深入分析HashMap
Posted wangweiminll
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深入分析HashMap相关的知识,希望对你有一定的参考价值。
本文基于jdk1.8
HashMap特点:
HashMap具体方法分析:
put方法分析:
执行流程图:
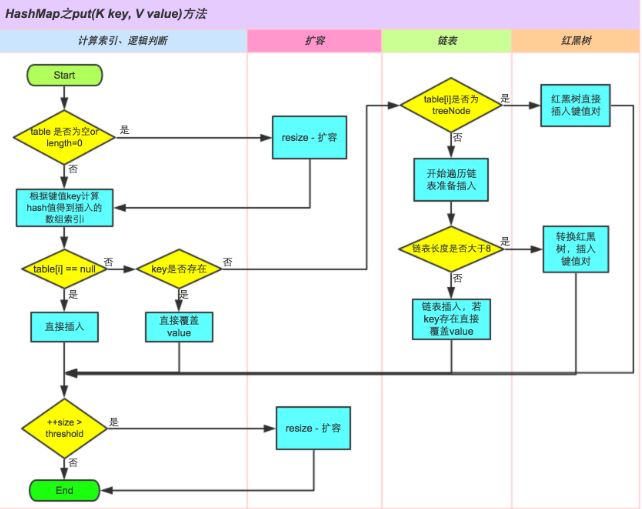
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
/**
* Implements Map.put and related methods
*
* @param hash hash for key
* @param key the key
* @param value the value to put
* @param onlyIfAbsent if true, don\'t change existing value
* @param evict if false, the table is in creation mode.
* @return previous value, or null if none
*/
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
//如果链表数组为空或者长度为0,则扩容·
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
//根据hash值找到要插入元素的位置i,若tab[i]为空,则直接插入元素
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
//如果tab[i]链表第一个元素与要插入的元素相等,则直接覆盖
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
//如果tab[i]链表第一个元素与要插入的元素不相等,且第一个元素为树节点,则把要插入的节点插入到红黑树中
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
//如果不是上两种情况,则依次与链表剩下的元素进行比较,若找到key值相同的元素则覆盖,否则在链表尾部插入新节点
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
//如果链表长度大于8,则将链表转换成红黑树
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;//将记录修改HashMap的modCount加1
//如果加入元素后size>threshold,则进行扩容
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
public V get(Object key) { Node<K,V> e; return (e = getNode(hash(key), key)) == null ? null : e.value; } /** * Implements Map.get and related methods * * @param hash hash for key * @param key the key * @return the node, or null if none */ final Node<K,V> getNode(int hash, Object key) { Node<K,V>[] tab; Node<K,V> first, e; int n; K k; //如果链表数组tab不为空,且长度不为0,且根据hash值所确定的tab[i]链表不为空,则进行判断 if ((tab = table) != null && (n = tab.length) > 0 && (first = tab[(n - 1) & hash]) != null) { //如果tab[i]链表的第一个元素就是要取的元素则返回 if (first.hash == hash && // always check first node ((k = first.key) == key || (key != null && key.equals(k)))) return first; if ((e = first.next) != null) { //如果要查找的元素不是链表的第一个元素,且第一个元素是树节点,则进入树中进行查找 if (first instanceof TreeNode) return ((TreeNode<K,V>)first).getTreeNode(hash, key); //如果不是上两种情况,则在剩下的链表结点进行查找 do { if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) return e; } while ((e = e.next) != null); } } return null; }
1 public V remove(Object key) { 2 Node<K,V> e; 3 return (e = removeNode(hash(key), key, null, false, true)) == null ? 4 null : e.value; 5 } 6 7 /** 8 * Implements Map.remove and related methods 9 * 10 * @param hash hash for key 11 * @param key the key 12 * @param value the value to match if matchValue, else ignored 13 * @param matchValue if true only remove if value is equal 14 // matchValue 作用:区别remove(Key key)与remove(Key key,Value value) 如果matchValue为false,remove(Key key)则删除与key值相等的节点,否则不删除 15 * @param movable if false do not move other nodes while removing 16 * @return the node, or null if none 17 */ 18 final Node<K,V> removeNode(int hash, Object key, Object value, 19 boolean matchValue, boolean movable) { 20 Node<K,V>[] tab; Node<K,V> p; int n, index; 21 //这几组语句在于查找要删除的节点,与get方法类似 22 if ((tab = table) != null && (n = tab.length) > 0 && 23 (p = tab[index = (n - 1) & hash]) != null) { 24 Node<K,V> node = null, e; K k; V v; 25 if (p.hash == hash && 26 ((k = p.key) == key || (key != null && key.equals(k)))) 27 node = p; 28 else if ((e = p.next) != null) { 29 if (p instanceof TreeNode) 30 node = ((TreeNode<K,V>)p).getTreeNode(hash, key); 31 else { 32 do { 33 if (e.hash == hash && 34 ((k = e.key) == key || 35 (key != null && key.equals(k)))) { 36 node = e; 37 break; 38 } 39 p = e; 40 } while ((e = e.next) != null); 41 } 42 } 43 //metchValue的作用,删除操作 44 if (node != null && (!matchValue || (v = node.value) == value || 45 (value != null && value.equals(v)))) { 46 if (node instanceof TreeNode) 47 ((TreeNode<K,V>)node).removeTreeNode(this, tab, movable); 48 else if (node == p) 49 tab[index] = node.next; 50 else 51 p.next = node.next; 52 ++modCount;//将记录修改HashMap的值加1 53 --size; 54 afterNodeRemoval(node); 55 return node; 56 } 57 } 58 return null; 59 } 60
hash()算法分析:
源码:
1 static final int hash(Object key) { 2 int h; 3 return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16); 4 }
一个较好的hash算法就是让所有的对象中的值都体现用处,hashCode()已经满足了这点,而我们在hashCode()的基础上设置新的hash算法时也要体现这一点,如何体现这一点,就是充分利用hashCode()的结果的所有位。
HashMap中的hash()方法中,hash值为,key的hashCode值与将其无符号右移16位后进行异或运算。作用:key的hashCode所有位都参与了运算,降低了节点碰撞率。
而用hash值与链表数组的长度-1进行相与获得节点的索引值,这样得到的结果与用hash值除以链表数组长度(取模运算)所得到的结果是一样的,并且与运算性能更高,前提是数组的长度必须是2的n次方。只有在这种情况下,取模运算才能转化位为与运算。
更新:看过别的博主对hash算法的分析,他们都是从验证,从举例的角度来论述hash算法的优劣。在《算法4》中,确定哈希表中各节点的位置,用的是取模运算。对于取模运算,各个节点落到各个桶的位置是等概率的(当然前提是各个节点的取值也是随机的,等概率的),HashMap中实现的hash算法(与数组的长度-1进行与运算,)本质上也是取模运算。
例子:对于长度为16的数组,数组长度减一的二进制序列为0000 0000 0000 0000 0000 0000 0000 1111,用它和一个数值进行与运算作用和取模运算是异曲同工,唯一不同的是1,取模运算时用的是key的hashCode值,进行与运算时先将keyCode值的高低16位进行异或运算,用其结果进行进行与运算,这样key的hashCode的所有位的信息又得到了运用。符合优秀哈希算法的规则。
HashMap与Hashtable的比较:
HashMap的使用场景:
以上是关于深入分析HashMap的主要内容,如果未能解决你的问题,请参考以下文章