点号相同,文件类型以及权限相同,硬链接数为+1=2
908695 lrwxrwxrwx. 1 root root 8 Oct 7 04:12 test2.log -> test.log
由于硬链接是有着相同 inode 号仅文件名不同的文件,因此硬链接存在以下几点特性:
文件有相同的 inode 及 data block;
只能对已存在的文件进行创建;
不能交叉文件系统进行硬链接的创建;
不能对目录进行创建,只可对文件创建;
删除一个硬链接文件并不影响其他有相同 inode 号的文件。
清单 3. 硬链接特性展示
# ls -li
total 0
// 只能对已存在的文件创建硬连接
# link old.file hard.link
link: cannot create link `hard.link' to `old.file': No such file or directory
# echo "This is an original file" > old.file
# cat old.file
This is an original file
# stat old.file
File: `old.file'
Size: 25 Blocks: 8 IO Block: 4096 regular file
Device: 807h/2055d Inode: 660650 Links: 2
Access: (0644/-rw-r--r--) Uid: ( 0/ root) Gid: ( 0/ root)
...
// 文件有相同的 inode 号以及 data block
# link old.file hard.link | ls -li
total 8
660650 -rw-r--r-- 2 root root 25 Sep 1 17:44 hard.link
660650 -rw-r--r-- 2 root root 25 Sep 1 17:44 old.file
// 不能交叉文件系统
# ln /dev/input/event5 /root/bfile.txt
ln: failed to create hard link `/root/bfile.txt' => `/dev/input/event5':
Invalid cross-device link
// 不能对目录进行创建硬连接
# mkdir -p old.dir/test
# ln old.dir/ hardlink.dir
ln: `old.dir/': hard link not allowed for directory
# ls -iF
660650 hard.link 657948 old.dir/ 660650 old.file
文件 old.file 与 hard.link 有着相同的 inode 号:660650 及文件权限,inode 是随着文件的存在而存在,因此只有当文件存在时才可创建硬链接,即当 inode 存在且链接计数器(link count)不为 0 时。inode 号仅在各文件系统下是唯一的,当 Linux 挂载多个文件系统后将出现 inode 号重复的现象(如 清单 4.所示,文件 t3.jpg、sync 及 123.txt 并无关联,却有着相同的 inode 号),因此硬链接创建时不可跨文件系统。设备文件目录 /dev 使用的文件系统是 devtmpfs,而 /root(与根目录 / 一致)使用的是磁盘文件系统 ext4。清单 4.展示了使用命令 df 查看当前系统中挂载的文件系统类型、各文件系统 inode 使用情况及文件系统挂载点。
清单 4. 查找有相同 inode 号的文件
# df -i --print-type
Filesystem Type Inodes IUsed IFree IUse% Mounted on
/dev/sda7 ext4 3147760 283483 2864277 10% /
udev devtmpfs 496088 553 495535 1% /dev
tmpfs tmpfs 499006 491 498515 1% /run
none tmpfs 499006 3 499003 1% /run/lock
none tmpfs 499006 15 498991 1% /run/shm
/dev/sda6 fuseblk 74383900 4786 74379114 1% /media/DiskE
/dev/sda8 fuseblk 29524592 19939 29504653 1% /media/DiskF
# find / -inum 1114
/media/DiskE/Pictures/t3.jpg
/media/DiskF/123.txt
/bin/sync
值得一提的是,Linux 系统存在 inode 号被用完但磁盘空间还有剩余的情况。我们创建一个 5M 大小的 ext4 类型的 mo.img 文件,并将其挂载至目录 /mnt。然后我们使用一个 shell 脚本将挂载在 /mnt 下 ext4 文件系统的 indoe 耗尽。
清单 5. 测试文件系统 inode 耗尽但仍有磁盘空间的情景
# dd if=/dev/zero of=mo.img bs=5120k count=1
# ls -lh mo.img
-rw-r--r-- 1 root root 5.0M Sep 1 17:54 mo.img
# mkfs -t ext4 -F ./mo.img
...
OS type: Linux
Block size=1024 (log=0)
Fragment size=1024 (log=0)
Stride=0 blocks, Stripe width=0 blocks
1280 inodes, 5120 blocks
256 blocks (5.00%) reserved for the super user
...
...
Writing superblocks and filesystem accounting information: done
# mount -o loop ./mo.img /mnt
# cat /mnt/inode_test.sh
#!/bin/bash
for ((i = 1; ; i++))
do
if [ $? -eq 0 ]; then
echo "This is file_$i" > file_$i
else
exit 0
fi
done
# . /inode_test.sh
./inode_test.sh: line 6: file_1269: No space left on device
# df -iT /mnt/; du -sh /mnt/
Filesystem Type Inodes IUsed IFree IUse% Mounted on
/dev/loop0 ext4 1280 1280 0 100% /mnt
1.3M /mnt/
实际中应用案例:
在一台配置较低的linux服务器的date分区内创建文件时,系统提示磁盘空间不足,系统无法创键新的目录和文件。
查找原因:
用df -h查看磁盘使用情况,如果使用达到100%,需添加磁盘。如果磁盘空间使用率空间不高。用df -i查看分区的索引节点,如果已满,占用了大量的inode。
解决方案:
1 先删除/date/cache目录中的部分文件,释放/date分区的一部分inode。
2 用软连接将空间分区/opt 中的newcache目录连接到/date/chache。使用/opt分区的inode来缓解/date分区不足的问题
[[email protected] ~]# ln -s /opt/newchache /date/cache
硬链接不能对目录创建是受限于文件系统的设计(见 清单 3.对目录创建硬链接将失败)。现 Linux 文件系统中的目录均隐藏了两个个特殊的目录:当前目录(.)与父目录(..)。查看这两个特殊目录的 inode 号可知其实这两目录就是两个硬链接(注意目录 /mnt/lost+found/ 的 inode 号)。所以任何目录的节点号至少为2
# ls -aliF /mnt/lost+found
total 44
11 drwx------ 2 root root 12288 Sep 1 17:54 ./
2 drwxr-xr-x 3 root root 31744 Sep 1 17:57 ../
# stat /mnt/lost+found/
File: `/mnt/lost+found/'
Size: 12288 Blocks: 24 IO Block: 1024 directory
Device: 700h/1792d Inode: 11 Links: 2
Access: (0700/drwx------) Uid: ( 0/ root) Gid: ( 0/ root)
Access: 2012-09-01 17:57:17.000000000 +0800
Modify: 2012-09-01 17:54:49.000000000 +0800
Change: 2012-09-01 17:54:49.000000000 +0800
Birth: -
软链接与硬链接不同,若文件用户数据块中存放的内容是另一文件的路径名的指向,则该文件就是软连接。软链接就是一个普通文件,只是数据块内容有点特殊。软链接有着自己的 inode 号以及用户数据块。因此软链接的创建与使用没有类似硬链接的诸多限制:
软链接有自己的文件属性及权限等;
可对不存在的文件或目录创建软链接;
软链接可交叉文件系统;
软链接可对文件或目录创建;
创建软链接时,链接计数 i_nlink 不会增加;
删除软链接并不影响被指向的文件,但若被指向的原文件被删除,则相关软连接被称为死链接(即 dangling link,若被指向路径文件被重新创建,死链接可恢复为正常的软链接)。
清单 6. 软链接特性展示
# ls -li
total 0
// 可对不存在的文件创建软链接
# ln -s old.file soft.link
# ls -liF
total 0
789467 lrwxrwxrwx 1 root root 8 Sep 1 18:00 soft.link -> old.file
// 由于被指向的文件不存在,此时的软链接 soft.link 就是死链接
# cat soft.link
cat: soft.link: No such file or directory
// 创建被指向的文件 old.file,soft.link 恢复成正常的软链接
# echo "This is an original file_A" >> old.file
# cat soft.link
This is an original file_A
// 对不存在的目录创建软链接
# ln -s old.dir soft.link.dir
# mkdir -p old.dir/test
# tree . -F --inodes
.
├── [ 789497] old.dir/
│ └── [ 789498] test/
├── [ 789495] old.file
├── [ 789495] soft.link -> old.file
└── [ 789497] soft.link.dir -> old.dir/
当然软链接的用户数据也可以是另一个软链接的路径,其解析过程是递归的。
但需注意:软链接创建时原文件的路径指向使用绝对路径较好。使用相对路径创建的软链接被移动后该软链接文件将成为一个死链接(如下所示的软链接 使用了相对路径,因此不宜被移动修改),因为链接数据块中记录的亦是相对路径指向。
[[email protected] ~]#ln -s ../root/f2 /app/link1---创建f2文件的软连接放到/app/link1
[[email protected] ~]#ll /app/link1 ---大小为文件名大小
lrwxrwxrwx. 1 root root 10 Jul 21 20:23 /app/link1 -> ../root/f2---创建成功
[[email protected] ~]#> /app/link1 ---重定向
[[email protected] ~]#ll f2 ---源文件被破坏
-rw-r--r--. 1 root root 0 Jul 21 20:23 f2
[[email protected] ~]#ll /app/link1
lrwxrwxrwx. 1 root root 10 Jul 21 20:23 /app/link1 -> ../root/f2
注:相对地址是相对于软连接的相对地址
链接相关命令
在 Linux 中查看当前系统已挂着的文件系统类型,除上述使用的命令 df,还可使用命令 mount 或查看文件 /proc/mounts。
# mount
/dev/sda7 on / type ext4 (rw,errors=remount-ro)
proc on /proc type proc (rw,noexec,nosuid,nodev)
sysfs on /sys type sysfs (rw,noexec,nosuid,nodev)
...
...
none on /run/shm type tmpfs (rw,nosuid,nodev)
命令 ls -li或 stat 可帮助我们区分软链接与其他文件并查看文件 inode 号,但较好的方式还是使用 find 命令,其不仅可查找某文件的软链接,还可以用于查找相同 inode 的所有硬链接。(见清单 8.) 使用命令 find 查找软链接与硬链接
// 查找在路径 /home 下的文件 data.txt 的软链接
# find /home -lname data.txt
/home/harris/debug/test2/a
// 查看路径 /home 有相同 inode 的所有硬链接
# find /home -samefile /home/harris/debug/test3/old.file
/home/harris/debug/test3/hard.link
/home/harris/debug/test3/old.file
# find /home -inum 660650
/home/harris/debug/test3/hard.link
/home/harris/debug/test3/old.file
// 列出路径 /home/harris/debug/ 下的所有软链接文件
# find /home/harris/debug/ -type l -ls
656662 0 lrwxrwxrwx 1 harris harris 1 Sep 1 14:37 /home/harris/debug/test2/b -> a
656627 0 lrwxrwxrwx 1 harris harris 8 Sep 1 14:37 /home/harris/debug/test2/a ->
data.txt
789467 0 lrwxrwxrwx 1 root root 8 Sep 1 18:00 /home/harris/debug/test/soft.link ->
old.file
789496 0 lrwxrwxrwx 1 root root 7 Sep 1 18:01
/home/harris/debug/test/soft.link.dir -> old.dir
系统根据磁盘的大小默认设定了 inode 的值(见清单 9.),如若必要,可在格式文件系统前对该值进行修改。如键入命令 mkfs -t ext4 -I 512/dev/sda4,将使磁盘设备 /dev/sda4 格式成 inode 大小是 512 字节的 ext4 文件系统。
查看系统的 inode 值
// 查看磁盘分区 /dev/sda7 上的 inode 值
# dumpe2fs -h /dev/sda7 | grep "Inode size"
dumpe2fs 1.42 (29-Nov-2011)
Inode size: 256
# tune2fs -l /dev/sda7 | grep "Inode size"
Inode size: 256
总结两种链接的区别:
由于硬链接是有着相同 inode 号仅文件名不同的文件,因此硬链接存在以下几点特性:
文件有相同的 inode 及 data block;
只能对已存在的文件进行创建;
不能交叉文件系统进行硬链接的创建;而且只有超级用户才有建立硬链接权限。
不能对目录进行创建,只可对文件创建;
删除一个硬链接文件并不影响其他有相同 inode 号的文件。
对硬链接文件进行读写和删除操作时候,结果和软链接相同。但如果我们删除硬链接文件的源文件,硬链接文件仍然存在,而且保留了愿有的内容。
这时,系统就“忘记”了它曾经是硬链接文件。而把他当成一个普通文件。
那么我们就可以这样理解:硬连接指通过索引节点来进行的连接,其作用是允许一个文件拥有多个有效路径名,能够达到误删除的作用。
其原因是因为对应的文件的索引节点有一个以上的连接。只删除一个连接并不影响索引节点本身和其它
的连接,只有当最后一个连接被删除后,文件的数据块及目录的连接才会被释放。文件才会被真正删除。
注:保存在磁盘分区中的文件不管是什么类型都给它分配一个编号,称为索引节点号(Inode Index即I节点)。
软链接没有硬链接以上的两个限制,因而现在更为广泛使用,它具有更大的灵活性,甚至可以跨越不同机器、不同网络对文件进行链接。但是软链接的缺点在于:因为链接文件包含有原文件的路径信息,所以当原文件从一个目录下移到其他目录中,再访问链接文件,系统就找不到了,而硬链接就没有这个缺陷,你想怎么移就怎么移;还有它要系统分配额外的空间用于建立新的索引节点和保存原文件的路径。
3.管道
管道命令操作符是:”|”,它仅能处理经由前面一个指令传出的正确输出信息,也就是 standard output 的信息,对于 stdandard
error 信息没有直接处理能力。然后,传递给下一个命令,作为标准的输入 standard input.
管道命令使用说明:
先看下下面图:
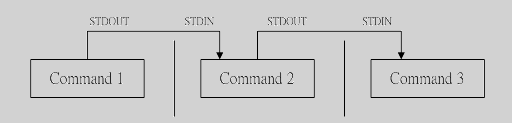
command1正确输出,作为command2的输入 然后comand2的输出作为,comand3的输入 ,comand3输出就会直接显示在屏幕上面了。
通过管道之后:comand1,comand2的正确输出不显示在屏幕上面
注意:
1、管道命令只处理前一个命令正确输出,不处理错误输出
2、管道命令右边命令,必须能够接收标准输入流命令才行。
实例:
[[email protected] shell]$ cat test.sh | grep -n 'echo' 5: echo "very good!"; 7: echo "good!"; 9: echo "pass!"; 11: echo "no pass!"; #读出test.sh文件内容,通过管道转发给grep 作为输入内容
[[email protected] shell]$ cat test.sh test1.sh | grep -n 'echo' cat: test1.sh: 没有那个文件或目录 5: echo "very good!"; 7: echo "good!"; 9: echo "pass!"; 11: echo "no pass!"; #cat test1.sh不存在,错误输出打印到屏幕,正确输出通过管道发送给grep
[[email protected] shell]$ cat test.sh test1.sh 2>/dev/null | grep -n 'echo' 5: echo "very good!"; 7: echo "good!"; 9: echo "pass!"; 11: echo "no pass!"; #将test1.sh 没有找到错误输出重定向输出给/dev/null 文件,正确输出通过管道发送给grep
[[email protected] shell]$ cat test.sh | ls catfile httprequest.txt secure test testfdread.sh testpipe.sh testsh.sh testwhile2.sh envcron.txt python sh testcase.sh testfor2.sh testselect.sh test.txt text.txt env.txt release sms testcronenv.sh testfor.sh test.sh testwhile1.sh #读取test.sh内容,通过管道发送给ls命令,由于ls 不支持标准输入,因此数据被丢弃 |
这里实例就是对上面2点注意的验证。作用接收标准输入的命令才可以用作管道右边。否则传递过程中数据会抛弃。 常用来作为接收数据管道命令有:sed,awk,cut,head,top,less,more,wc,join,sort,split 等等,都是些文本处理命令。
管道命令与重定向区别
区别是:
1、左边的命令应该有标准输出 | 右边的命令应该接受标准输入
左边的命令应该有标准输出 > 右边只能是文件
左边的命令应该需要标准输入 < 右边只能是文件
2、管道触发两个子进程执行"|"两边的程序;而重定向是在一个进程内执行
这些都是网上总结很多的,其实只要多加清楚用法,也一定有自己的一份不同描述。
实例:
#可以相互转换情况 #输入重定向
[[email protected] shell]$ cat test.sh| grep -n 'echo' 5: echo "very good!"; 7: echo "good!"; 9: echo "pass!"; 11: echo "no pass!"; #"|"管道两边都必须是shell命令
[[email protected] shell]$ grep -n 'echo' <test.sh 5: echo "very good!"; 7: echo "good!"; 9: echo "pass!"; 11: echo "no pass!"; #"重定向"符号,右边只能是文件(普通文件,文件描述符,文件设备)
[[email protected] shell]$ mail -s 'test' [email protected] <test.sh [[email protected] shell]$ cat test.sh|mail -s 'test' [email protected] #以上2个也相同,将test.sh内容发送到指定邮箱。
[[email protected] shell]$ (sed -n '1,$p'|grep -n 'echo')<test.sh 5: echo "very good!"; 7: echo "good!"; 9: echo "pass!"; 11: echo "no pass!"; #这个脚本比较有意思了。由于前面是管道,后面需要把test.sh内容重定向到 sed ,然后sed输出通过管道,输入给grep.需要将前面用"()"运算符括起来。在单括号内的命令,可以把它们看作一个象一个命令样。如果不加括号test.sh就是grep 的输入了。
#上面一个等同于这个 [[email protected] shell]$ sed -n '1,$p'<test.sh | grep -n 'echo' 5: echo "very good!"; 7: echo "good!"; 9: echo "pass!"; 11: echo "no pass!";
#重定向运算符,在shell命令解析前,首先检查的(一个命令,执行前一定检查好它的输入,输出,也就是0,1,2 设备是否准备好),所以优先级会最高
[[email protected] shell]$ sed -n '1,10p'<test.sh | grep -n 'echo' <testsh.sh 10:echo $total; 18:echo $total; 21: echo "ok"; #哈哈,这个grep又接受管道输入,又有testsh.sh输入,那是不是2个都接收呢。刚才说了"<"运算符会优先,管道还没有发送数据前,grep绑定了testsh.sh输入,这样sed命令输出就被抛弃了。这里一定要小心使用
#输出重定向
[[email protected] shell]$ cat test.sh>test.txt [[email protected] shell] cat test.sh|tee test.txt &>/dev/null #通过管道实现将结果存入文件,还需要借助命令tee,它会把管道过来标准输入写入文件test.txt ,然后将标准输入复制到标准输出(stdout),所以重定向到/dev/null 不显示输出 #">"输出重定向,往往在命令最右边,接收左边命令的,输出结果,重定向到指定文件。也可以用到命令中间。
[[email protected] shell]$ ls test.sh test1.sh testsh.sh 2>err.txt | grep 'test' test.sh testsh.sh #目录下面有:test,testsh文件,test1.sh不存在,因此将ls 命令错误输出输入到err.txt 正确输出,还会通过管道发送到grep命令。 [[email protected] shell]$ ls test.sh test1.sh testsh.sh &>err.txt | grep 'test' #这次打印结果是空,&代表正确与错误输出 都输入给err.txt,通过管道继续往下面传递数据为空,所以没有什么显示的
#同样">"输出重定向符,优先级也是先解析,当一个命令有这个字符,它就会与左边命令标准输出绑定。准备好了这些,就等待命令执行输出数据,它就开始接收 |
再概括下:
从上面例子可以看,重定向与管道在使用时候很多时候可以通用,其实,在shell里面,经常是【条条大路通罗马】的。一般如果是命令间传递参数,还是管道的好,如果处理输出结果需要重定向到文件,还是用重定向输出比较好。
命令执行顺序可以看下:Linux Shell 通配符、元字符、转义符使用实例介绍
shell脚本接收管道输入
有意思的问题:
既然作用管道接收命令,需要可以接收标准的输入,那么我们shell脚本是否可以开发出这样的基本程序呢?(大家经常看到的,都是一些系统的命令作为管道接收方)
实例(testpipe.sh):
#!/bin/sh
if [ $# -gt 0 ];then exec 0<$1; #判断是否传入参数:文件名,如果传入,将该文件绑定到标准输入 fi
while read line do echo $line; done<&0; #通过标准输入循环读取内容 exec 0&-; #解除标准输入绑定 |
运行结果:
[[email protected] shell]$ cat testpipe.txt 1,t,est pipe 2,t,est pipe 3,t,est pipe 4,t,est pipe #testpipe.txt 只是需要读取的测试文本
[[email protected] shell]$ cat testpipe.txt | sh testpipe.sh 1,t,est pipe 2,t,est pipe 3,t,est pipe 4,t,est pipe #通过cat 读取 testpipe.txt 发送给testpipe.sh 标准输入
[[email protected] shell]$ sh testpipe.sh testpipe.txt 1,t,est pipe 2,t,est pipe 3,t,est pipe 4,t,est pipe #testpipe.sh 通过出入文件名读取文件内容 |
重定向 tee 先在终端显示 并重定向
[[email protected] yum.repos.d]# ls >f1
[[email protected] yum.repos.d]# cat f1
cdrom.repo
CentOS-Base.repo
CentOS-CR.repo
CentOS-Debuginfo.repo
CentOS-fasttrack.repo
CentOS-Media.repo
CentOS-Sources.repo
CentOS-Vault.repo
f1
[[email protected] yum.repos.d]# ls |tee f1
cdrom.repo
CentOS-Base.repo
CentOS-CR.repo
CentOS-Debuginfo.repo
CentOS-fasttrack.repo
CentOS-Media.repo
4.基本的管线命令指令介绍
cut
语法:[root @test /root ]# cut -d "分隔字符" [-cf] fields
参数说明:
-d :后面接的是用来分隔的字符,预设是『空格符』
-c :后面接的是『第几个字符』
-f :后面接的是第几个区块?
范例:
C代码
![]()
[root @test /root]# cat /etc/passwd | cut -d ":" -f 1
#将 passwd 这个文件里面,每一行里头的 : 用来作为分隔号,而列出第一个区块!也就是姓名所在啦! 注:也可是多行-f n-z
[root @test /root]# last | cut -c1-20
#将 last 之后的数据,每一行的 1-20 个字符取出来!
sort(行排序)
语法:[root @test /root ]# sort [-t 分隔符] [(+起始)(-结束)] [-nru]
参数说明:
+start -end:由第 start 区间排序到 end 区间
-n :使用『纯数字』排序(否则就会以文字型态来排序)
-r :反向排序
-u :相同出现的一行,只列出一次!
-t c 选项使用c做为字段界定符 ,预设是 tab
-k X 选项按照使用c字符分隔的X列来整理能够使用多次
范例:
C代码
![]()
[root @test /root]# cat /etc/passwd | sort #将列出来的个人账号排序!
[root @test /root]# cat /etc/passwd | sort -t: +2n #将个人账号中,以使用者 ID 来排序(以 : 来分隔,第三个为 ID ,但第一个代号为 0 之故)
[root @test /root]# cat /etc/passwd | sort -t: +2nr #反相排序啰!
4. [[email protected] home]# sort -t: -k3 -n /etc/passwd
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
sync:x:5:0:sync:/sbin:/bin/sync
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
halt:x:7:0:halt:/sbin:/sbin/halt
mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
uucp:x:10:14:uucp:/var/spool/uucp:/sbin/nologin
wc
语法:[root @test /root ]# wc [-lmw]
参数说明:
-l :多少行
-m :多少字符
-w :多少字
范例:
C代码
![]()
[root @test /root]# cat /etc/passwd | wc -l #这个文件里头有多少行?
[root @test /root]# cat /etc/passwd | wc -w #这个文件里头有多少字!?
uniq
这个指令用来将『重复的行删除掉只显示一个』
-c: 显示每行重复出现的次数
-d: 仅显示重复过的行
-u: 仅显示不曾重复的行 连续且完全相同方为重复
范例:
C代码
![]()
[root @test /root]# last | cut -d" " -f1 | sort | uniq
tee
命令重定向到文件的同时将数据显示在屏幕上
语法:[root @test /root ]# last | tee last.list | cut -d " " -f1
范例:
C代码
![]()
[root @test /root]# last | tee last.list | cut -d " " -f1
tr
语法:[root @test /root ]# tr [-ds] SET1
参数说明:
-d :删除 SET1 这个字符串
-s :取代掉重复的字符!
范例:
C代码
![]()
[root @test /root]# last | tr '[a-z]' '[A-Z]' #<==将小写改成大写
[root @test /root]# cat /etc/passwd | tr -d : #<== : 这个符号在 /etc/passwd 中不见了!
[root @test /root]# cat /home/test/dostxt | tr -d '\r' > f1 重定向处理
split(切割文件)
语法:[root @test /root ]# split [-bl] 输入文件 输出文件前导字符
参数说明:
-b :以文件 size 来分
-l :以行数来分
范例:[root @test /root]# split -l 5 /etc/passwd test <==会产生 testaa, testab, testac... 等等的文件
说明:在 Linux 底下就简单的多了!你要将文件分割的话,那么就使用 -b size 来将一个分割的文件限制其大小,如果是行数的话,那么就使用 -l line 来分割!
管线命令在 bash 的连续的处理程序中是相当重要的!另外,在 log file 的分析当中也是相当重要的一环。
管道输送到一个命令的标准输入可以使用标准输入参数”-“ 进行更仔细的控制
[[email protected] ~]#tar -cvf - /home|tar -xvf -
表示把home目录打包成一个文件后,通过管道传给后面,再把这个文件解包,用-代替这个文件。
例子:
![]()
sort mylist | more
sort mylist | cat –n | lpr
pwd | cat – mylist | lpr
练习题
将/etc/issue文件中的内容转换为大写后保存至/tmp/issue.out文件中
[[email protected] ~]# cat /etc/issue | tr 'a-z' 'A-Z' >app/issue.out
将当前系统登录用户的信息转换为大写后保存至/tmp/who.out文件中
一个linux用户给root发邮件,要求邮件标题为”help”,邮件正文如下:
Hello, I am 用户名,The system version is here,pleasehelp me to check it ,thanks!
操作系统版本信息
[[email protected] ~]# echo -e "hello,I am `whoami`,the system version is here,please help me to it,thanks!\n`cat /etc/centos-release`" | mail -s "help" root
:重温echo -e "\n"运用
[[email protected] app]#mail -s "help" root<<end
>Hello,I am whoami,The system version is here ,please help me to check it,thanks!
>`cat /etc/centos-release`
>end
:mail 此时为执行输入命令
将/root/下文件列表,显示成一行,并文件名之间用空格隔开
[[email protected] ~]# ls | tr '\n' ' '
计算1+2+3+..+99+100的总和
[email protected] ~]# echo {1..100} | tr ' ' '+' |bc
处理字符串“xt.,l 1 jr#!$mn2 c*/fe3 uz4”,只保留其中的数字和空格
[[email protected] ~]# echo 'xt.,l 1 jr#sumn2 c*/fe3 uz4'|tr -dc '0-9 '
:‘0-9空格’
将PATH变量每个目录显示在独立的一行
[[email protected] ~]# echo $PATH
/usr/lib64/qt-3.3/bin:/usr/local/sbin:/usr/local/bin:/sbin:/bin:/usr/sbin:/usr/bin:/root/bin
[[email protected] ~]# echo $PATH |tr ':' '\n'
/usr/lib64/qt-3.3/bin
/usr/local/sbin
/usr/local/bin
/sbin
/bin
/usr/sbin
/usr/binyong
/root/bin
将文件中每个单词(由字母组成)显示在独立的一行,并无空行
[[email protected] ~]# echo $PATH
/usr/lib64/qt-3.3/bin:/usr/local/sbin:/usr/local/bin:/sbin:/bin:/usr/sbin:/usr/bin:/root/bin
[[email protected] ~]# echo $PATH |tr -c 'a-zA-Z' ' ' |tr -s ' ' '\n'
Usr
lib
qt
bin
usr
local
sbin
usr
local
bin
sbin
bin
usr
sbin
usr
bin
root
bin
mv目录的时候,只能是在同一设备/媒体之间。
如果是从/dev/sda1移动到 /dev/sdb1 ,则不行。只能是先拷贝过去,再删除。
以上是关于重定向和管道的主要内容,如果未能解决你的问题,请参考以下文章