Spark程序本地运行
Posted csguo
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark程序本地运行相关的知识,希望对你有一定的参考价值。
本次安装是在JDK安装完成的基础上进行的! SPARK版本和hadoop版本必须对应!!!
spark是基于hadoop运算的,两者有依赖关系,见下图:

前言:
1.环境变量配置:
1.1 打开“控制面板”选项
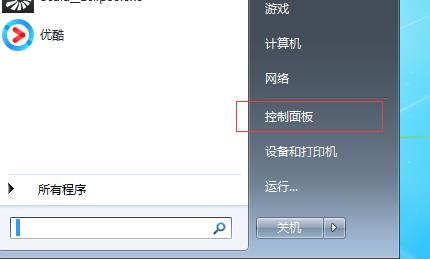
1.2.找到“系统”选项卡
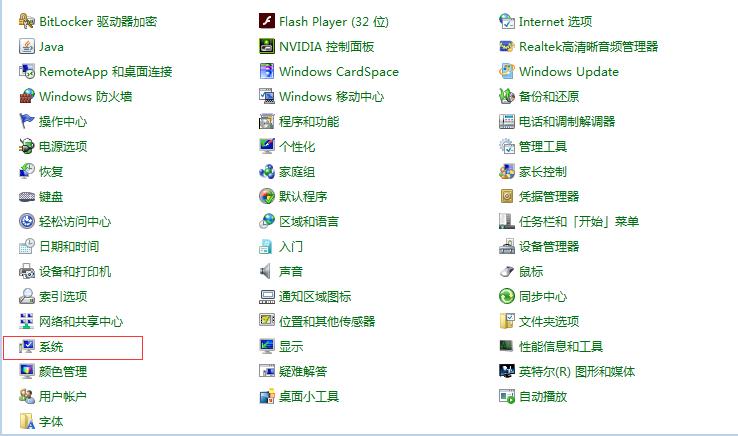
1.3.点击“高级系统设置”
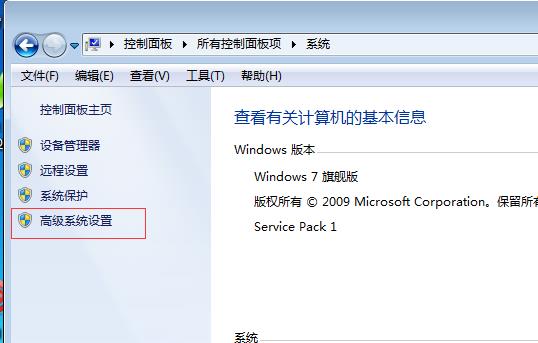
1.4.点击“环境变量”
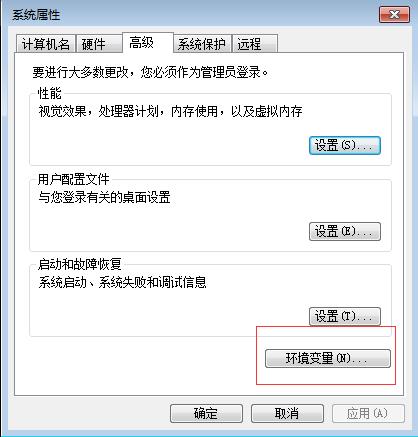
2.新建和编辑环境变量
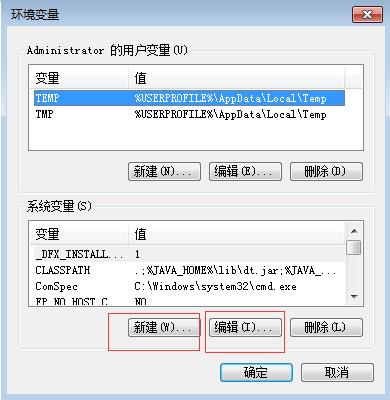
1.下载hadoop-2.6.0.tar.gz文件,并解压在本地
1.1 新建环境变量上配置
HADOOP_HOME D:\\JAVA\\hadoop
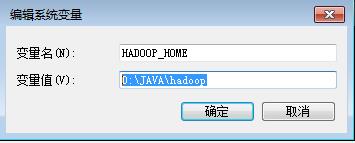
1.2 修改PATH路径
$HADOOP_HOME/bin;
2.下载scala-2.10.6.zip文件,并解压在本地
2.1 新建环境变量上配置
SCALA_HOME
D:\\JAVA\\scala

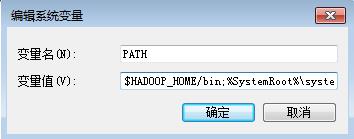
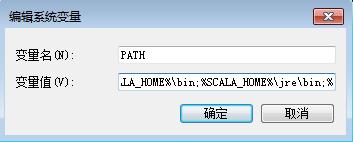
2.2 修改PATH路径
%SCALA_HOME%\\bin;%SCALA_HOME%\\jre\\bin;
3.下载spark-1.6.2-bin-hadoop2.6.tgz文件,并解压在本地
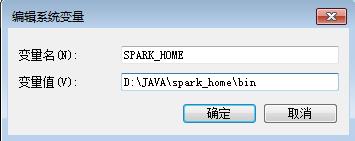
3.1 新建环境变量上配置
SPARK_HOME
D:\\JAVA\\spark_home\\bin
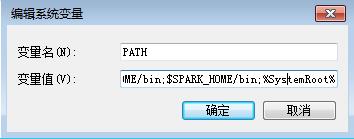
3.2 修改PATH路径
PATH $SPARK_HOME/bin;
4.下载scala-IDE.zip文件,并解压在本地
新建一个工程,修改library:

Scala library一定要是:2.10.X
新建一个自己的library:添加一个Jar文件(${spark_home}/lib)


下跟Word Count代码


package com
import org.apache.spark.SparkConf
import org.apache.spark.api.java.JavaSparkContext
import org.apache.spark.SparkContext
/**
* 统计字符出现次数
*/
object WordCount {
def main(args: Array[String]): Unit = {
System.setProperty("hadoop.home.dir", "D:\\\\JAVA\\\\hadoop");
val sc = new SparkContext("local", "My App")
val line = sc.textFile("/srv/1.txt")
line.map((_, 1)).reduceByKey(_+_).collect().foreach(println)
sc.stop()
println(111111)
}
}
hadoop下载点击这里
spark下载点击这里
scala安装包,scala IDE下载点击这里