阿里云大规模深度学习应用架构和性能优化实践
Posted 智东西公开课
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了阿里云大规模深度学习应用架构和性能优化实践相关的知识,希望对你有一定的参考价值。
阿里云异构计算AI加速负责人游亮在本文
分享了阿
里
云基于 AIACC 的大规模深度学习应用架构和性能优化实践,主要从深度学习应用基础架构、大规模深度学习应用的架构和挑战、基于云计算的大规模深度学习应用架构、大规模深度学习应用架构和性能优化实践等方面带来详细介绍。
近日,斯坦福大学公布了最新的 DAWNBench 深度学习榜单,这是人工智能领域最权威的竞赛之一,是衡量深度学习优化策略、模型架构、软件框架、云和硬件等综合解决方案实力的标准之一。
在图像识别(Image Classification on ImageNet)榜单中,阿里云包揽了训练时间、训练成本、推理延迟以及推理成本四项第一。DAWNBench 官方显示,阿里云异构计算服务训练 ImageNet 128 万张图片仅需 2 分 38 秒,基于含光 800 的 AI 服务识别一张图片仅需 0.0739ms,同时在训练成本和推理成本上也实现世界纪录的突破。
此次,阿里云创造四项纪录得益于阿里云自研加速框架 AIACC 及平头哥含光 800 芯片。
其中,AIACC 是阿里云自主研发的飞天 AI 加速引擎,首次实现了统一加速 Tensorflow、PyTorch、MxNet 和 Caffe 等主流深度学习框架,在相同的硬件平台下,AIACC 能够显著提升人工智能训练与推理的性能。
作为 AIACC 的研发负责人,我将在本文内与大家分享阿里云基于 AIACC 的大规模深度学习应用架构和性能优化实践。
随着深度学习模型越来越复杂,对计算力的需求也越来越高。ResNet-50 训练 ImageNet 128 万张图片 90 个 epoch 可以达到 75% 的 Top-1 精度,用一块 P100 的 GPU 需要大概 5 天的时间,而各大厂都分别施展了各自的大规模分布式训练大法来缩短该标杆的训练时间。
2017 年 7 月,Facebook 自己设计了 Big Basin 服务器,每台服务器用了 8 块 P100 通过 NVLink 互联,Facebook 用了 32 台合 256 张 P100 用了 1 个小时就训练完。
2017 年 9 月,UCBerkeley 发表了一篇文章,用了 2048 块 NKL 将训练记录缩短到了 20 分钟。
2017 年 11 月,日本的 Preferred Network 采用了 1024 块 P100 将训练记录缩短到了 15 分钟。
2017 年 11 月,Google 也发表了一篇文章,用了 256 个 TPUv2 在 30 分钟内训练完。
2018 年 11 月 13 号,Sony 公司使用了 2176 块 V100,将训练记录缩短到 3 分 44 秒……
这些大厂都在争夺分布式训练的战略制高点,可以看出大规模分布式训练会是未来业界技术发展的趋势。
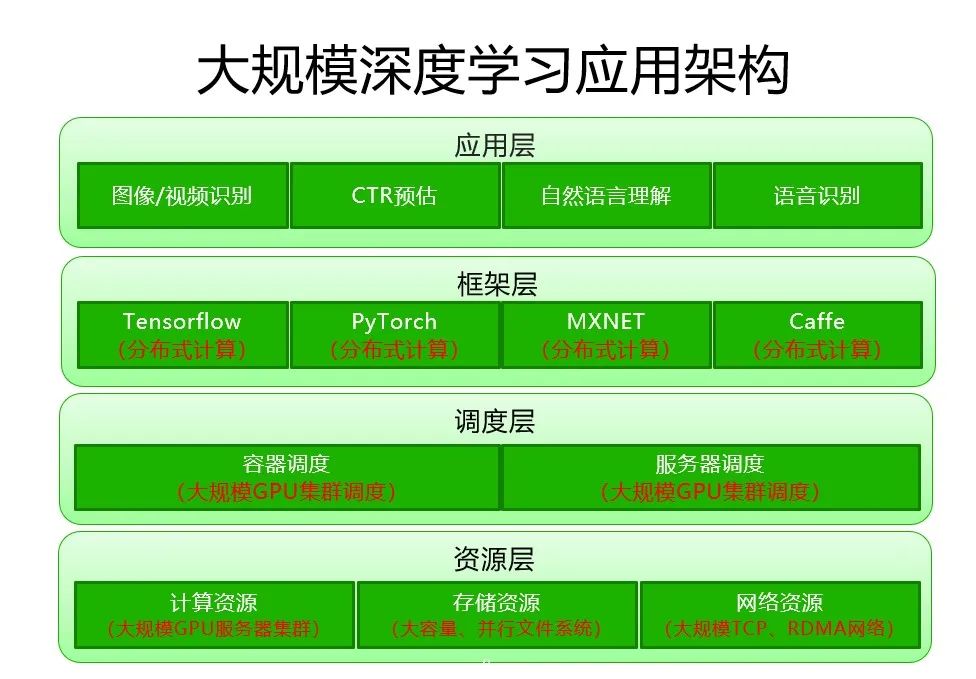
我们先来看看深度学习应用的基础架构。整个深度学习应用基础架构图,分为 4 个层次。
从下往上第一层是资源层,资源层包括计算资源、存储资源和网络资源。我们在做深度学习应用时,需要 GPU 服务器的计算资源来做深度学习训练和推理,需要存储资源来存训练代码和数据,需要网络资源处理多机之间的通信。
第 2 层是调度层,包括了基于容器的调度和基于物理机调度两种调度方式,负责向下调度计算资源、存储资源和网络资源,向上调度框架层和应用层的计算任务。
第 3 层是框架层,当前主流的深度学习计算框架包括了 Tensorflow、PyTorch、MXNET、Caffe 等主流计算框架。
第 4 层是应用层,应用层包括了图像识别、人脸识别、目标检测、视频识别、CTR 预估、自然语言理解、语音识别等深度学习的应用,应用层是由框架层的计算框架来描述和计算用户自己的模型和算法。
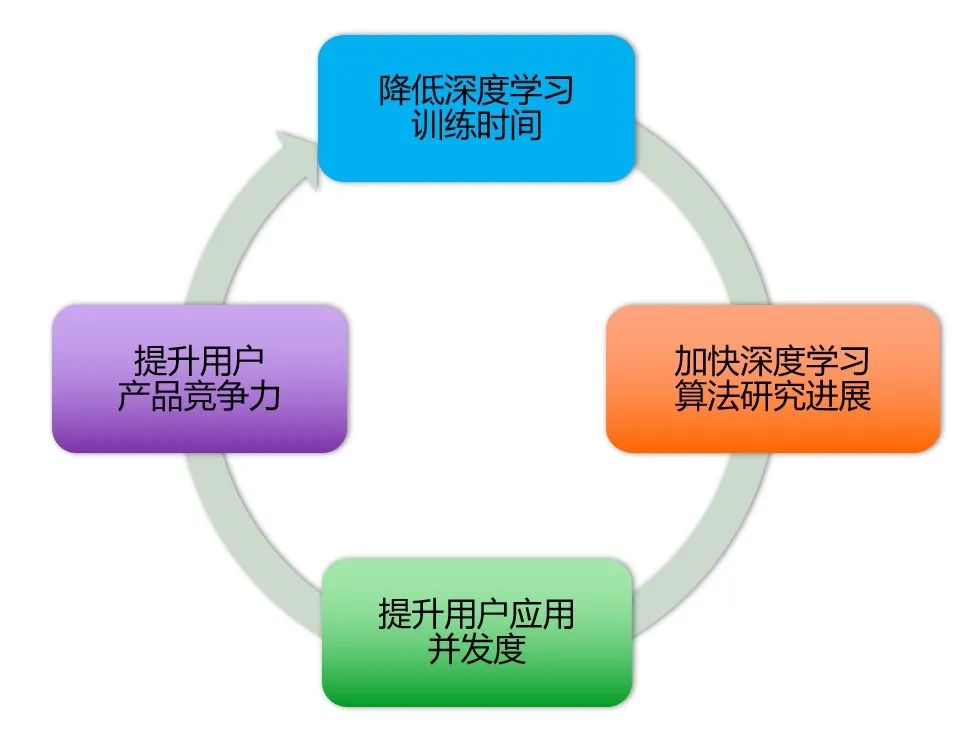
举个例子,我们曾训练一个模型,如果用一张 GPU 卡,需要 7 天的时间,意味着调整模型参数之后,可能在 7 天后才知道这个参数是否正确。如果我们用一台 8 卡 GPU 的服务器,就只需要不到一天的时间就可以训练完。如果我们有 10 台这样的 8 卡服务器训练的话,可能两三个小时就可以训练完一个模型。这样就能很快发现参数是否正确。
从这个例子可以看出,大规模深度学习具有以下 4 个优势:一是大规模分布式训练可以降低深度学习训练的时间;二是可以加速深度学习算法研究的效率和进程;三是大规模分布式推理可以提升用户深度学习应用的并发度和可靠性,四是最终提升用户产品的竞争力,提升用户产品市场占有率。所以,大规模深度学习对于公司来说,是提高生产力效率的制高点。
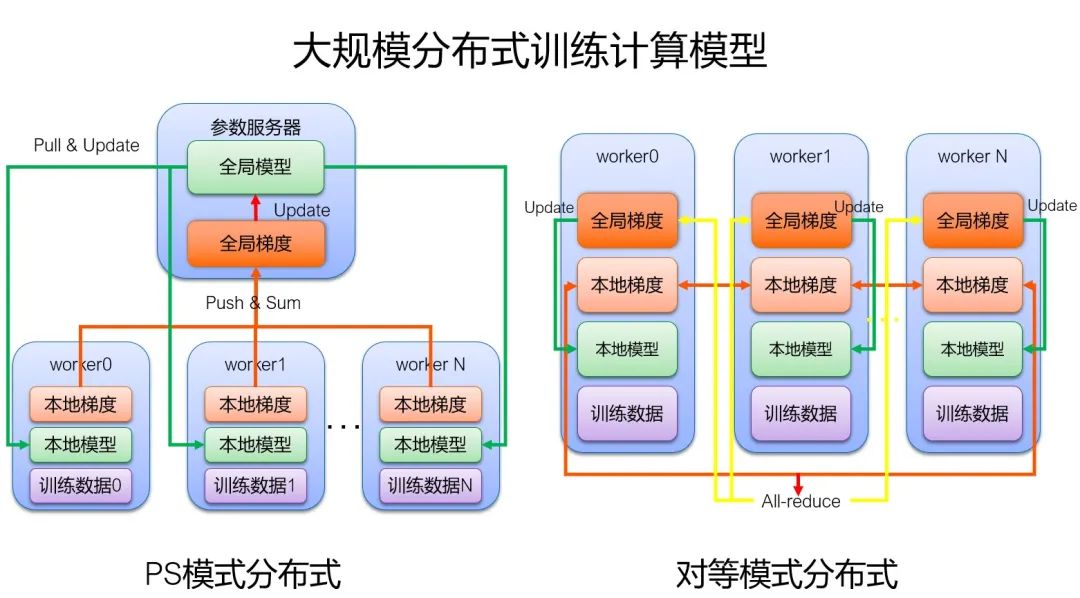
大规模分布式训练的基本计算模型大体上分为两类:一类是 PS 模式的分布式训练,一类是对等模式的分布式训练。
如图,PS 分布式有一个参数服务器,有很多个 worker,参数服务器负责存储全局模型,而每个 worker 上都有一份本地模型的副本;在分布式训练开始的时候,每个 worker 都会读取自己的训练数据,然后去更新本地的模型,得到本地的梯度;然后每个 worker 将本地的梯度上传到参数服务器上去得到全局梯度,参数服务器上再用全局梯度去更新全局模型,然后更新后的全局模型会去更新所有 worker 的本地模型,再进行下一次的训练迭代。
而对等模式没有参数服务器,每个 worker 都获得自己的训练数据,去更新本地的模型,得到本地的梯度,然后每个 worker 的本地梯度会做一个全局的 all-reduce 计算,从而每个 worker 都可以得到全局梯度,每个 worker 再用全局梯度去更新本地的模型,再进行下一次训练迭代。
PS 模式比较适合有大量模型参数的情况,一张 GPU 存不下模型大小,通过 PS 的分布式可以将大参数模型存下来,但是缺点是有中心化通信,当规模越来越大的时候,通信效率会越来越低。
而对等模式比较适合于一张 GPU 能够存下的模型大小,并且是一种去中心式的通信模式,可以通过 Ring-Allreduce 环形通信算法来降低通信复杂度。不同的计算框架都有不同的计算模式,例如 Tensorflow 既有 PS 模式又有对等模式,PyTorch 以支持对等模式为主,而 MXNET 以支持 KVStore 和 PS-Lite 的 PS 模式为主。
不同框架的不同分布式模式对于用户来写分布式代码、分布式性能优化以及分布式调度都会是非常大的阻碍。
在资源层,计算资源上,需要大规模的 GPU 服务器集群来做分布式训练,需要大容量的并行文件系统来做大规模的文件存储和提供并行的文件访问,还需要建设大规模的 TCP 或者 RDMA 网络。
在调度层,需要进行大规模的 GPU 集群和任务调度。
在框架层,需要感知计算和调度不同深度学习计算框架的分布式计算的模式。
在应用层,我们也需要去拆分训练数据,或者拆分训练模型到不同的 worker 上去。
因此,对于大规模深度学习的应用,会存在诸多的困难和挑战。
首先,建设大规模 GPU 集群是非常困难的,包括要解决大规模 GPU 机器的机房、机架、电源的问题,以及它们的稳定性和成本的问题。
其次,众所周知,建设大规模并行文件系统不仅需要建设大容量的并行文件系统,而且对于并行文件系统的稳定性和可靠性的挑战是非常之高的。
另外,需要建设大规模、高带宽的 TCP 或者 RDMA 网络也非常困难,需要规划和实现大规模交换机和节点的拓扑结构,规划和实现大规模南北向流量的收敛比,规划和实现大规模网络协议和 IP 地址,并且需要保障网络的可靠性以及大规模网络的性能。
对于调度层:不管是基于容器的调度还是基于物理机的调度,需要去做 CPU 和 GPU 的混合调度,需要做 GPU 显存共享调度,以及对不同深度学习计算框架的分布式调度。
对于框架层来说:各种主流的深度学习计算框架都有不同的分布式计算模式,需要在应用层做不同的分布式实现、调度层做不同的分布式调度,同时需要对针对底层的网络实现对各种框架做分布式性能优化。
这其中的任何一项,无不需要专业知识非常深厚的技术专家、架构师、工程师来部署和实现。
这些高深技术的实现和应用如何能够飞入寻常百姓家呢?幸好有云计算。
拿阿里云举例说明,从基于云计算的大规模深度学习应用的架构可以看出,在资源层,我们对于大规模 GPU 服务器集群的需求直接创建大规模 GPU 云计算服务器;对于这种大容量并行文件系统,直接可以创建并行文件系统 CPFS;对于大规模 TCP、RDMA 网络可以直接采用阿里云网络资源。
在调度层,我们对于大规模 GPU 集群的调度的需求,可以直接使用云容器调度 ACK 或者使用云虚机调度 EHPC。可以说当前云计算的产品基本能够快速解决大规模资源和调度层面的问题,并且不需要多高深的技术功底。
云计算对于大规模深度学习具有易用、弹性和稳定等天然优势。
首先是易用性。如果我们有一个非常紧急的需求需要在短时间内使用大量的 GPU 计算、存储和网络资源,阿里云在可以在十几分钟内按需开启大规模的 GPU 计算资源、大规模存储资源和大规模网络资源,而自己采购和部署的话一方面需要计算、存储、网络领域的技术高手,另一方面周期是按月来计。
第二是弹性。当业务高峰来的时候,可以弹性扩充出更多的基础资源来承接新增业务,而当业务高峰过去之后,就可以释放多余的基础资源,这样可以达到业务和基础资源成本的最佳配比。
第三是稳定性。阿里云提供的计算服务、存储服务和网络服务的稳定性都远超物理资源,阿里云的计算 + 网络服务的可靠性是 99.95%,而存储服务的可靠性是 99.9999999999%。
第四是成本优势。因为云计算本身具有规模性的优势,所以它具备物理硬件集中采购的成本优势,以及物理硬件集中管理、运维的成本优势,对业务来讲,则通过弹性伸缩达到业务成本最优配比。
对于大规模深度学习应用,除了云计算带来的这些优势之外,我们团队还做了两个基于云计算的架构升级,第 1 个是飞天 AI 加速引擎 AIACC,第 2 个是 FastGPU 即刻构建。
首先给大家介绍飞天 AI 加速引擎 AIACC,前面提到了不同框架的不同分布式模式对用户写分布式代码、分布式性能优化以及分布式调度都产生极大的学习成本和困难,而 AIACC 主要解决框架层面的大规模深度学习的统一性能加速和统一调度问题。它是业界首次统一加速 Tensorflow、PyTorch、MXNET、Caffe 等主流开源框架的性能加速引擎,具有四大优势。
前面提到,各种计算框架的不同的分布式模式会对统一的调度和应用层分布式的实现,都产生极大的阻碍。
而 AIACC 可以做到统一的分布式模式和分布式性能加速,这样调度层可以做到统一的分布式调度,应用层可以做到统一的分布式计算,同时对于底层分布式通信的优化只需要一份工作,各种框架都能享受到性能提升的好处。
第 2 个优势就是针对网络和 GPU 加速器都做了极致的优化,这个后面一节会详细的讲。
第 3 个优势是结合云端做弹性伸缩,让用户业务的成本最优。
第 4 个优势是和开源兼容的,用户用开源深度学习计算框架写的代码大部分都不用修改,直接采用 AIACC 库就可以得到性能上的飞跃。
AIACC 主要是利用了基于通信的性能优化技术。通过前面的分享我们知道,在做分布式训练的时候我们需要在机器之间、GPU 之间交换梯度数据,需要做到非常高效的数据通信。
第 1 个方面是做通讯和计算的重叠。我们梯度是做异步通信的,在计算的时候并行去做梯度通信,从而将通信的时间隐藏在计算后面。
第 2 个方面是做了延迟的优化。我们在做梯度通信之前需要去做梯度协商,需要知道每台机器上 GPU 里的梯度是不是 ready,然后再做通信。传统的做法是通过一个中心化的节点去做所有节点梯度协商,这样当规模上来时,延迟会非常高。而我们的优化方法是去中心化的方式去做梯度协商,这样的效率更高,大规模下延迟也不会提高。
第 3 方面的优化是做带宽的优化,带宽方面有 5 种优化方法:
第 1 种优化方法是基于拓扑结构的分级通信优化。我们知道在一台机器上的 GPU 之间的通信带宽是很高的,而跨机的 GPU 通讯的带宽是很低的,所以我们通过分级通信优化。先在机器内部做 GPU 之间的通信,然后再在 GPU 机器之间做通讯。
第 2 种优化方法是做混合精度传输。原始的梯度的精度都是 float32 类型的,我们在做计算的时候还是保持 float32 的精度,但是在梯度传输的时候可以把它转成 float16 的精度去做梯度传输,这样要传输的数据量直接减少一半。同时,我们通过 scaling 的方式保持精度不下降。
第 3 种优化方法,是做多梯度融合通信。一个模型在做分布式通信的时候需要对很多层的梯度都来做通信,如果每计算出来一个梯度就去做一次通信的话,很多层的梯度数据包是非常小的,对带宽的利用率是非常低的。于是,我们做了梯度融合,等到一批梯度融合之后,再做一批梯度的多机通信,这样对带宽利用率是很高的。
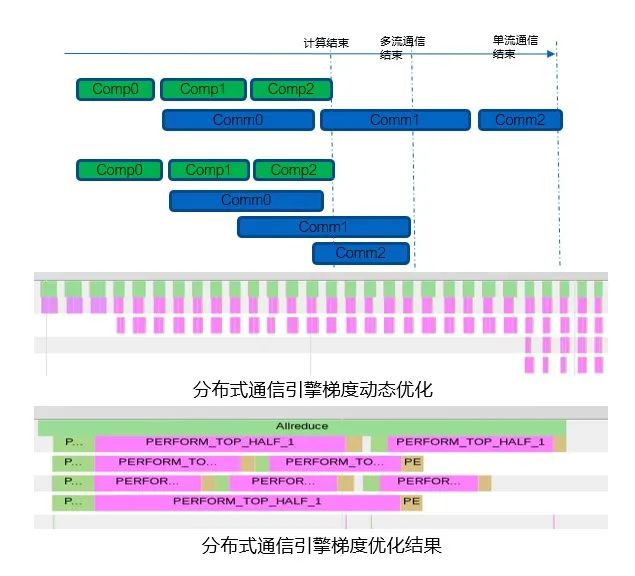
第 4 种优化方法是做多流通讯。在高带宽的 TCP 网络情况下,单个通信流是没有办法把带宽打满的,所以我们用多流来做通信。然而,我们发现,多流的情况下多流之间的传输速率是不一样的,于是做了负载均衡,传得更快的流会自动拿更多的梯度通信,传得更慢的流会通信更少的梯度。
第 5 种优化方法是对融合的粒度以及通信的流数作了一个动态的 tuning 过程。我们在开始训练开始的几个 batch 的时候,会根据当前网络的情况对这些参数做动态的调整从而达到最优性能,这样我们就可以动态的适配在不同网络情况下达到最优的性能。
这个图是我们做动态调优的过程,绿色部分是做计算,红色部分是做通信,我们可以看到在训练刚开始的几个 batch 只有一个流作通信,而且它的通信时间会比较长。在中间这一段我们开出了两个流来做通信,在后面这一段我们开出了 4 个流来做通信,并且 4 个流之间是做了负载均衡,在最后一个 batch 的时候,我们达到了一个最佳的性能。
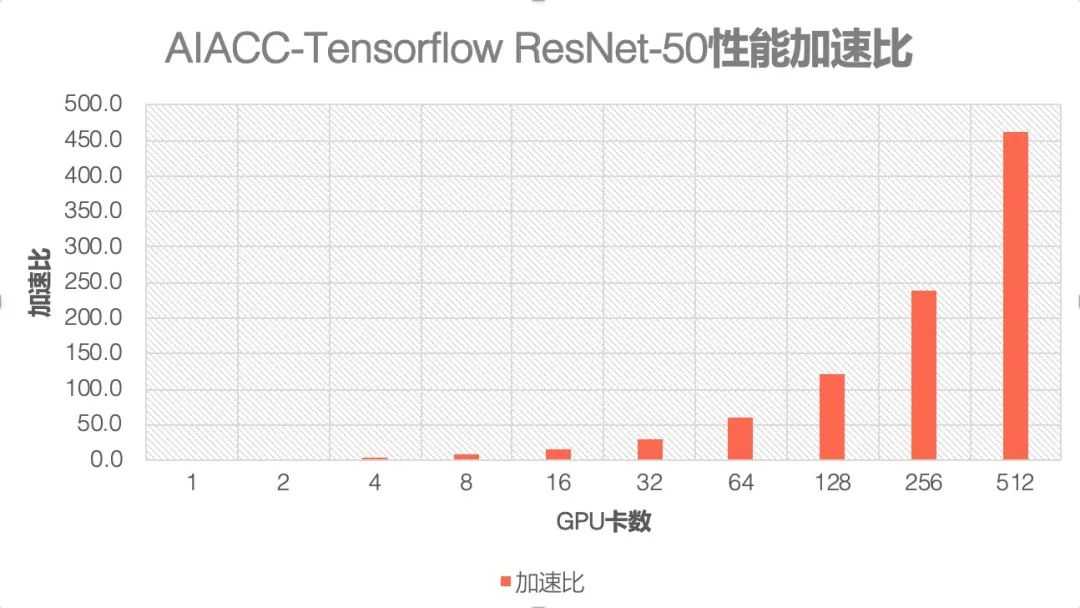
经过这些性能优化工作,我们也小试牛刀,训练上述大厂的 ResNet-50 模型 +ImageNet 数据集的任务,在 512 张 P100 上的性能比单卡性能能够加速 462 倍,基本上达到了接近线性的加速比,将训练时间从原来的 5 天时间缩短到了 16 分钟。
这次 DWANBench 打榜,我们也发布了基于 V100 的大规模训练时间,训练达到 top5 的 93% 的精度只需要 2 分 38 秒。
而我们另一个架构升级 FastGPU 即刻构建主要帮助用户快速搭建大规模分布式训练集群,并且帮助客户在云端做到业务成本最优化,接下来和大家介绍通过 FastGPU 即刻构建云端大规模分布式训练集群。
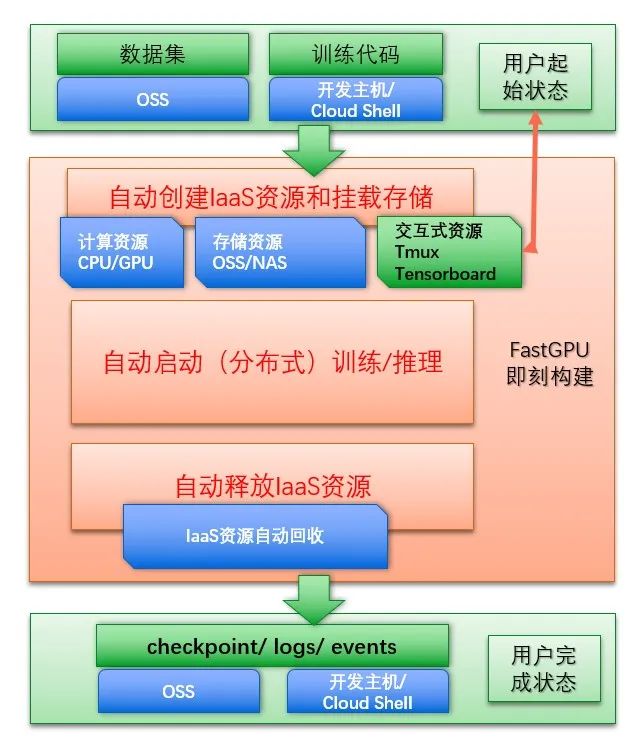
因为现在阿里云的云计算服务都会提供 OpenAPI 的接口直接创建计算资源、存储资源和网络资源。我们可以通过 FastGPU 来封装这些 OpenAPI 接口来直接创建出一个云端的大规模分布式的集群,同时可以开始大规模分布式的训练任务。
如上图所示,绿色部分代表用户,蓝色部分代表阿里云资源,橙色部分代表 FastGPU。用户在起始状态的时候,先把训练数据集上传到云存储 OSS 里,开一台 ECS 做为开发主机来存训练代码(或者放在 Cloud Shell 上)。然后在这台开发机上一键就可以通过 FastGPU 来创建深度学习应用需要的基础资源,包括大规模 GPU 计算资源、云盘和并行文件系统的存储资源、Tmux 和 Tensorboard 的交互式资源,都可以创建出来,用户可以通过交互式资源实时查看训练过程。
等训练所需要的资源都 ready 之后,就可以自动的启动分布式训练任务。当分布式训练任务结束之后,可以自动的释放这些基础资源,训练得到的模型和 log 文件可以存在 OSS 或者开发机上供用户使用。
首先是节省时间,举个例子,我们之前要配置一个分布式的深度学习环境的话,需要先准备 GPU 的基础资源、网络资源,再准备存储资源,然后需要配置每台机器的深度学习环境:包括某版本的操作系统、某版本的 GPU 驱动、某版本的 CUDA、某版本的 cuDNN、某版本的 Tensorflow 等,然后再把训练数据上传到每台机器上,然后再把多台机器之间的网络打通,这个可能要耗费一个工程师一天的时间来准备环境,而用 FastGPU 的话只需要 5 分钟的时间就可以完成。
其次是省钱,我们可以做到让 GPU 资源的生命周期和训练的生命周期保持同步,也就是说只有在我们的训练或者推理任务准备好时才去开启 GPU 资源,而当训练或者推理任务结束之后,就会自动的释放掉 GPU 的资源,不会造成 GPU 资源的闲置,同时也支持可抢占 GPU 实例(低价格实例)的创建和管理。
第三是易用,我们创建的所有的资源都是 IaaS(基础设施)的资源,所有创建的资源和运行的任务都是可访问、可调式、可复现和可回溯的。
在做大规模分布式训练的时候,我们希望训练的性能能够随着 GPU 数量的增长而线性增长,但是实际情况下往往达不到这么理想的加速比,甚至往往在增加 GPU 服务器时,性能却没有相应增加。
其中主要有两方面的瓶颈,一方面在多台 GPU 服务器同时读取训练文件的时候,文件系统的并行访问能力包括 IOPS 和带宽会是瓶颈;另外一方面,GPU 服务器之间的通信会是瓶颈。
在阿里云上可以一键创建高并发的并行文件系统 CPFS 解决文件高并发访问的问题,而通过 AIACC 来解决大规模分布式通信的性能问题。
最后,跟大家分享图像识别、大规模 CTR 预估、大规模人脸识别、大规模自然语言理解,这 4 个大规模深度学习场景的应用架构和性能优化的实践。
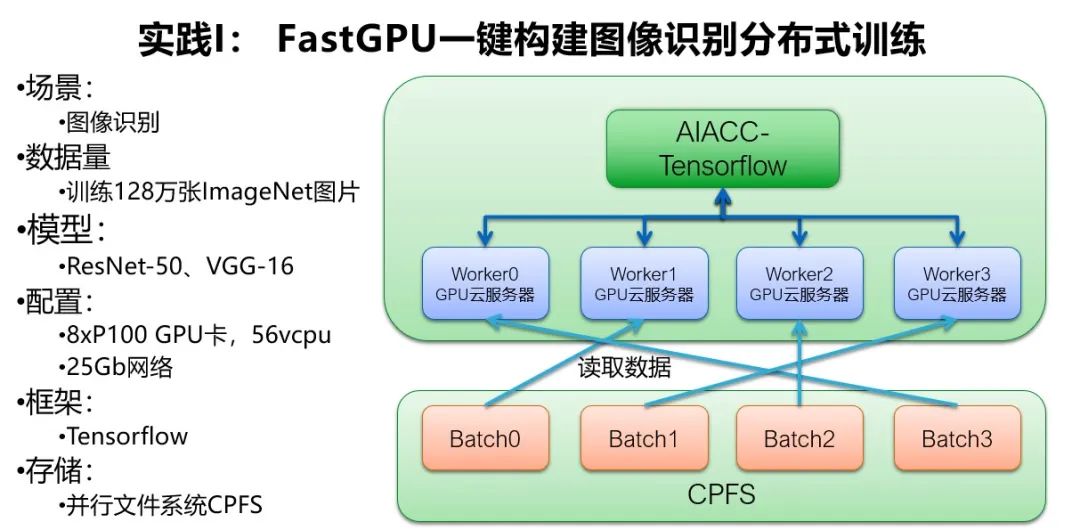
第 1 个案例是一键构建大规模图像识别的分布式训练任务。
这个场景需要训练 128 万张 ImageNet 的图片,模型是 ResNet-50 和 VGG-16,训练框架是 Tensorflow。
通过 FastGPU 一键拉起右边的架构,包括多台 8 卡 P100 的 GPU 服务器、25Gb 网络和并行文件系统 CPFS,并且通过 AIACC-Tensorflow 框架来做分布式训练。
多台 GPU 服务器上的 worker 会并行的做训练,并且并行的从 CPFS 上读取训练数据。CPFS 可以提供多台 GPU 服务器并行访问数据的聚合 IOPS 和聚合带宽,而 AIACC 可以让多 GPU 之间的通信能够达到性能最优。
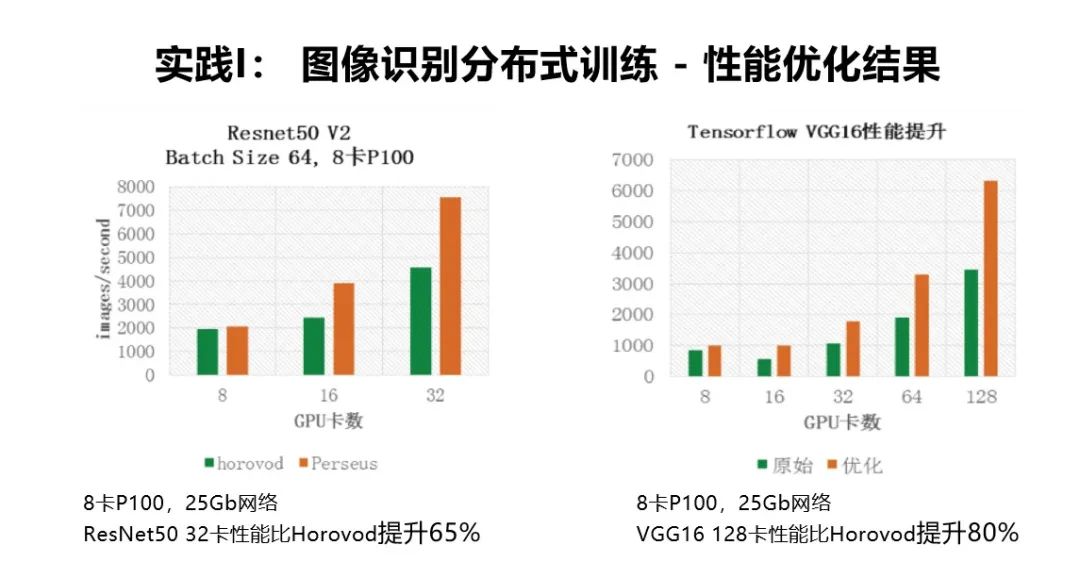
下图是大规模图像识别分布式训练性能优化的结果。Uber 开源的 Horovod 也是一个分布式训练优化的框架,主要做的是基于 ring-allreduce 环形通信的优化。它的分布式性能会比原生的 Tensorflow 和其他框架分布式性能要好。在我们这个案例里,基于 32 张 P100 的训练训练性能比 Horovod 的性能可以提升 65%,基于 128 张卡 P100 训练性能比 Horovod 提升 80%。
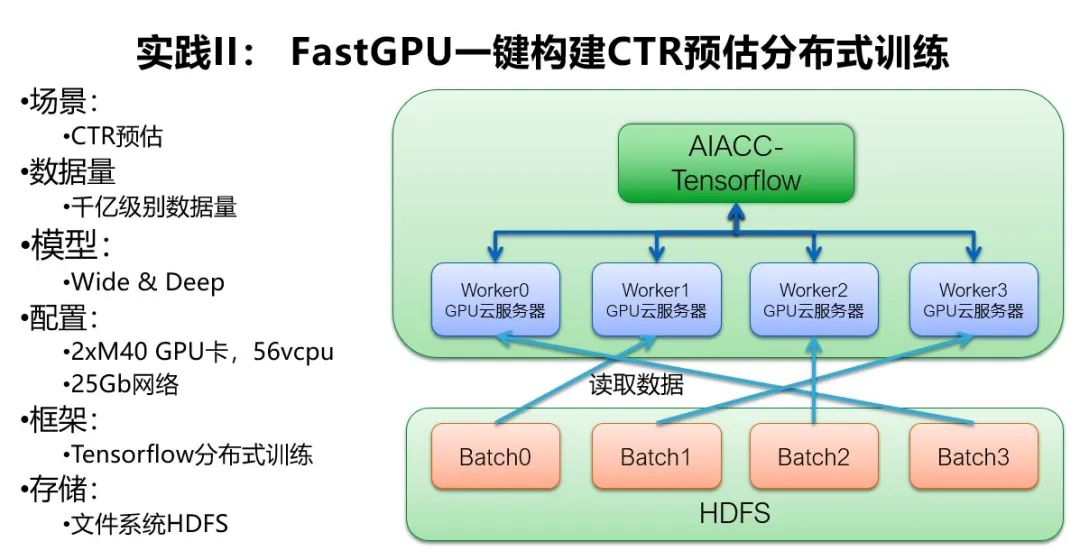
第 2 个案例是大规模 CTR 预估的分布式训练。
CTR 预估会根据每个人在网上的行为做千人千面的推荐,例如根据每个人的点击、停留、点赞、转发、购买等行为,推荐用户可能感兴趣的内容、商品或者广告。
这个案例需要训练的数据量有 1 千亿,它的模型是 Wide&Deep 的模型,用的分布式框架是 Tensorflow。
我们先通过 FastGPU 一键拉起架构,包括多台 2 卡 M40 的 GPU 服务器、10Gb 网络和文件系统 HDFS,并且通过 AIACC-Tensorflow 框架来做分布式训练。
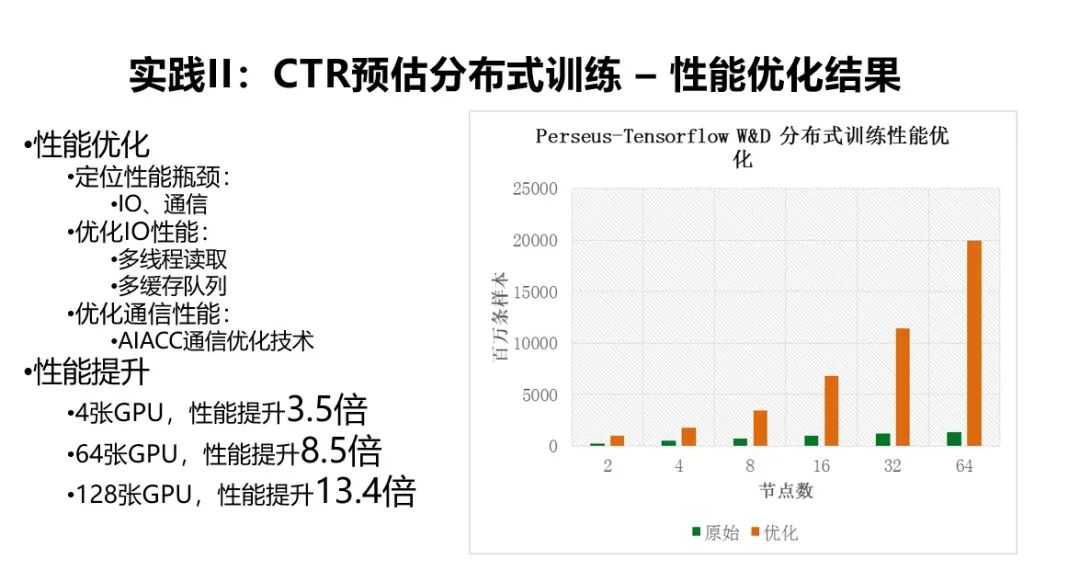
可右边这张图中,绿色的部分是原始 Tensorflow 的性能,随着节点数的增加并没有太多的性能加速,在 1 天内训练 1 千亿的数据量根本不可能。
我们定位了一下应用到性能瓶颈,瓶颈主要来自两个方面:一个方面是从 HDFS 上读取文件的 IO 瓶颈,另一个方面来自于多机之间的通信瓶颈。
我们通过多线程并行读取和多缓冲队列来优化文件的 IO,通过 AIACC 的通信优化技术来优化多机之间的通信性能。
最终我们在 4 张 GPU 卡上获得了 3.5 倍的性能提升,在 64 张 GPU 卡上获得了 8.5 倍的性能提升,在 128 张 GPU 卡上获得了 13.4 倍的性能提升,5 小时可以训练 1 千亿的数据量。
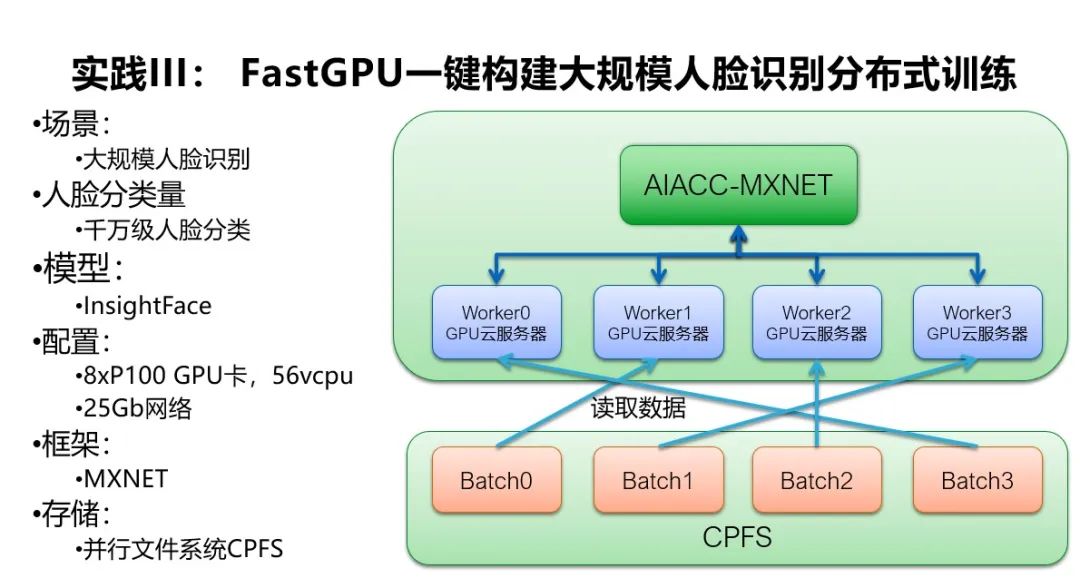
在人脸识别的场景下,分布式训练的复杂度会随着人脸识别的分类数的增加而增加,这个案例的人脸分类数达到了千万级人脸,模型是 InsightFace,计算框架式是 MXNET。
我们先用 FastGPU 一键拉起多台 8 卡 P100 的 GPU 服务器、25Gb 网络和并行文件系统 CPFS,并且用 AIACC-MXNET 来做分布式训练。
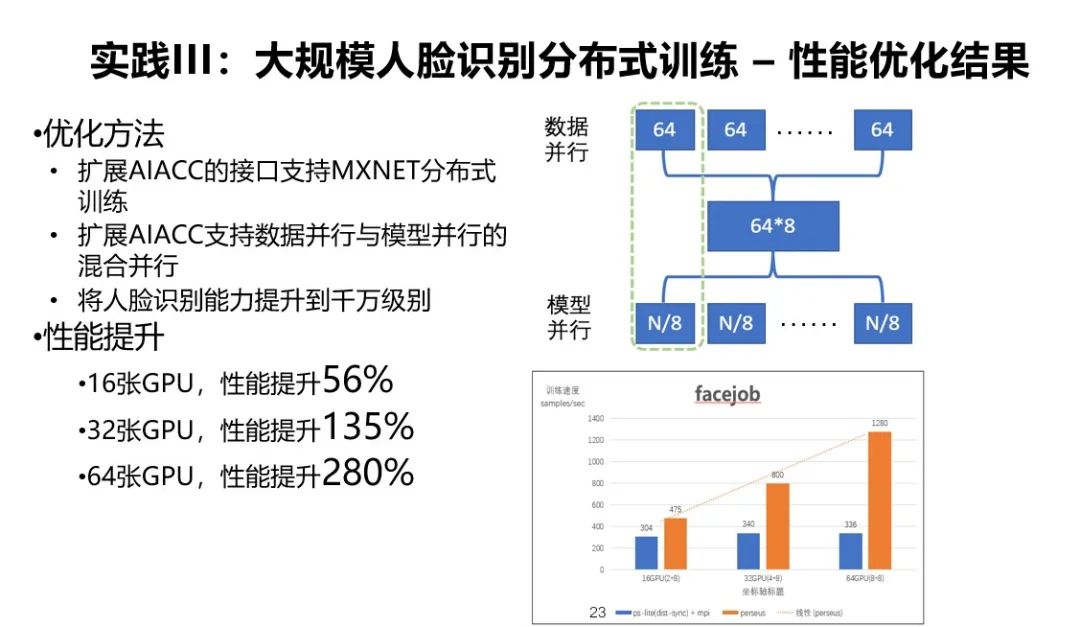
在千万级人脸分类的场景下没有办法做纯粹的数据并行,需要做数据并行和模型并行的混合并行。所以我们扩展了 AIACC 的接口,一方面支持 MXNET 的 kvstore 接口,一方面支持数据并行和模型并行的混合并行,这样通过 AIACC-MXNET 将人脸识别的能力提升到千万级别,最终在 16 张 GPU 卡上性能可以提升 56%,在 32 张 GPU 卡上性能可以提升 135%,在 64 张 GPU 卡上性能可以提升 280%。
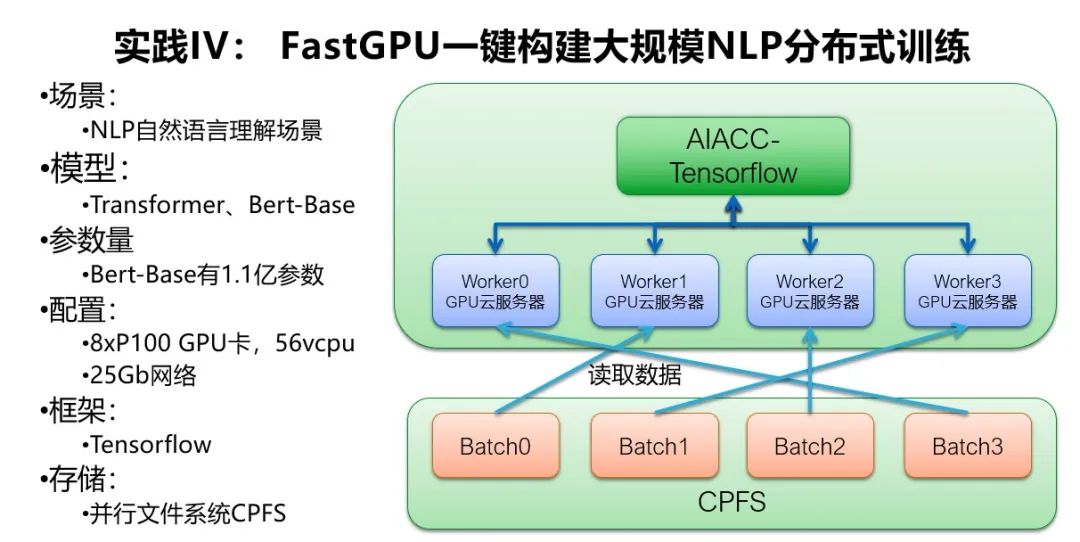
这个案例的模型有 Transformer 和 Bert 模型,其中 Bert 是 Google 开源的一个非常大的模型,在 NLP 的竞赛中取得了非常好的成绩。它有 1.1 亿个参数,对于分布式训练的加速比是一个非常大的挑战。我们通过 FastGPU 一键拉起多台 8 卡 P100 的 GPU 服务器、25Gb 网络和并行文件系统 CPFS,并且通过 AIACC-Tensorflow 来做分布式训练。
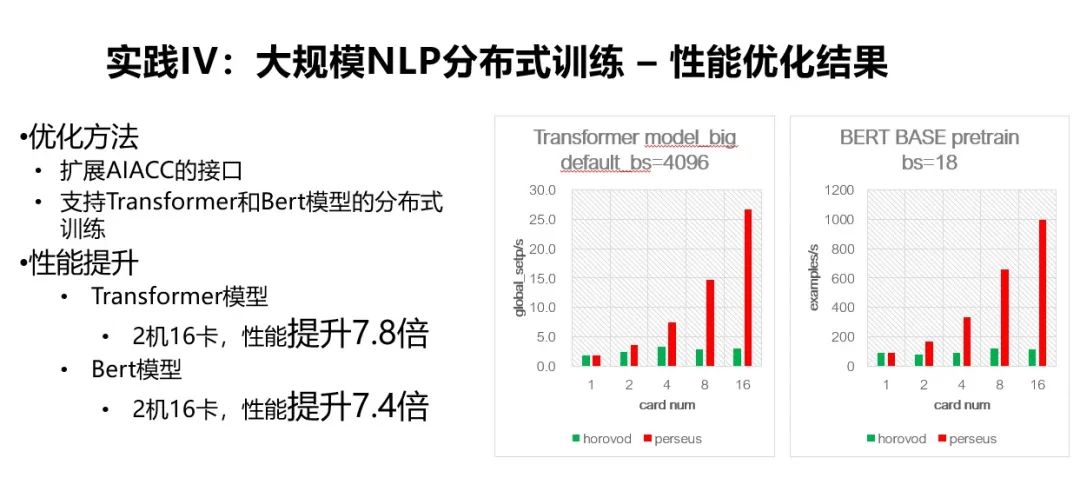
我们扩展了 AIACC 的接口来支持 Transformer 和 Bert 模型的分布式训练,最终 Transformer 模型在 16 张 GPU 卡上,取得了 7.8 倍的性能提升,Bert 模型在 16 张 GPU 卡上取得了 7.4 倍的性能提升。
FastGPU 一键部署和训练手势识别应用的源码:
https://github.com/aliyun/alibabacloud-aiacc-demo/tree/master/pytorch/gtc-demo
https://github.com/aliyun/alibabacloud-aiacc-demo/tree/master/mxnet/insightface
https://github.com/aliyun/alibabacloud-aiacc-demo/tree/master/tensorflow/bert