深度学习的异构加速技术:螺狮壳里做道场
Posted 腾讯云加社区
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深度学习的异构加速技术:螺狮壳里做道场相关的知识,希望对你有一定的参考价值。
作者简介:kevinxiaoyu,高级研究员,隶属腾讯TEG-架构平台部,主要研究方向为深度学习异构计算与硬件加速、FPGA云、高速视觉感知等方向的构架设计和优化。“深度学习的异构加速技术”系列共有三篇文章,主要在技术层面,对学术界和工业界异构加速的构架演进进行分析。
一、综述
在“深度学习的异构加速技术(一)”一文所述的AI加速平台的第一阶段中,无论在FPGA还是ASIC设计,无论针对CNN还是LSTM与MLP,无论应用在嵌入式终端还是云端(TPU1),其构架的核心都是解决带宽问题。不解决带宽问题,空有计算能力,利用率却提不上来。就像一个8核CPU,若其中一个内核就将内存带宽100%占用,导致其他7个核读不到计算所需的数据,将始终处于闲置状态。对此,学术界涌现了大量文献从不同角度对带宽问题进行讨论,可归纳为以下几种:
A、流式处理与数据复用
B、片上存储及其优化
C、位宽压缩
D、稀疏优化
E、片上模型与芯片级互联
F、新兴技术:二值网络、忆阻器与HBM
下面对上述方法如何解决带宽问题,分别论述。
二、不同招式的PK与演进
2.1、流式处理与数据复用
流式处理是应用于FPGA和专用ASIC高效运算结构,其核心是基于流水线的指令并行,即当前处理单元的结果不写回缓存,而直接作为下一级处理单元的输入,取代了当前处理单元结果回写和下一处理单元数据读取的存储器访问。多核CPU和GPU多采用数据并行构架,与流式处理构架的对比如图2.1所示。图左为数据并行的处理方式,所有运算单元受控于一个控制模块,统一从缓存中取数据进行计算,计算单元之间不存在数据交互。当众多计算单元同时读取缓存,将产生带宽竞争造成瓶颈;图右为基于指令并行的二维流式处理,即每个运算单元都有独立的指令(即定制运算逻辑),数据从相邻计算单元输入,并输出到下一级计算单元,只有与存储相邻的一侧存在数据交互,从而大大降低了对存储带宽的依赖,代表为FPGA和专用ASIC的定制化设计。
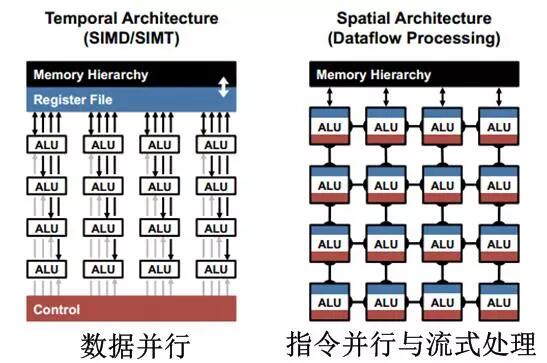
图2.1 数据并行与流式处理的对比
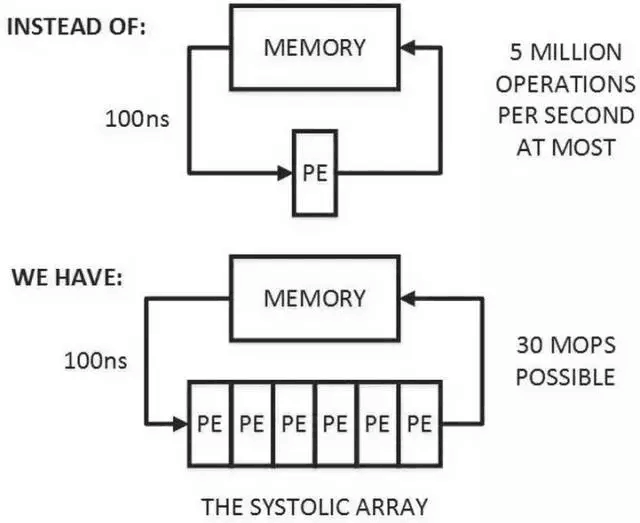
图2.2 一维脉动阵列(上)TPU中的二维脉动阵列(下)
当流式处理中各个处理单元(Processing Element, PE)具有相同结构时,有一个专属名称——脉动矩阵,一维的脉动矩阵如图2.2(上)所示。当一个处理单元从存储器读取数据处理,经过若干同构PE处理后写回到存储器。对存储器而言,只需满足单PE的读写带宽即可,降低了数据存取频率。脉动架构的思想很简单:让数据尽量在处理单元中多流动一段时间。当一个数据从第一个PE输入直至到达最后一个PE,它已经被处理了多次。因此,它可以在小带宽下实现高吞吐[1]。
TPU中采用的二维脉动阵列如图2.2(下)所示,用以实现矩阵-矩阵乘和向量-矩阵乘。数据分别从Cell阵列的上侧和左侧流入,从下侧流出。每个Cell是一个乘加单元,每个周期完成一次乘法和一次加法。当使用该脉动阵列做卷积运算时,二维FeatureMap需要展开成一维向量,同时Kernel经过旋转,而后输入,如TPU专利中的图2.3所示。

图2.3 TPU专利中,脉动阵列在卷积运算时的数据重排
在极大增加数据复用的同时,脉动阵列也有两个缺点,即数据重排和规模适配。第一,脉动矩阵主要实现向量/矩阵乘法。以CNN计算为例,CNN数据进入脉动阵列需要调整好形式,并且严格遵循时钟节拍和空间顺序输入。数据重排的额外操作增加了复杂性,据推测由软件驱动实现。第二,在数据流经整个阵列后,才能输出结果。当计算的向量中元素过少,脉动阵列规模过大时,不仅难以将阵列中的每个单元都利用起来,数据的导入和导出延时也随着尺寸扩大而增加,降低了计算效率。因此在确定脉动阵列的规模时,在考虑面积、能耗、峰值计算能力的同时,还要考虑典型应用下的效率。
寒武纪的DianNao系列芯片构架也采用了流式处理的乘加树(DianNao[2]、DaDianNao[3]、PuDianNao[4])和类脉动阵列的结构(ShiDianNao[5])。为了兼容小规模的矩阵运算并保持较高的利用率,同时更好的支持并发的多任务,DaDianNao和PuDianNao降低了计算粒度,采用了双层细分的运算架构,即在顶层的PE阵列中,每个PE由更小规模的多个运算单元构成,更细致的任务分配和调度虽然占用了额外的逻辑,但有利于保证每个运算单元的计算效率并控制功耗,如图2.4所示。
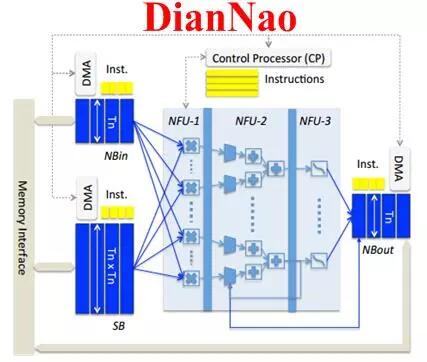
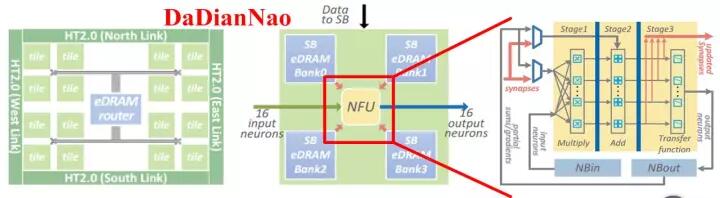
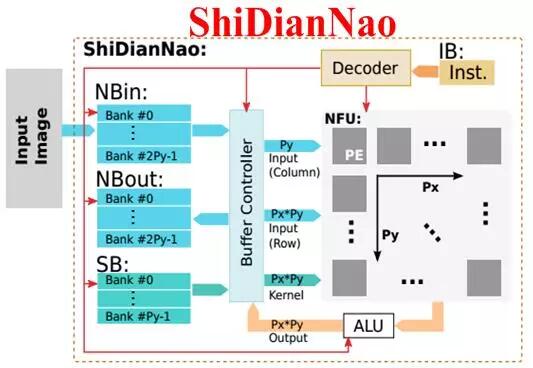
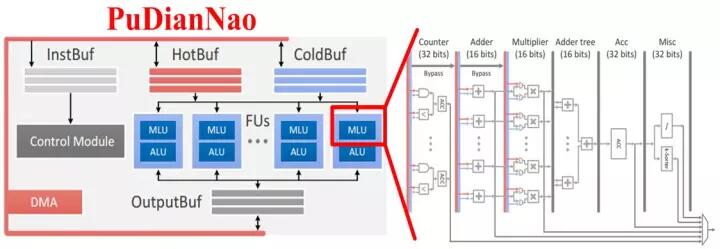
图2.4 基于流式处理的计算单元组织结构:从上到下依次为DianNao、DaDianNao整体框架与处理单元、ShiDianNao、PuDianNao的总体框图和每个MLU处理单元的内部结构
除了采用流式处理减少PE对输入带宽的依赖,还可通过计算中的数据复用降低带宽,CNN中的复用方式如图2.5所示。
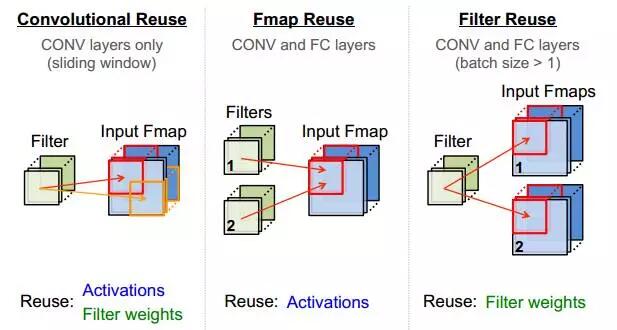 | 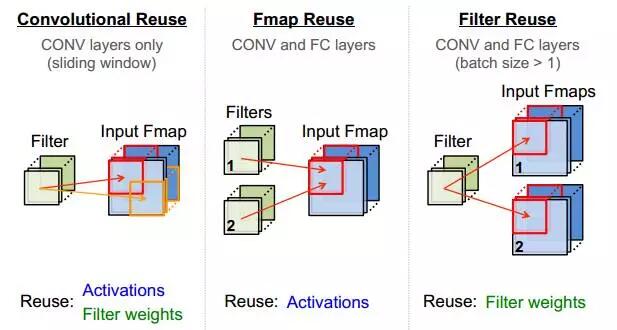 | 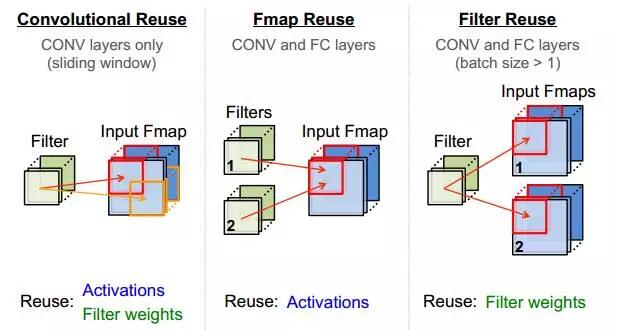 |
|---|---|---|
| (a) | (b) | (c) |
图2.5 CNN中的数据复用
在图2.5 的(a) (b)(c)分别对应卷积核的整张FeatureMap复用、一组FeatureMap对多组Filter的复用、Filter通过增加BatchSize而复用。当上述三种方式结合使用时,可极大提升数据复用率,这也是TPU在处理CNN时逼近峰值算力,达到86Tops/s的原因之一。
2.2、片上存储及其优化
片外存储器(如DDR等)具有容量大的优势,然而在ASIC和FPGA设计中,DRAM的使用常存在两个问题,一是带宽不足,二是功耗过大。由于需要高频驱动IO,DRAM的访问能耗通常是单位运算的200倍以上,DRAM访问与其它操作的能耗对比如图2.6所示。
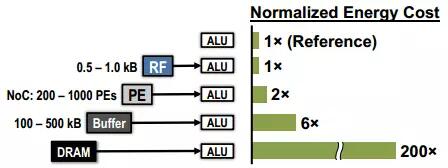
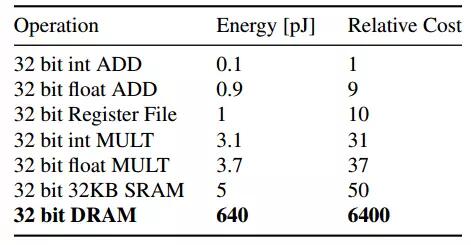
图2.6 片外DRAM访问的能耗开销
为了解决带宽和能耗问题,通常采用两种方式:片上缓存和临近存储。
1)增加片上缓存,有利于在更多情况下增加数据复用。例如矩阵A和B相乘时,若B能全部存入缓存,则仅加载B一次,复用次数等价于A的行数;若缓存不够,则需多次加载,增加带宽消耗。当片上缓存足够大,可以存下所有计算所需的数据,或通过主控处理器按需发送数据,即可放弃片外DRAM,极大降低功耗和板卡面积,这也是半导体顶会ISSCC2016中大部分AI ASIC论文采用的方案。
2)临近存储。当从片上缓存加载数据时,若采用单一的片上存储,其接口经常不能满足带宽的需求,集中的存储和较长的读写路径也会增加延迟。此时可以增加片上存储的数量并将其分布于计算单元数据接口的临近位置,使计算单元可以独享各自的存储器带宽。随着数量的增加,片上存储的总带宽也随之增加,如图2.7所示。
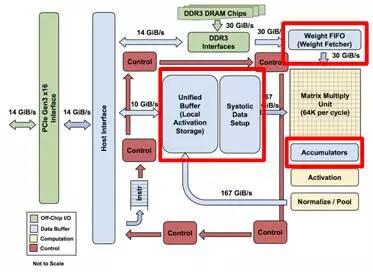
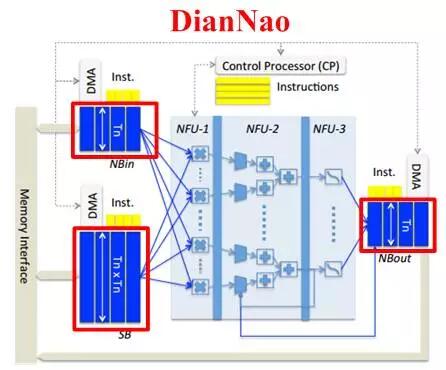
图2.7 TPU(上)和DianNao(下)的片上存储器分布
图2.7中的脉动阵列和乘加树都是规模较大的计算单元,属于粗粒度。当采用细粒度计算单元的结构时,如图2.8所示,可采用分层级存储方式,即除了在片上配置共享缓存之外,在每个计算单元中也配置专属存储器,使计算单元独享其带宽并减少对共享缓存的访问。寒武纪的DaDianNao采用也是分层级存储,共三层构架,分别配置了中央存储器,四块环形分布存储器,和输入输出存储器,如图2.9所示,极大增强了片上的存储深度和带宽,辅以芯片间的互联总线,可将整个模型放在片上,实现片上Training和Inference。
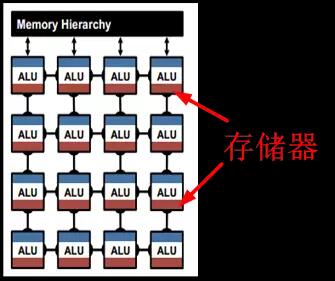
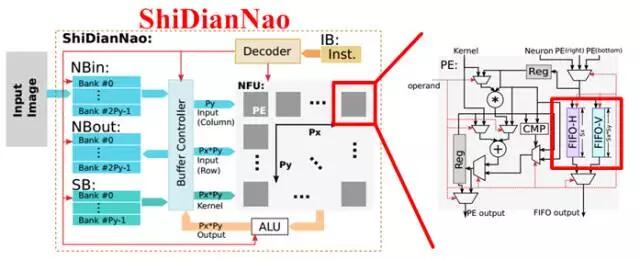
图2.8 细粒度计算单元与邻近存储,上图中深红色为存储器
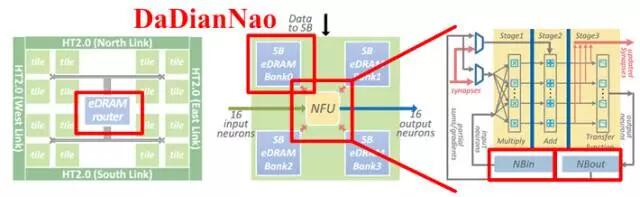
图2.9DaDianNao的计算单元与存储器分布
2.3、位宽压缩
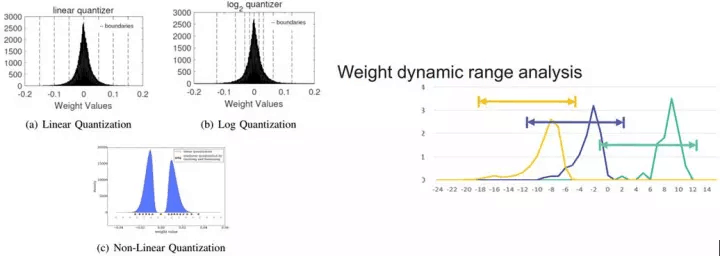
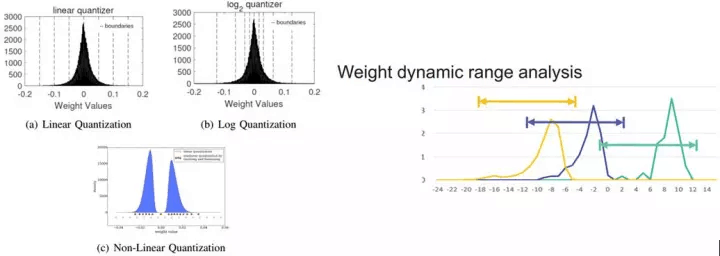
在两年前,深度学习的定制处理器构架还处于初始阶段,在Inference中继承了CPU和GPU的32bit浮点量化,每次乘法运算不仅需要12字节的读写(8bit量化时为3字节),32位运算单元占用较大的片上面积,增加了能耗和带宽消耗。PuDianNao的论文中指出[4],16bit乘法器在ASIC占用面积上是32bit乘法器的1/5,即在相同尺寸的面积上可布局5倍数量的乘法器。当使用8bit时将获得更高收益。因此,学术界孜孜不倦的追求更低的量化精度,从16bit,到自定义的9bit[6],8bit,甚至更激进的2bit和1bit的二值网络[7-8]。当高位宽转为低位宽的量化时,不可避免的带来精度损失。对此,可通过量化模式、表征范围的调整、编码等方式、甚至增加模型深度(二值网络)来降低对精度的影响,其中量化模式、表征范围的调整方法如图2.10 所示。
 |  |
|---|---|
| (a) | (b) |
图2.10 (a) 几种量化模式,和 (b) 动态位宽调整
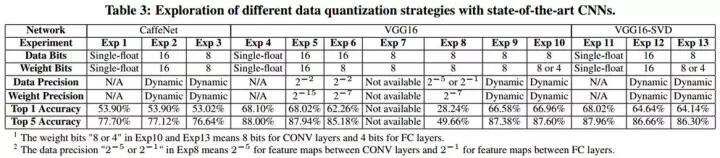
图2.10 (a) 中为不同的量化模式,同样的8bit,可根据模型中数值的分布情况采用为线性量化、Log量化、或非线性量化表示。图2.10 (b)是Jiantao Qiu等提出的动态位宽调整[9],使8bit的量化在不同层之间使用不同的偏移量和整数、小数分配,从而在最小量化误差的约束下动态调整量化范围和精度,结合重训练,可大幅降低低位宽带来的影响。在CNN模型中的测试结果见下表:
低位宽意味着在处理相同的任务时更小的算力、带宽和功耗消耗。在算力不变的前提下,成倍的增加吞吐。对于数据中心,可大幅度降低运维成本,使用更少的服务器或更廉价的计算平台即可满足需求(TPU的数据类型即为8/16bit);对于更注重能耗比和小型化嵌入式前端,可大幅降低成本。目前,8bit的量化精度已经得到工业界认可,GPU也宣布在硬件上提供对8bit的支持,从而将计算性能提高近4倍,如图2.11所示。FPGA巨头Xilinx也在AI加速的官方文档中论述了8bit量化的可行性[10]。
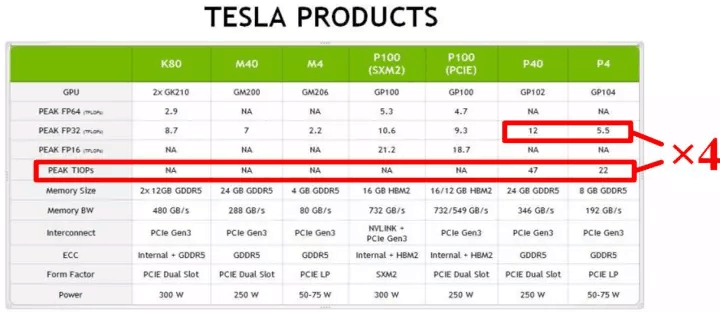
图2.11 NVIDIA对int8的支持
2.4、稀疏优化
上述的论述主要针对稠密矩阵计算。在实际应用中,有很大一部分AI应用和矩阵运算属于稀疏运算,其主要来源于两个方面:
1) 算法本身存在稀疏。如NLP(Natural Language Processing,自然语言处理)、推荐算法等应用中,通常一个几万维的向量中,仅有几个非零元素,统统按照稠密矩阵处理显然得不偿失。
2) 算法改造成稀疏。为了增加普适性,深度学习的模型本身存在冗余。在针对某一应用完成训练后,很多参数的贡献极低,可以通过剪枝和重新训练将模型转化为稀疏。如深鉴科技的韩松在FPGA2017上提出针对LSTM的模型剪枝和专用的稀疏化处理架构,如图2.12 所示[11]。
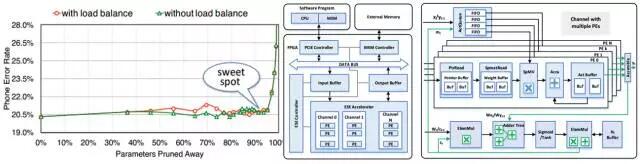
图2.12 LSTM模型剪枝比例与精度(左)和稀疏处理构架(右)
图2.12 左图,为LSTM模型剪枝掉90%的参数后,基本没有精度损失,模型得到了极大的稀疏化。图右侧为针对稀疏的FPGA处理构架,将处理的PE之间进行异步调度,在每个PE的数据入口使用独立的数据缓存,仅将非零元素压入参与计算,获得了3倍于Pascal Titan X的性能收益和11.5倍的功耗收益。稀疏化并不仅限于LSTM,在CNN上也有对应的应用。
与之对应的,寒武纪也开发了针对稀疏神经网络的Cambricon-X[12]处理器,如图2.13所示。类似的,Cambricon-X也在每个PE的输入端口加入了Indexing的步骤,将非零元素筛选出后再输入进PE。与深鉴不同的是,Cambricon-X支持不同稀疏程度的两种indexing编码,在不同稀疏程度的模型下使用不同的编码方式,以优化带宽消耗。
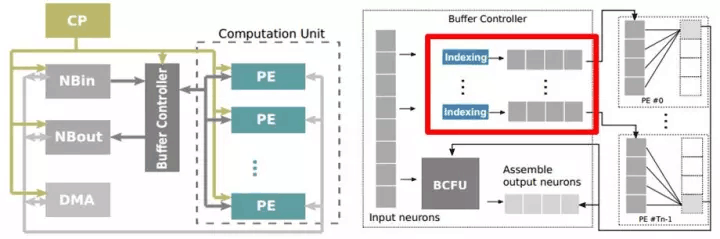
图2.13 寒武纪Cambricon-X稀疏神经网络处理器结构
可针对稀疏的优化有两个目的,一是从缓存中读入的都是有效数据从而避免大量无用的零元素占满带宽的情况,二是保证片上PE的计算效率,使每个PE的每次计算的输入都是“干货”。当模型剪枝结合稀疏处理构架,将成倍提升FPGA和ASIC的计算能力,效果显著,是异构加速的热点之一。
综上所述,稀疏化是从模型角度,从根本上减少计算量,在构架演进缺乏突破的情况下,带来的收益是构架优化所不能比拟的。尤其在结合位宽压缩后,性能提升非常显著。然而稀疏化需要根据构架特点,且会带来精度损失,需要结合模型重训练来弥补,反复调整。上述过程增加了稀疏优化的门槛,需要算法开发和硬件优化团队的联合协作。对此,深鉴科技等一些公司推出稀疏+重训练的专用工具,简化了这一过程,在大量部署的场景下,将带来相当的成本优势。
2.5、片上模型与芯片级互联
为了解决带宽问题,通常的做法是增加数据复用。在每次计算的两个值中,一个是权值Weight,一个是输入Activation。如果有足够大的片上缓存,结合适当的位宽压缩方法,将所有Weight都缓存在片上,每次仅输入Activation,就可以在优化数据复用之前就将带宽减半。然而从GoogleNet50M到ResNet 150M的参数数量,在高成本的HBM普及之前,ASIC在相对面积上无法做到如此大的片上存储。而随着模型研究的不断深入,更深、参数更多的模型还会继续出现。对此,基于芯片级互联和模型拆分的处理模式,结合多片互联技术,将多组拆分层的参数配置于多个芯片上,在Inference过程中用多芯片共同完成同一任务的处理。寒武纪的DaDianNao就是实现这样的一种芯片互联结合大缓存的设计,如图2.14所示。
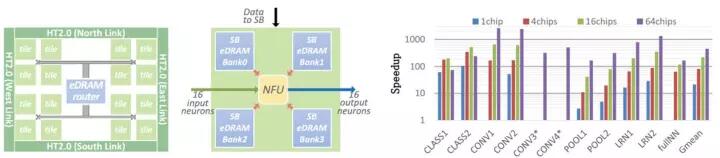
图2.14DaDianNao中的存储器分布(图中蓝色部分)和多片互联时的加速能力(以GPU K20M为单位性能的比较)
为了将整个模型放在片上,DaDianNao一方面将片上缓存的容量增加到36MB(DaDianNao为36MB和4608个乘加器,TPU为28MB缓存和65536乘加器),充分保证计算单元的读写带宽,另一方面通过HT2.0实现6.4GB/s*4通道的片间通信带宽,降低数据才层与层之间传递的延迟,完全取代了片外DRAM的交互,解决带宽制约计算的问题。与之相应的,微软在Hot Chips 2017上提出将LSTM模型拆分后部署到多片FPGA,以摆脱片外存储器访问以实现Inference下的超低延迟[2]。
2.6、新兴技术:二值网络、忆阻器与HBM
除了采用上述方式解决带宽问题,学术界近期涌现出了两种更为激进的方法,二值网络和忆阻器;工业界在存储器技术上也有了新的突破,即HBM。
二值网络是将Weight和Activation中的一部分,甚至全部转化为1bit,将乘法简化为异或等逻辑运算,大大降低带宽,非常适合DSP资源有限而逻辑资源丰富的FPGA,以及可完全定制的ASIC。相对而言,GPU的计算单元只能以32/16/8bit为单位进行运算,即使运行二值模型,加速效果也不会比8bit模型快多少。因此,二值网络成为FPGA和ASIC在低功耗嵌入式前端应用的利器。目前二值网络的重点还在模型讨论阶段,讨论如何通过增加深度与模型调整来弥补二值后的精度损失。在简单的数据集下的效果已得到认可,如MNIST,Cifar-10等。
既然带宽成为计算瓶颈,那么有没有可能把计算放到存储器内部呢?既然计算单元临近存储的构架能提升计算效率,那么能否把计算和存储二者合一呢?忆阻器正是实现存储器内部计算的一种器件,通过电流、电压和电导的乘法关系,在输入端加入对应电压,在输出即可获得乘加结果,如图2.15所示[13]。当将电导作为可编程的Weight值,输入作为Activation,即可实现神经网络计算。目前在工艺限制下,8bit的可编程电导技术还不成熟,但在更低量化精度下尚可。将存储和计算结合,将形成一种有别于冯诺依曼体系的全新型构架,称为在存储计算(In-Memory Computing),有着巨大的想象空间。
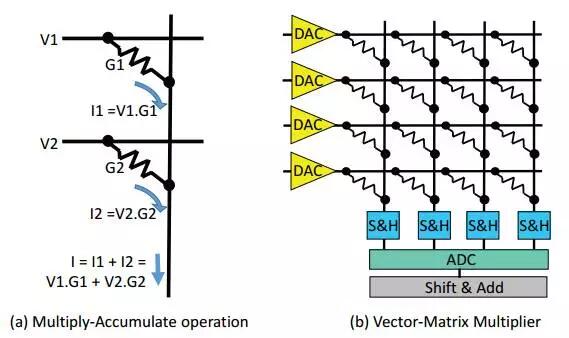
图2.15 忆阻器完成乘加示意图(左)与向量-矩阵运算(右)
随着工业界芯片制造技术的发展与摩尔定律的逐渐失效,简单通过提升工艺制程来在面积不变的条件下增加晶体管数量的方式已经逐渐陷入瓶颈。相应的,二维技术的局限使工艺向第三维度迈进。例如在存储领域,3D构架和片内垂直堆叠技术可在片上成倍增加缓存容量,其代表为高带宽存储器(HighBandwidth Memory,HBM)和混合存储器立方体(HybridMemory Cube,HMC)。据Intel透露,Lake Crest的片上HBM2可提供最高12倍于DDR4的带宽。目前,NVIDIAP100和V100 GPU已集成HBM2,片内带宽高达900GB/s;TPU2的片内HBM带宽为600GB/s;Xilinx集成HBM的FPGA将在18年上市。这一技术革新使得对于当前的深度学习模型,即使不采用芯片级互联方案也有望将整个模型置于片上,释放了FPGA/ASIC对片外DRAM的需求,为AI芯片发展提供巨大动力。
三、结语
上面的论述主要以当前学术界在AI处理器构架方面的讨论为主。然而在工业界,AI的大量需求已经在某些领域集中爆发,如云服务、大数据处理、安防、手机端应用等。甚至在一些应用中已经落地,如Google的TPU,华为的麒麟970等。AI处理器的发展和现状如何?我们下期见!
参考文献
[1] 唐杉, 脉动阵列-因Google TPU获得新生. http://mp.weixin.qq.com/s/g-BDlvSy-cx4AKItcWF7jQ
[2] Chen Y, Chen Y, Chen Y, et al.DianNao: a small-footprint high-throughput accelerator for ubiquitousmachine-learning[C]// International Conference on Architectural Support forProgramming Languages and Operating Systems. ACM, 2014:269-284.
[3] Luo T, Luo T, Liu S, et al.DaDianNao: A Machine-Learning Supercomputer[C]// Ieee/acm InternationalSymposium on Microarchitecture. IEEE, 2015:609-622.
[4] Liu D, Chen T, Liu S, et al.PuDianNao: A Polyvalent Machine Learning Accelerator[C]// TwentiethInternational Conference on Architectural Support for Programming Languages andOperating Systems. ACM, 2015:369-381.
[5] Du Z, Fasthuber R, Chen T, et al.ShiDianNao: shifting vision processing closer to the sensor[C]// ACM/IEEE,International Symposium on Computer Architecture. IEEE, 2015:92-104.
[6] Eric Chung, Jeremy Fowers, KalinOvtcharov, et al. Accelerating Persistent Neural Networks at Datacenter Scale.Hot Chips 2017.
[7] Meng W, Gu Z, Zhang M, et al.Two-bit networks for deep learning on resource-constrained embedded devices[J].arXiv preprint arXiv:1701.00485, 2017.
[8] Hubara I, Courbariaux M, SoudryD, et al. Binarized neural networks[C]//Advances in neural informationprocessing systems. 2016: 4107-4115.
[9] Qiu J, Wang J, Yao S, et al.Going deeper with embedded fpga platform for convolutional neuralnetwork[C]//Proceedings of the 2016 ACM/SIGDA International Symposium onField-Programmable Gate Arrays. ACM, 2016: 26-35.
[10] Xilinx, Deep Learningwith INT8Optimizationon Xilinx Devices, https://www.xilinx.com/support/documentation/white_papers/wp486-deep-learning-int8.pdf
[11] Han S, Kang J, Mao H, et al.Ese: Efficient speech recognition engine with compressed lstm on fpga[J]. arXivpreprint arXiv:1612.00694, 2016.
[12] Zhang S, Du Z, Zhang L, et al. Cambricon-X: An accelerator for sparseneural networks[C]// Ieee/acm International Symposium on Microarchitecture.IEEE Computer Society, 2016:1-12.
[13] Shafiee A, Nag A, MuralimanoharN, et al. ISAAC: A convolutional neural network accelerator with in-situ analogarithmetic in crossbars[C]//Proceedings of the 43rd International Symposium onComputer Architecture. IEEE Press, 2016: 14-26.
以上是关于深度学习的异构加速技术:螺狮壳里做道场的主要内容,如果未能解决你的问题,请参考以下文章