Learning Scrapy 中文版翻译 第二章
Posted 一张红枫叶
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Learning Scrapy 中文版翻译 第二章相关的知识,希望对你有一定的参考价值。
为了从网页中提取信息,你有必要对网页的结构做一些了解。我们将快速学习HMTL,html数状结构以及用XPath在网页上提取信息
HTML, DOM树结构以及XPath
让我们花一点时间来了解当用户在浏览器中输入了一个URL到屏幕上显示出页面的处理过程。从本书的角度来说,这个过程分为4步:
浏览器中输入URL。URL的第一部分(域名,比如gumtree.com)用来在网络中查找合适的服务器, URL和像cookie样的数据形成了一个发送到服务器的请求
服务器给浏览器发送HTML页面。值得注意的是服务器也有可能返回其他的格式,例如XML和JSON,但是现在我们聚焦于HTML
HTML在浏览器内部转化为树结构。文本对象模型(DOM)
数状结构根据布局规则转化成屏幕上可见的页面
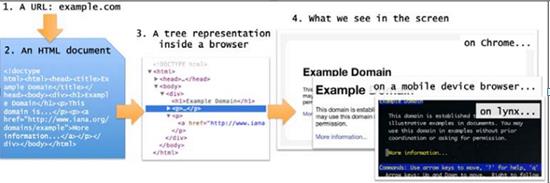
让我们来研究下这4个步骤以及树结构,这可以帮助我们定位要抓取的文本和编写爬虫程序
URL
URL主要有2个部分。第一部分帮助我们通过DNS在网上定位到正确的服务器。比如,当你给浏览器发送https://mail.google.com/mail/u/0/#inbox,浏览器产生一个mail.google.com.
DNS请求,用来解析一台服务器的IP例如173.194.71.83. 也就是说https://mail.google.com/mail/u/0/#inbox转换成了https://173.194.71.83/mail/u/0/#inbox.
URL剩下的部分对于服务器知道请求消息是关于什么的非常重要。它有可能是一个图片,一个文档,或者是需要触发一个动作比如在服务器上发送邮件。
HTML文档
服务器通过阅读URL知道了我们在请求什么,并且回复一个HTML文档。这个文档其实是一个文本文档我们可以用TextMate,Notepad,vi或者Emacs打开。和多数文本文档不一样的是,HTML文档遵守万维网的规定格式。这个格式超出了本书的范畴, 这里看一个简单的HTML页面,如果你打开http://example.com, 通过在浏览器中选择View Page Source,你将能看到对应的HTML文件。对于不同的浏览器来说这个过程也不一样;在许多系统中,通过右击鼠标能看到这个选项。
下面就是http://example.com/的HTML代码

我整理了这个HTML文档以便于阅读,但是你可以把正篇文档放在一行里。大多数情况下,空格和换行不会导致太大的影响
尖括号里面的字符称为标签(比如<html>或者<head>)。<html>是开始标签</html>是结束的标签。唯一不同的是/字符。标签总是成对的出现。有些网页对于结束标签的使用很随意(比如只是用一个<p>标签去分隔段落),但是浏览器都这种行为是容许的,并且能够智能的判断结束标签</p>应该在哪里。
介于<p>和</p>的称为HTML元素。值得注意的是元素里面可能含有其他元素,比如例子中的<div>标签,第二个标签是<p>里面包含了<a>元素。
有些标签比较复杂,比如<a href="http://www.iana.org/domains/example">。 带有url的href称为属性。
最后,很多元素都包含文本,比如在<h1>元素中的”Example Domain”
好消息是并不是所有的标记都对我们有用。唯一有用的是包含在<body>和</body>标签中的元素。<head>标签中为我们标明了编码方式,但是scrapy已经注意到了这些因素并且处理, 所以对这些部分,我们就不用浪费精力去处理了
树状结构:
每个浏览器都有自己内部的数据结构来呈现网页。DOM结构是跨平台且不依赖于语言的,并且不大多数的浏览器支持
在你感兴趣的元素上右击鼠标,选择查看元素,就可以在Chrome浏览器中查看树结构。如果这个功能不可用,你还可以通过点击Chrome菜单选择工具||开发工具也可以查看

你看到的和HTM结构很像,但是并不是完全一样的。它是HTML代码的树结构。无论原始HTML文件使用了多少空格和换行符,树结构看起来都是一样的。你可以在每个元素上点击查看或者操作元素,并且在屏幕上实时的观看这些变化带来的影响。比如,如果你双击文本,并且修改了它,然后按下Enter键,屏幕上的这段文字就会更新为新的值。在右边,在属性标签下,你能看到树结构的属性列表,在底部,可以看到一个面包屑路径,指示你选择的元素在页面中的位置。

重要的是需要记住,HMTL只是一段文本,树结构是浏览器内存中的一个对象,你可以通过程序来查看,修改。在Grome浏览器中,就是通过开发工具。
浏览器中的页面
HTML文本和树结构并不像我们在浏览器上看的那么优雅。这也是HTML成功的一个原因,HTML是供人们阅读的文本,可以区分文本内容,但并不是呈现在浏览器上的方式。这就意味着呈现和美化是浏览器该做的事。无论是对于功能齐备的Chrome、移动端浏览器、还是Lynx这样的文本浏览器
也就是说,网页的发展对网页开发者和用户都提出了极大的开发网页方面的需求。因此CSS就被创造出来用于如何展示HTML元素。对于Scrapy,我们并不需要CSS
那么,树结构是如何映射成我们在浏览器看到的样子?答案是依赖于盒模型。就像DOM树可以包含元素和文本,同样的方式,当展示在浏览器的时候,盒模型也包含其他内容。也就是说,我们看到的网页是HTML的二维呈现。树结构是其中的一维,在下面的图片中,我们可以看到3个DOM元素----一个<div>和2个内嵌的元素<h1>和<p>是如何分别呈现在浏览器和DOM中的

用XPATH选择HTML元素
如果你是个传统的软件工程师并且对XPATH一无所知,你可能会担忧,为了获取HTML的信息,必须去做很多的字符匹配,搜索标签,处理异常等等,或者解析整个树结构得到你想要的。好消息是这些都不是必须的。你可以用XPATH来选取,提取元素,属性和文本
为了在Google浏览器中使用XPATH,在开发工具中点击控制台并且使用$x方法。比如你可以在http://example.com/中尝试$x(‘//h1’). 浏览器就会移动到<h1>元素,就像下面图片显示的一样

你在控制台上看到的返回值是一个包含所选元素的javascript数组。如果你将你的鼠标放在这些变量上,所选元素将在浏览器中高亮。
有用的XPATH表达式
HTML文档的层级结构最高级是<html>标签。你可以使用元素和斜线来选择文档中的元素。比如下面展示的就是各种不同表达式从http://example.com/page中返回的内容

请注意因为在这个页面中<div>中有2个<p>元素,html/body/div/p返回2个元素。你可以使用p[1]和p[2]去分别使用第一个和第二个元素
从抓取的角度来看,文档的标题也许是唯一有趣的元素,它位于文档的头部,并且可以通过如下的表达式进行访问

对于大文档来说,有可能写非常负责的XPATH表达式才能得到特定的元素。为了避免复杂的表达式,//允许你得到特定类型的所有元素,而不管它们在文档的位置。比如,//p将会选出所有的p元素,//a得到所有的链接。

//a表达式可以用在文档结构的任何位置。比如,找到在div下的所有链接,你可以采用//div//a。请注意,//div/a一个反斜杠的方式有可能得到一个空的队列,因为在example.com中没有一个a元素是直接位于div下面的。

你还可以选择属性。http://example.com中的唯一属性是链接,可以用字符@按照下面的方式来访问
$x(\'//a/@href\')
[ href="http://www.iana.org/domains/example" ]
提示:
在最近的chrome版本中,@href不会返回URL而只是一个空的字符串。不用担心,你的XPATH表达式依然是正确的
你可以用text()函数来选择文本。
$x(\'//a/text()\')
[ "More information…" ]
你可以使用*符号来选择特定层次下的所有元素。比如:
$x(\'//div/*\')
[ <h1>Example Domain</h1>, <p>...</p>, <p>...</p> ]
在查找特定的属性的元素比如@class, 或者特殊值作为属性的时候,你会发现XPATH非常的好用。你可以使用比之前p[1]和p[2]这种数字索引方式更加更加的方式。
比如//a[@href]选择所有包含href属性的链接。并且//a[@href="http://www.iana.org/domains/example"]选择了属性href是特定值的链接。
更加有用的是能够找到href属性是某个字符串开始或是包含某个字符串的链接。下面是一些使用样例
$x(\'//a[@href]\')
[ <a href="http://www.iana.org/domains/example">More information…</a> ]
$x(\'//a[@href="http://www.iana.org/domains/example"]\')
[ <a href="http://www.iana.org/domains/example">More information…</a> ]
$x(\'//a[contains(@href, "iana")]\')
[ <a href="http://www.iana.org/domains/example">More information…</a> ]
$x(\'//a[starts-with(@href, "http://www.")]\')
[ <a href="http://www.iana.org/domains/example">More information…</a>]
$x(\'//a[not(contains(@href, "abc"))]\')
[ <a href="http://www.iana.org/domains/example">More information…</a>]
在在线的文档上面,有许多像not(),contains(),和starts-with()这样的XPATH函数
(http://www.w3schools.com/xsl/xpath_functions.asp), 但即使不使用大多数的函数,你也一样可以能完成很多实现
在Scrapy Shell中同样可以使用XPATH表达式。打开一个网页并且进入Scrapy Shell, 打印如下的命令:
scrapy shell http://example.com
终端将会向你展示很多在使用爬虫的时候使用到的变量。其中最重要的是响应,在HTML文档中是HtmlResponse。这个类将允许你在chrome中使用xpath方法$x。下面是些例子:
response.xpath(\'/html\').extract()
[u\'<html><head><title>...</body></html>\']
response.xpath(\'/html/body/div/h1\').extract()
[u\'<h1>Example Domain</h1>\']
response.xpath(\'/html/body/div/p\').extract()
[u\'<p>This domain… permission.</p>\', u\'<p><a
href="http://www.iana.org/domains/example">More information…</a></p>\']
response.xpath(\'//html/head/title\').extract()
[u\'<title>Example Domain</title>\']
response.xpath(\'//a\').extract()
[u\'<a href="http://www.iana.org/domains/example">More information…</a>\']
response.xpath(\'//a/@href\').extract()
[u\'http://www.iana.org/domains/example\']
response.xpath(\'//a/text()\').extract()
[u\'More information…\']
response.xpath(\'//a[starts-with(@href, "http://www.")]\').extract()
[u\'<a href="http://www.iana.org/domains/example">More information…</a>\']
这意味着你可以使用Chrome来生成XPATH表达式。并且在下一章中将会看到我们应用于Scrapy爬虫中。
使用Chrome得到XPATH表达式:
Chrome可以给我们提供基本的XPATH表达式,这点对于开发者来说非常的友好。想之前演示的那样:右键点击需要的元素,然后选择Inspect Element。这将会打开开发工具并且HTML元素将在树结构中被高亮。现在右键点击这个元素,然后从菜单中选择Copy XPath; XPATH表达式将会被复制进剪贴板。

你可以从控制台上检测表达式
$x(\'/html/body/div/p[2]/a\')
[ <a href="http://www.iana.org/domains/example">More information…</a>]
常见工作:
下面展示一些你可能会经常会用到的XPATH表达式。让我们来看下在维基页面上是如何使用的例子。维基的页面非常稳定,所以不用担心在短期内改变排版,虽然最终他们会。
取得div下span且id为” firstHeading”的文本:
//h1[@id="firstHeading"]/span/text()
取得属性id=”toc”的div下ul内所有链接的URL
//div[@id="toc"]/ul//a/@href
在任意class包含”ltr”并且包含”skin-vecotr”的元素内,取得h1的text, 这两个字符串有可能在同一个class内,也许不是
//*[contains(@class,"ltr") and contains(@class,"skinvector")]//
h1//text()
在实战中,你将会频繁的在XPATH表达式中用到class。在这些例子中,你应该记住因为CSS的板式原因,你将会看到HTML元素将会包含很多class元素。这意味着,有的<div>的class是link,其他导航栏的<div>的class就是link active。后者是当前生效的链接,因此是可见或是用CSS特殊色高亮显示的。当抓取的时候,你通常是对含有某个属性的元素感兴趣的,就像之前的link和link active。XPath的contains( )函数就可以帮你选择包含某一class的所有元素。
- 选择class属性是infobox的table的第一张图片的URL:
//table[@class="infobox"]//img[1]/@src
- 选择class属性是reflist开头的div下面的所有URL链接:
//div[starts-with(@class,"reflist")]//a/@href
- 选择div下面的所有URL链接,并且这个div的下一个相邻元素的子元素包含文字References:
/*[text()="References"]/../following-sibling::div//a
- 取得所有图片的URL:
//img/@src
提前准备页面变化:
爬取的目标网页通常都位于脱离我们控制的远程服务器。这意味着如果HTML页面改变了,对应的XPATH表达式也就不可用了。我们不得不回到爬虫去修改它们。但这也不会耗时太久,因为通常都是些小改动。虽然如此,我们还是期望这些事情可以避免。一些基本的原则可以帮助我们降低表达式失效的概率。
避免使用数组序号
Chrome常常会在表达式中加入许多常数
//*[@id="myid"]/div/div/div[1]/div[2]/div/div[1]/div[1]/a/img
这种表达式非常的脆弱,如果HTML上有一个广告窗的话,就会改变文档的结构,这个表达式就会失效。解决的方法是,尽量找到离img标签近的元素,根据该元素的id或class属性,进行抓取,例如:
//div[@class="thumbnail"]/a/img
使用class抓取的效果不一定好
使用class属性可以方便的定位要抓取的元素,但是因为CSS也要通过class修改页面的外观,所以class属性可能会发生改变,例如下面用到的class:
//div[@class="thumbnail"]/a/img
过一段时间之后,可能会变成:
//div[@class="preview green"]/a/img
数据指向的class优于排版指向的class
在上一个例子中,使用thumbnail和green两个class都不好。thumbnail比green好,但这两个都不如departure-time。前面两个是用来排版的,departure-time是有语义的,和div中的内容有关。所以,在排版发生改变的情况下,departure-time发生改变的可能性会比较小。应该说,网站作者在开发中十分清楚,为内容设置有意义的、一致的标记,可以让开发过程收益。
ID通常都比较可靠
只要id具有语义并且数据相关,id通常是抓取时最好的选择。部分原因是,JavaScript和外链锚点总是使用id获取文档中特定的部分。例如,下面的XPath非常可靠:
//*[@id="more_info"]//text()
相反的例子是,指向唯一参考的id,对抓取没什么帮助,因为抓取总是希望能够获取具有某个特点的所有信息。例如:
//[@id="order-F4982322"]
这是一个非常差的XPath表达式。还要记住,尽管id最好要有某种特点,但在许多HTML文档中,id都很杂乱无章。
总结:
由于编程的不断进化,使得通过创建XPATH表达式从HTML抓取信息变得越来越容易。在这一章节中,你学到了基本的HTML文档和XPATH表达式。你学会了如何使用Chrome浏览器来得到XPATH表达式。你还学会了如何手动写XPATH表达式来获取HTML元素,并且还学会了识别了健壮性强的XPATH和健壮性差的XPATH。我们将在下一章中使用这些知识在Scrapy中来实现第一个爬虫。
以上是关于Learning Scrapy 中文版翻译 第二章的主要内容,如果未能解决你的问题,请参考以下文章
《learning laravel》翻译第三章-----搭建我们第一个网站
课程三(Structuring Machine Learning Projects),第二周(ML strategy) —— 0.Learning Goals
Learning Scrapy:《精通Python爬虫框架Scrapy》Windows环境搭建
[翻译]Learning Deep Features for Discriminative Localization
求Deep learning 【Yann LeCun 1,2 , Yoshua Bengio 3 & Geoffrey Hinton 4,5】全文中文翻译